概述
在 solidity 的 gas 优化过程中,我们常会遇到一些复杂的数学计算,这些复杂的数学计算在 solidity 中实现往往是困难的且极其消耗 gas 的,本文将给出一系列通用的数学方法以实现使用多项式逼近复杂数学公式,并给出对应的相关代码。
考虑以下数学公式:
$$ f(x) = e^{-x^2} $$
上述数学公式对应的图像如下:
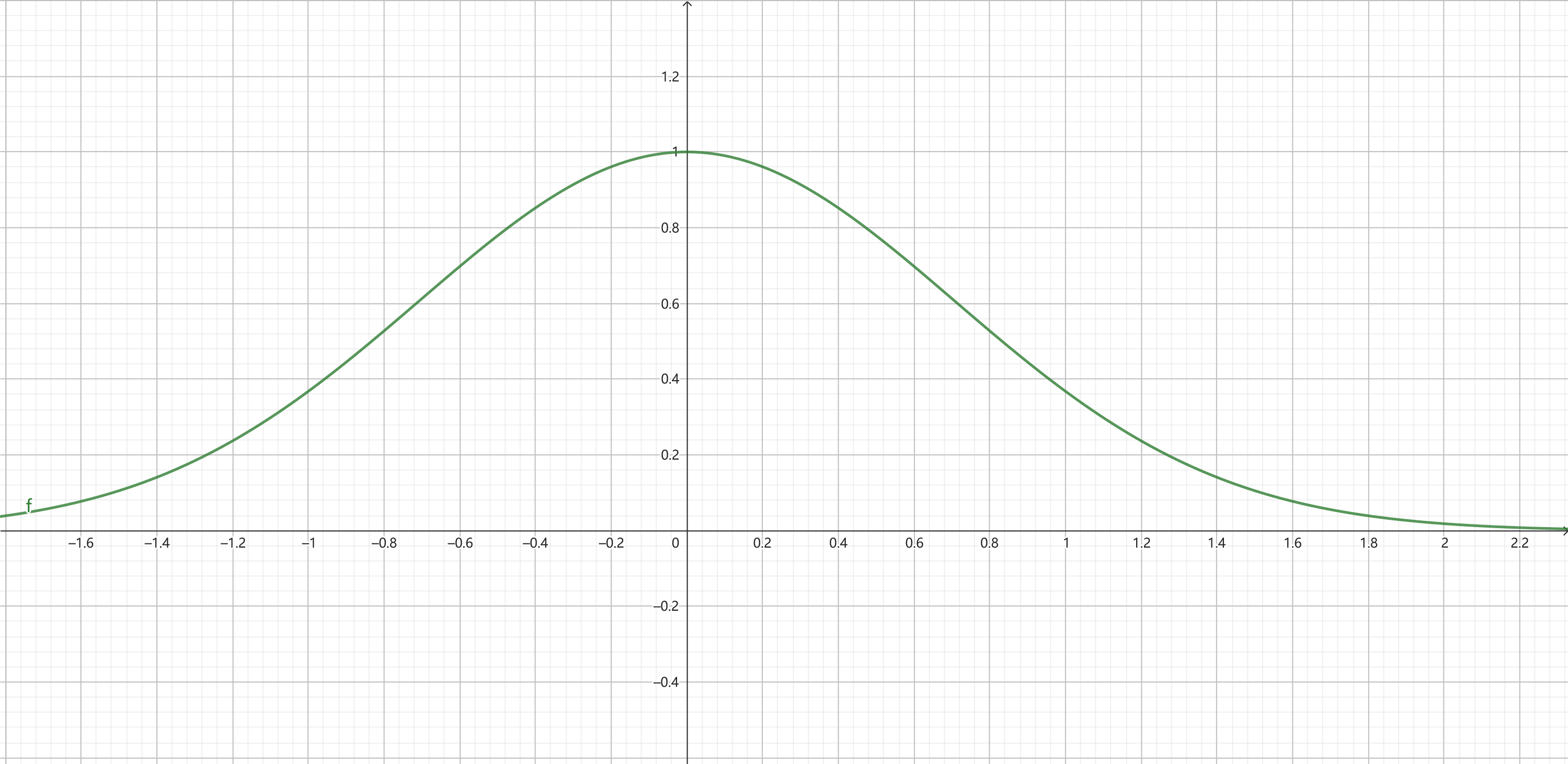
该函数是 $f(x)={\frac {1}{\sigma {\sqrt {2\pi }}}}e^{-{\frac {1}{2}}\left({\frac {x-\mu }{\sigma }}\right)^{2}}$ 正态分布构成部分。
本文参考 Approximation theory 文章的理论部分,但是笔者给出了所有多项式计算方法的 sagemath 代码以方便用户将其投入实战。
事实上,本文内的大量内容都属于数值计算这一传统的数学学科。
前置准备
本文将涉及一系列高等数学的相关内容,但本文并不会深入讨论其数学原理,而侧重于实战。为了更加工程化的讨论以下问题,希望读者安装 numpy 工具以及 matplotlib 等 python 库。如果读者感兴趣,也可以安装大名鼎鼎的代数学计算工具 sagemath。在本文中,核心部分没有使用 sagemath,且 sagemath 较为笨重,读者可以考虑不安装。读者也可以选装 scipy 科学计算工具。
由于本文涉及到部分偏僻算法,这些算法在数值计算领域的是常见的,但是在普通的开发领域则较为少见,为了方便用户使用这些算法,请读者安装 sollya 工具,对于 Ubuntu 用户而言,可以使用以下命令安装:
apt install sollya
接下来,我们需要规范化我们的目标,如果只是将 $f(x) = e^{-x^2}$ 转化为多项式形式过于宽泛,而不够精确。
我们希望展开后的多项式与 $f(x) = e^{-x^2}$ 仅有 1e-6 数量级的差距(即精度要保持在 6 位小数以上)。观察 $f(x) = e^{-x^2}$ 函数,我们可以发现此函数在趋向无穷大和无穷小时函数值都倾向于 0 ,所以此处我们可以简化需要讨论的空间。简单计算可知,当 $|x| = 4$ 时,此时计算出的结果为 $e^(-16)$ ,此值已经小于 1e-6 ,所以我们只需要讨论 $[-4, 4]$ 的区间,而此区间外的值都可以直接记为 0。
$$ f(x) = \begin{cases} 0 & x \ge 4 \\ p(x) & -4 < x < 4 \\ 0 & x \le -4 \end{cases} $$
此处我们一并给出上述问题的数学表述:
$$ \underset{p}{arg,min} \max|f(x) - p(x)| $$
上述公式的含义为寻找 $p$ 函数使 $|f(x) - p(x)|$ 的最大误差为最小状态。理论上,可以通过求解上述公式获取最佳的 $p$ 函数。事实上,该操作即为困难,本文的目标只是为了使 $p(x)$ 满足以下不等式:
$$ \max|f(x) - p(x)| \le 10^{-6} $$
由于 $f(x) = e^{-x^2}$ 为偶函数,我们只需要要求上述式子在 $[0, 4]$ 范围成立即可。
泰勒展开
当我们遇到复杂函数转化为多项式任务时,我们首先想到的是在高等数学最初阶段就已给出的经典的 泰勒展开 方法。
一个复杂函数对应的泰勒展开可以使用以下公式计算:
$$ f(a)+{\frac {f^{\prime}(a)}{1!}}(x-a)+{\frac {f^{\prime \prime}(a)}{2!}}(x-a)^{2}+{\frac {f^{\prime \prime \prime}(a)}{3!}}(x-a)^{3}+\cdots $$
打开 sagemath 的终端,使用以下命令进行计算:
sage: var('x')
x
sage: fx = e^(-x^2)
sage: fx.taylor(x, 0, 8)
1/24*x^8 - 1/6*x^6 + 1/2*x^4 - x^2 + 1
sagemath 软件计算获得 $f(x) = e^{-x^2}$ 的在 x=0 点处的 8 阶展开。此处的 fx.taylor(x, 0, 8) 中的第一个参数代表需要展开的变量,而第二个参数代表展开位置,此处为 0 ,而第三个参数调用展开的阶数。最后的展开结果如下:
$$ \frac{1}{24} x^{8} - \frac{1}{6} x^{6} + \frac{1}{2} x^{4} - x^{2} + 1 $$
此处选择在
x = 0处展开是为了保证展开形式的最简化,对于某些其他函数,从x = 0处展开不一定是最优解
将展开结果与原函数绘制在同一坐标系内,结果如下:
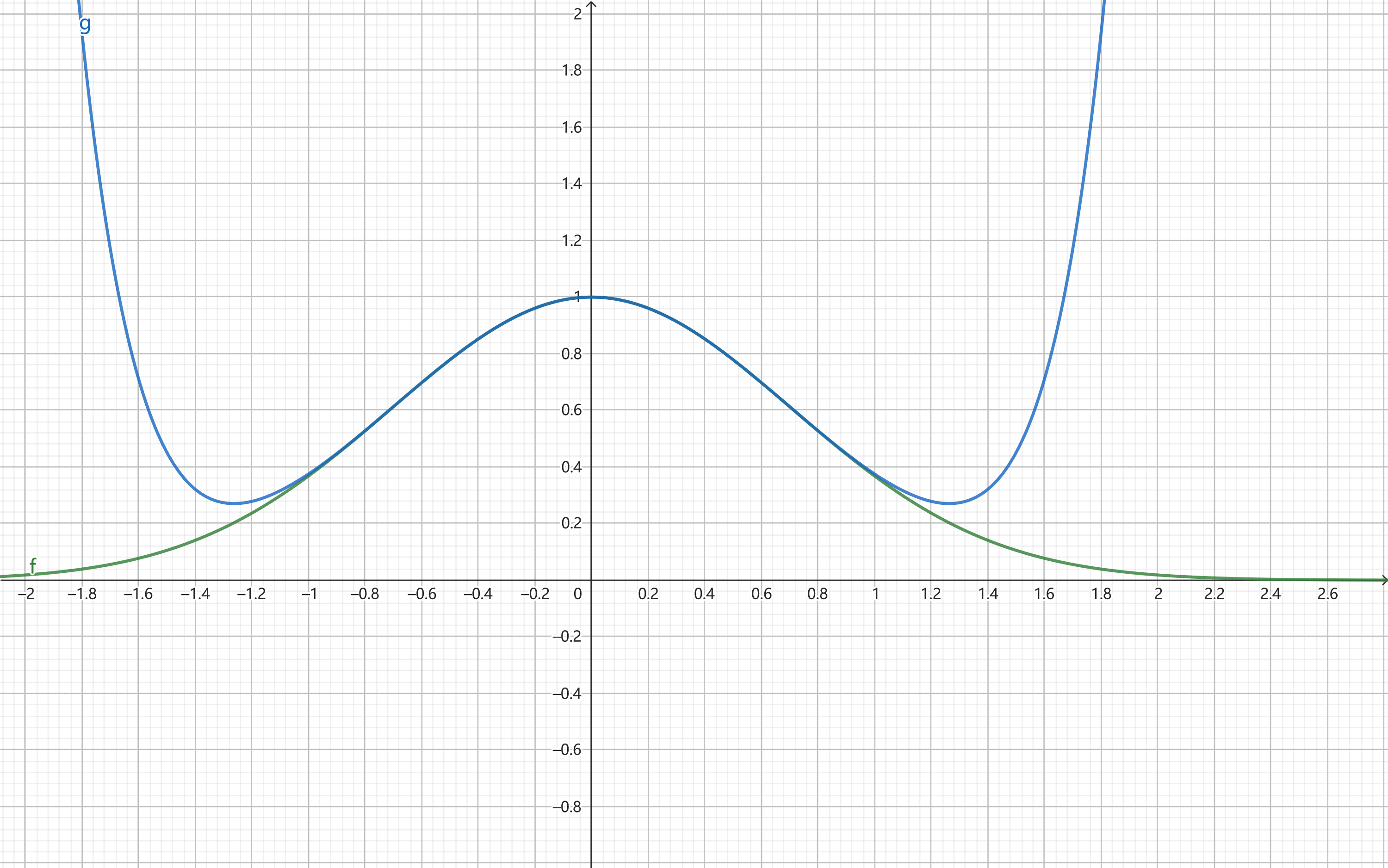
从上图来看,泰勒展开的结果并不是非常的完美,下图给出了 3、5、7 和 9 阶的泰勒展开与原函数(使用虚线表示)的图像:
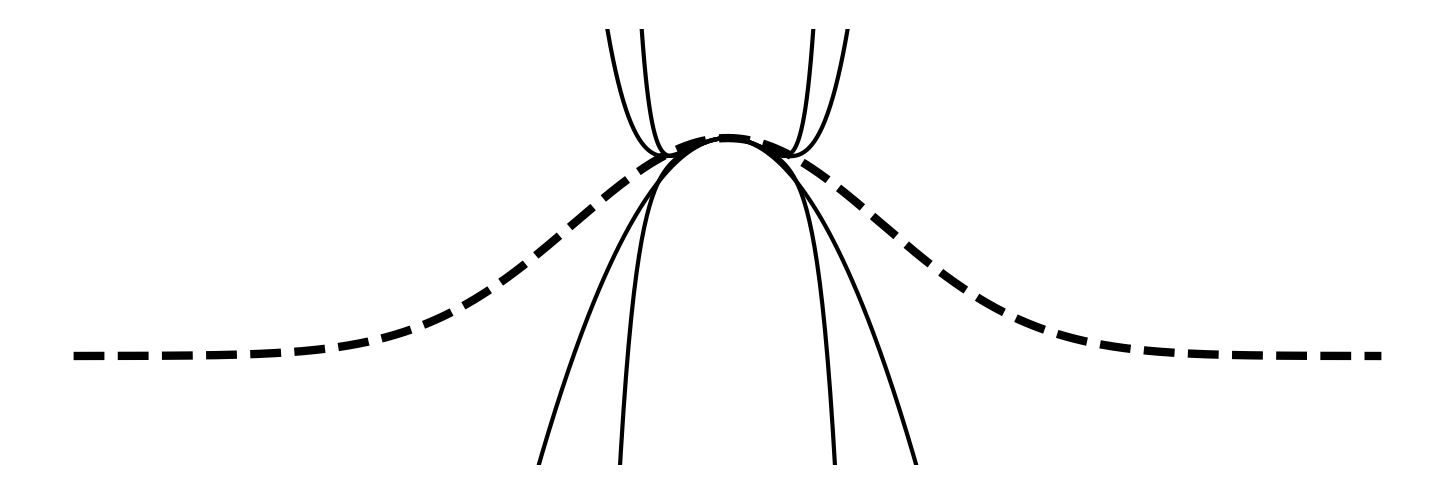
显然,泰勒展开不满足我们的需求
多项式插值
作为一种最为经典的方法,多项式插值也是将一个复杂函数转化为多项式函数的重要方法。我们首先讨论多项式插值法的原理及其计算方法。当然,即使读者无法理解此部分仍不会影响工程实现。
多项式插值后将获得如下多项式:
$$ p(x) = p_0 + p_1 x + p_2 x^2 + \cdots + p_n x^n $$
此处我们以 4 阶多项式插值为例,则最终获得的公式如下:
$$ p(x) = p_0 + p_1 x + p_2 x^2 + p_3 x^3 + p_4 x^4 $$
为了获得 $f(x) = e^{-x^2}$ 对应的多项式插值结果,我们需要对上式中的未知数进行求解。根据线性方程组的知识,我们知道为了求解上述式子中的未知数,则需要至少 5 个值。在 $[0, 4]$ 区间内,在 $f(x) = e^{-x^2}$ 曲线上均匀抽取 $(x_i, y_i)$ 点,如下:
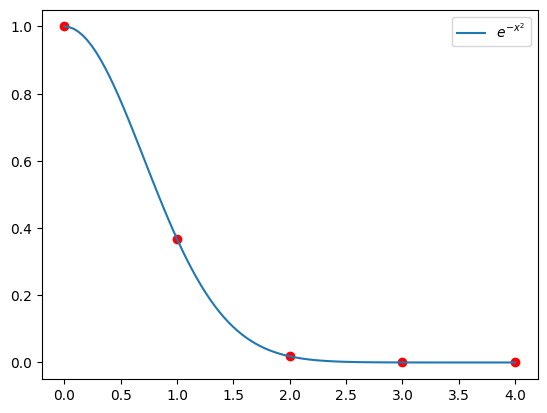
令 $p(x_i) = f(x_i)$ ,即:
$p_0 + p_1 x + p_2 x^2 + p_3 x^3 + p_4 x^4 = y_i$
我们需要求解以下矩阵:
$$ \begin{bmatrix} 1 & x_0 & x_0^2 & x_0^3 & x_0^4 \\ 1 & x_1 & x_1^2 & x_1^3 & x_1^4 \\ 1 & x_2 & x_2^2 & x_2^3 & x_2^4 \\ 1 & x_3 & x_3^2 & x_3^3 & x_3^4 \\ 1 & x_4 & x_4^2 & x_4^3 & x_4^4 \\ \end{bmatrix} \cdot \begin{bmatrix} p_0 \\ p_1 \\ p_2 \\ p_3 \\ p_4 \end{bmatrix}= \begin{bmatrix} y_0 \\ y_1 \\ y_2 \\ y_3 \\ y_4 \end{bmatrix} $$
以上给出的包含 $x$ 的矩阵被称为 Vandermonde matrix ,我们可以将上述计算使用以下公式表述:
$$ V(x) \cdot c = w \cdot y $$
此处的 $V(x)$ 即上文中的包含 $x_i$ 的庞大矩阵,而 $c$ 则是待求参数,$w$ 代表不同 $y$ 值的权重,在此处,我们认为选择的 5 个点的权重均为 1,而 $y$ 则是由 $y_i$ 构成的矩阵。
$V(x) \cdot c = w \cdot y$ 的求解是一个纯数学内容,我们在此处不再讨论。我们求解获得了如下结果:
$$ 1 - 0.6665 x - 0.0490 x^2 + 0.0986 x^3 -0.0150 x^4 = y $$
将上述图像与原函数绘制在一起如下图:
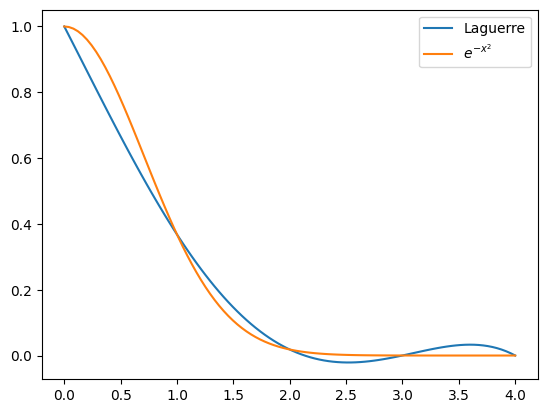
而两者的之差如下图所示:
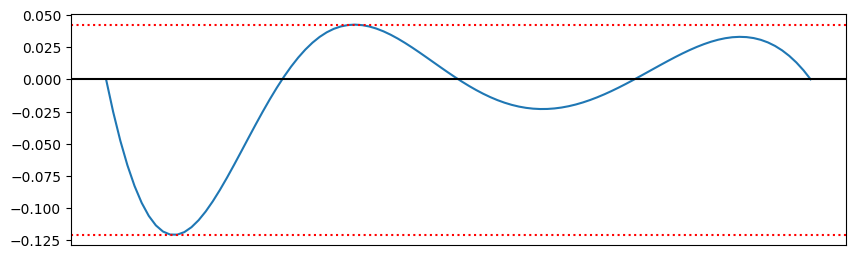
我们可以看到误差较大,且在我们选择的点处均为 0 ,说明上述方程的求解是正确的。为了提高精度,此处直接提高多项式插值的阶数,我们直接使用 15 阶插值,误差如下图:

我们在靠近区间两侧时,多项式的误差极具上升,一度达到相当大的误差,而在区间中部位置,误差则相对稳定。数学家 Carl Runge 在 1901 年时发现了此现象。今天我们将此现象命名为 Runge’s phenomenon,由于此现象的存在,我们不能简单通过提高阶数实现更高的拟合精度。我们会在后文引入新的数学工具解决这一问题。但在解决此问题前,我们给出如何求解任意方程的多项式插值的多项式。
我们首先给出所有代码:
import math
import numpy as np
from numpy.polynomial import Polynomial
from numpy.polynomial.polynomial import polyfit
import matplotlib.pyplot as plt
x = np.linspace(0, 4, 16)
y = np.exp(-x ** 2)
ploy_y_coef = polyfit(x, y, 16)
x_new = np.linspace(0, 4, 100)
ploy_y = Polynomiale(ploy_y_coef)
diff = ploy_y(x_new) - np.exp(-x_new ** 2)
plt.figure(figsize=(10, 3))
plt.plot(diff)
plt.axhline(0, color='black')
plt.axhline(diff.max(), color='red', linestyle=':', )
plt.axhline(diff.min(), color='red', linestyle=':')
第一步使用 np.linspace(0, 4, 16) 在区间 $[0, 4]$ 中均匀选择 16 个点;第二步计算这些点对应的 $y$ 值;第三步使用 lagfit 函数进行插值拟合。
polyfit(x, y, deg) 接受 x,y 及其阶数 deg 三个参数。此函数返回结果为多项式的各项系数,按升阶排序。即第一个参数为常数项系数,第二个参数为 $x$ 的系数,而第三个参数为 $x^2$ 的次数,以此类推。更多信息可以参考 numpy.polynomial.polynomial.polyfit 文档。
而后续步骤均为绘图,我们使用 Polynomiale(ploy_y_coef) 基于拟合结果构造了多项式,并用于后文计算多项式的结果与原函数比较。
切比雪夫点
为了解决上述 Runge's phenomenon 问题,我们需要将插值点尽可能移动到区间边缘,以保证函数在区间边缘的误差。万幸的是,Chebyshev nodes 可以解决这一问题。切比雪夫点是指在区间 $[a, b]$ 上,使用以下公式抽取的点:
$$ x_i = \frac{a + b}{2} + \frac{b - a}{2} cos(\frac{2i + 1}{2n}\pi) \\ y_i = f(x_i) $$
可以使用以下 python 代码计算 Chebyshev nodes 的值:
a = 0
b = 4
n = 16
cheb_nodes = (a + b) / 2 + (b - a) / 2 * np.cos(2 * np.arange(1, n + 1) * np.pi / (2 * n))
基于上述 Chebyshev nodes 进行多项式插值,获得如下图像:
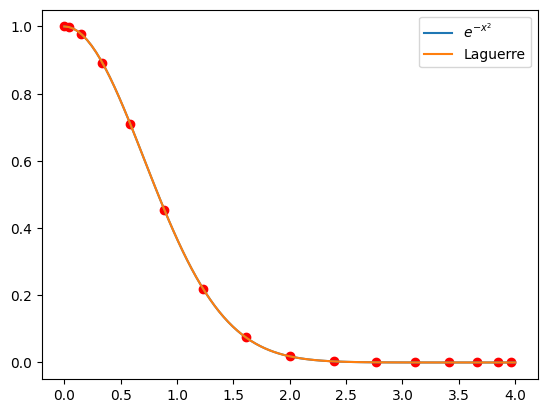
绘制其误差图像如下:
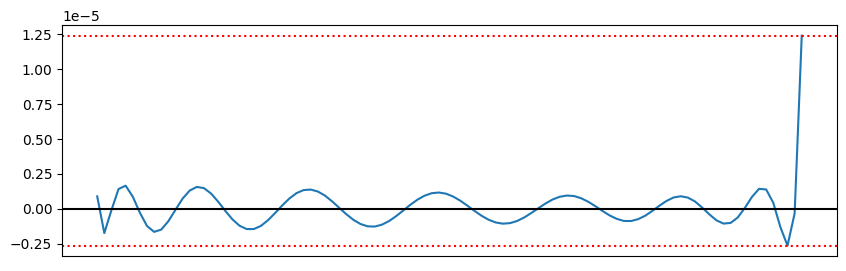
此时,我们可以看到 16 阶插值的误差虽然在右侧仍有增加,但总体误差仍保持在 1e-5 数量级内。在智能合约内实现 16 阶多项式有可能,但是 gas 相对来说较高,且事实上 1e-5 数量级的误差对于常见的 1e-18 精度的代币而言误差仍相对较大。我们需要探索新的方法来简化多项式。
Equioscilation theorem
观察上文给出的误差图像,我们可以发现误差的正峰值和负峰值几乎均匀排布在整个区间内。假如正峰值和负峰值的数量相等,在计算多项式和原始函数的累计误差时,其误差可以互相抵消。
上述表述对应了 Equioscilation theorem ,简单来说,我们需要使多项式与原始函数的误差峰的数量为 $n + 1$ ,如此就可以实现正负峰值抵消的效果。理论上,我们可以通过手动调整 $x_i$ 的位置实现,但显然,手动调整的方法并不可靠。我们将引入 Remez algorithm 解决以上问题。
我们假设存在多项式满足 Equioscilation theorem 定理,则该多项式内的一组点一定满足以下公式:
$$ p(x_i) = f(x_i) + (-1)^i e $$
其中 $e$ 代表误差。上述公式蕴含了一个非常伟大的思想,即我们不是构造一个完美的插值函数而是可以接受误差的存在。基于上述思想,我们可以控制误差并将其放置在最佳位置。
$$ p_0 + p_1 x + p_2 x^2 + p_3 x^3 + p_4 x^4 + (-1)^i e = y_i $$
我们需要求解上述式子中的 $p_i$ 参数同时求解出 $e$ 且要求 $e$ 为局部最小点。但此时,我们遇到了一个问题,即如何确定 $x_i$ 的值,此前我们直接使用了基于 Chebyshev nodes 计算获得的 $x_i$ 。
在 Remez algorithm 算法内,我们使用了以下流程:
第一轮计算也使用了
Chebyshev nodes给出的 $x_i$ ,选择 $n+2$ 个节点计算上述公式中的 $p_i$ 和 $e$ 即可。设获得的多项式为 $p(x)$获得 $p(x) - f(x)$ 误差最大的 $n+2$ 个节点进行下一轮 $p$ 和 $e$ 的计算
当 $e$ 充分小时,停止上述第 2 轮的迭代过程
上述流程较为复杂,且目前 scipy 和 numpy 均为提供对应算法,所以此处我们使用了 sollya进行了求解:
> canonical=on!;
> p = remez(exp(-x^2), 5, [0;4]);
> p;
1.01503162500799209433718957953581037480414994754216 + -7.4411988196639040318464266347166311492790560708027e-2 * x + -1.2487346949049736525320888704586730102665908143941 * x^2 + 0.90289563474632363059412790157626434814930459420749 * x^3 + -0.235971464159814283463956179350819650102342769371384 * x^4 + 2.1387477914989310087690419647882348256843810391479e-2 * x^5
> dirtyinfnorm(p-exp(-x^2), [0;4]);
1.5031625009281040849084215749306853350189291368714e-2
此处调用了 remez 函数进行求解,该函数定义为 remez(f, n, range, w, quality, bounds),各参数含义如下:
f代表要拟合的函数n代表拟合多项式的阶数range代表拟合范围
其他参数为可选参数,读者可以自行参考文档。
此处也使用了 dirtyinfnorm 函数,此函数用于判断区间内某个函数的最大值,我们此处使用了 p-exp(-x^2) 即误差作为目标函数,在 [0;4]区间内求解了误差的最大值,此处显示最大误差为 0.0015 。
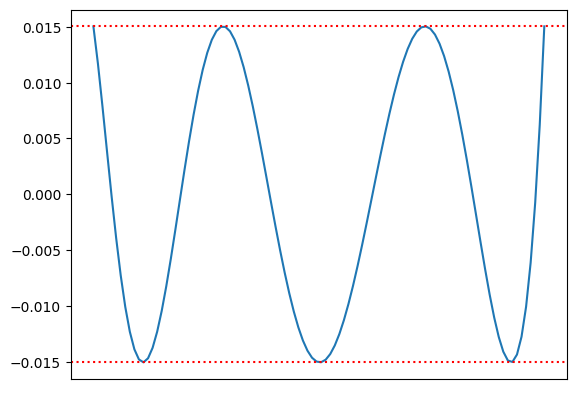
可以明显发现使用 Remez algorithm 算法后,误差减小且误差的峰值出现抵消的情况。
有理逼近
在 Solidity 中,我们可以以较为廉价的成本使用除法,所以我们可以考虑构建包含除法的有理多项式逼近原函数。我们不加证明的给出以下结论,即每一个有理式都可以写成两个多项式的分数,如下:
$$ h(x)=\frac{p(x)}{q(x)}=\frac{p_0+p_1 \cdot x+p_2 \cdot x^2}{q_0+q_1 \cdot x + q_2 \cdot x^2+ q_3 \cdot x^3} $$
我们发现上述多项式的分子为 3 项而分母为 4 项,所以我们将上述有理多项式记为 $(3,4)-term$ 有理多项式。在大部分情况下,我们会固定 $q_0=1$ 以减少计算。我们构造一个 $(3,3)-term$ 多项式用以逼近目标函数:
$$ h(x)=\frac{p(x)}{q(x)}=\frac{p_0+p_1 \cdot x+p_2 \cdot x^2}{1+q_1 \cdot x + q_2 \cdot x^2} $$
我们需要求解上述公式中的 $p_i$ 和 $q_i$ 参数,我们可以使用以下方法对其进行变形:
$$ h(x_i) = \frac{p(x_i)}{q(x_i)}=y_i \rArr p(x_i) = y_i \cdot q(x_i) \rArr \\ p_0+p_1 \cdot x+p_2 \cdot x^2 = y_i \cdot (1+q_1 \cdot x + q_2 \cdot x^2) \rArr \\ p_0 + p_1 \cdot x_i + p_2 \cdot x_i^2 - q_1 \cdot y_i \cdot x_i -q_2 \cdot y_i \cdot x_i^2 = y_i $$
基于上述推导,我们可以通过求解以下矩阵获得 $p_i$ 和 $q_i$ 的值:
$$ \begin{bmatrix} 1 & x_0 & x_0^2 & -y_0 \cdot x_0 & -y_0 \cdot x_0^2 \\ 1 & x_1 & x_1^2 & -y_1 \cdot x_1 & -y_1 \cdot x_1^2 \\ 1 & x_2 & x_2^2 & -y_2 \cdot x_2 & -y_2 \cdot x_2^2 \\ 1 & x_3 & x_3^2 & -y_3 \cdot x_3 & -y_3 \cdot x_3^2 \\ 1 & x_4 & x_4^2 & -y_4 \cdot x_4 & -y_4 \cdot x_4^2 \\ \end{bmatrix} \cdot \begin{bmatrix} p_0 \\ p_1 \\ p_2 \\ q_0\\ q_1 \end{bmatrix} = \begin{bmatrix} y_0 \\ y_1 \\ y_2 \\ y_3 \\ y_4 \end{bmatrix} $$
使用 Chebyshev points 获取区间内的 5 个节点,计算获得参数如下:
$$ \begin{matrix} p_i = [0.99524975 & −0.72539761 & 0.13181353] \\ q_i = [1.00000000 & -0.77962832 & 0.93440655] \end{matrix} $$
计算过程如下:
def chebyshev_nodes(start, stop, n):
f = (2 * np.arange(n) + 1) / (2 * n)
z = -np.cos(np.pi * f) * 0.5 + 0.5
x = start + (stop - start) * z
return x
f = lambda x: np.exp(-x ** 2)
x = chebyshev_nodes(0, 3, 5)
y = f(x)
args = np.stack((np.ones_like(x), x, x**2, -y * x, -y * x ** 2), axis=-1)
np.linalg.solve(args, y)
下图展示了上述有理函数插值结果与原函数的误差:
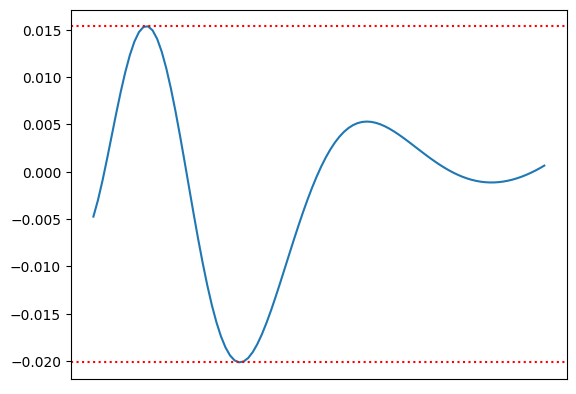
有读者好奇,为什么此处选择 $(3,3)-term$ 多项式而不是其他多项式?事实上,此选择是根据不同参数组合测试出来的。但读者需要注意,应当直接排除在当前区间存在间断点的函数,如 $(4, 2)-term$ ,我们可以绘制 $(4, 2)-term$ 多项式拟合原函数的图像:
有理函数的逼近有可以使用 Remez algorithm 算法进一步优化。
$$ h(x_i) = \frac{p(x_i)}{q(x_i)}=y_i \pm e \rArr p(x_i) = (y_i \pm e) \cdot q(x_i) \rArr \\ p_0+p_1 \cdot x+p_2 \cdot x^2 = (y_i \pm e) \cdot (1+q_1 \cdot x + q_2 \cdot x^2) \rArr \\ p_0 + p_1 \cdot x_i + p_2 \cdot x_i^2 - q_1 \cdot (y_i \pm e) \cdot x_i -q_2 \cdot (y_i \pm e)\cdot x_i^2 \mp e = y_i $$
我们可以使用上文介绍的方法对上述公式中的 $p_i$ 和 $e$ 进行迭代求解。使用 Remez algorithm 优化后结果如下:
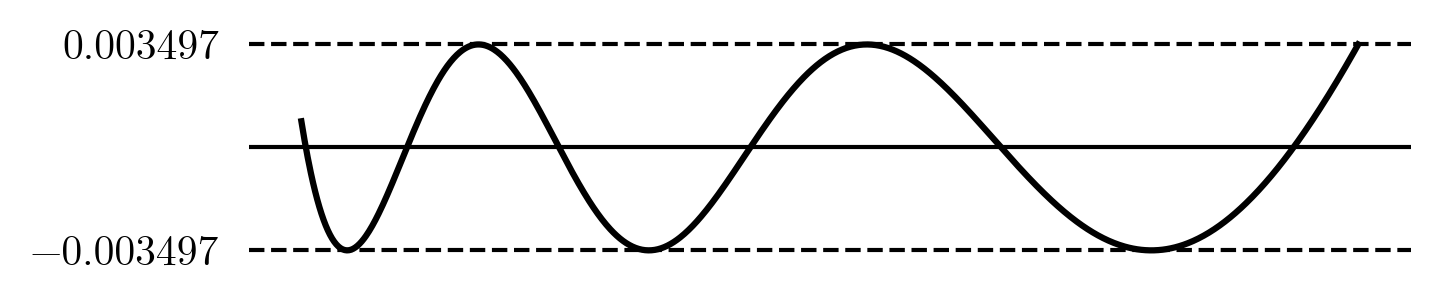
与上文未经 Remez algorithm 优化的多项式相比,误差有明显减少。但是,本文不准备给出此方法的实现代码,因为其实现较为复杂,且我们存在一个更加强大的算法计算拟合程度更高的多项式函数。
在此处,我们对上文所有的算法进行一次总结:
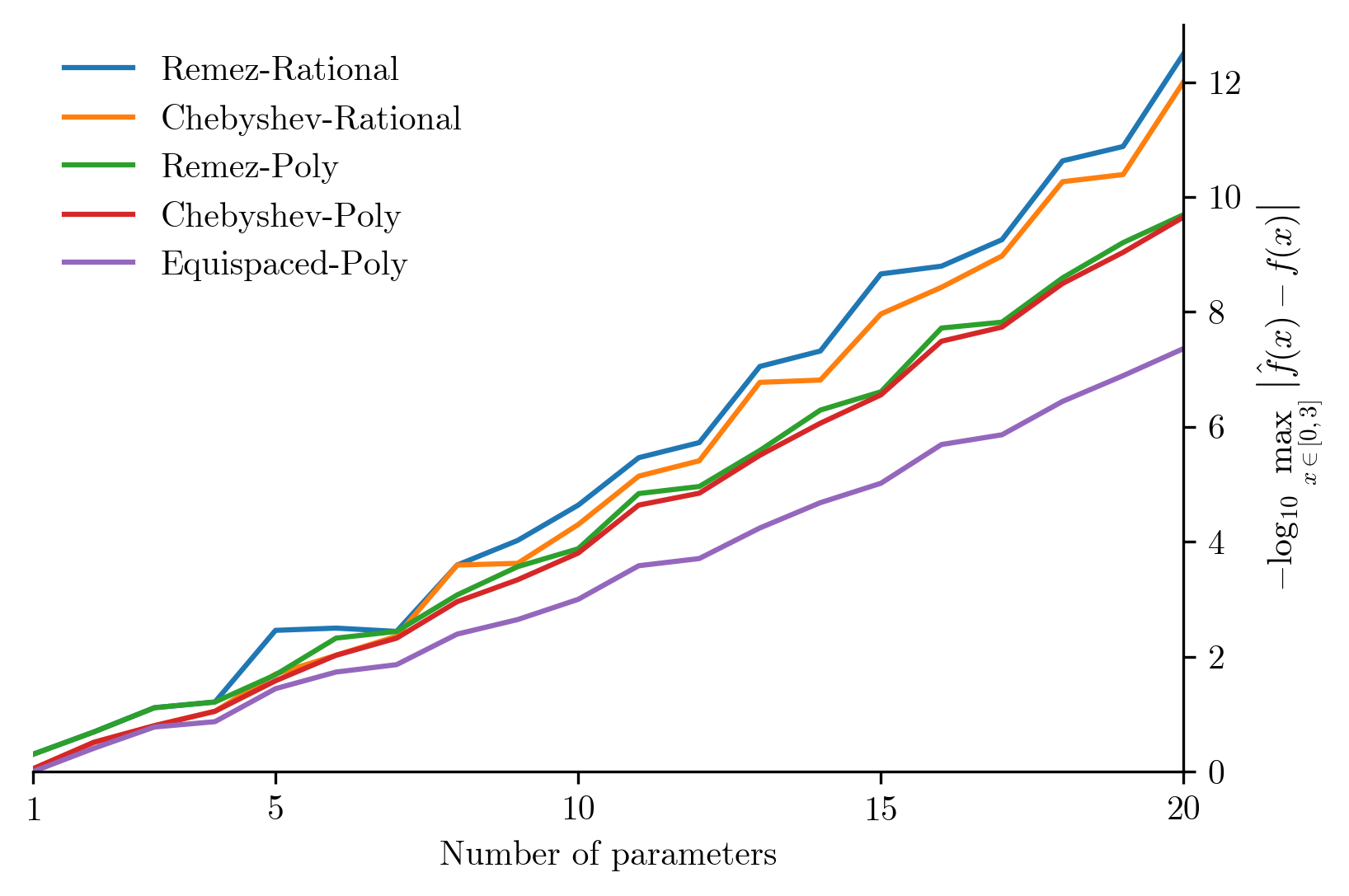
此处的 Chebyshev 代表使用了 Chebyshev nodes 的点选取方法,而 Remez 则代表使用了 Remez algorithm 优化。我们可以看到使用 Chebyshev nodes 进行优化的有理多项式函数已经具有较高的精度,而如果进一步使用 Remze 算法则可以进一步提高精度,但是提升幅度并不十分明显。
barycentric rational
Barycentric rational 是一个较为少见的有理函数插值方法,其定义如下:
设存在以下条件:
$$ x_i \in \R \quad f_i \in \R \quad w_i \in \R $$
其中 $x_i$ 为区间内选择的 Chebyshev nodes 而 $f_i$ 则是 $f(x_i)$ 的简写,而 $w_i$ 则是插值计算获得的参数。基于上述参数,我们可以获得如下多项式:
$$ r(x) = \frac{\sum_{i=0}^{n} \frac{w_i}{x - x_i}f_i}{\sum_{i=0}^{n}\frac{w_i}{x-x_i}} $$
对于上述插值公式中的参数求解,我们可以使用 $BRASIL $ 算法,如果读者感兴趣,可以自行参考 An algorithm for best rational approximation based on barycentric rational interpolation 论文。在此处,我们直接调用 c-f-h/baryrat 包进行计算。
使用相同的阶数计算 Barycentric rational 多项式:
f = lambda x: np.exp(-x ** 2)
r = baryrat.brasil(f, [0, 3], 3)
此处使用了 $(3, 3)-term$ 多项式在 $[0, 3]$ 区间内进行 Barycentric rational 的插值,获得 r 即插值结果。读者可以调用 r.nodes 获得 $x_i$ 参数,调用 r.values 获得 $y_i$ 参数,调用 r.weights 获得 $w_i$ 参数。
使用以下代码绘制误差图像:
x_new = np.linspace(0, 3, 10000)
diff = r(x_new) - f(x_new)
plt.plot(x_new, diff)
plt.axhline(diff.max(), color='red', linestyle=':', )
plt.axhline(diff.min(), color='red', linestyle=':')
plt.xticks([])
结果如下图:
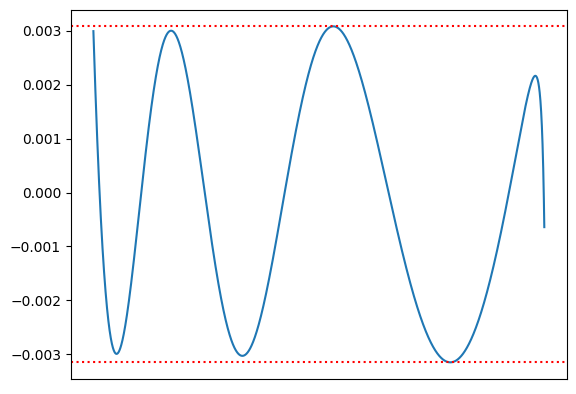
显然比上文的 Chebyshev-Rational 算法具有更高的精度。
附注
在 solidity 中,我们经常使用 18 位定点小数,所以事实上,大部分情况下我们需要将多项式插值的误差优化到 1e-18 数量级,这对于 python 自带的浮点数而言此精度过高,python 以及 numpy 自带的一系列计算工具都会在此精度下产生难于忽视的误差,导致最终的拟合精度下降。所以我们需要安装一些超高精度的计算库,此处我们可以安装 flamp 包,安装此包的同时会自动安装 gmpy2 高精度计算包。
我们以 baryrat 为例对 $[-\frac{1}{2}ln2,\frac{1}{2}ln2]$ 内的 $e^x$ 进行插值展示如何使用高精度计算包。
我们首先展示没有使用高精度计算包的情况:
import numpy as np
f=np.exp
r = baryrat.brasil(f, interval=(-0.5 * np.log(2), 0.5 * np.log(2)), deg=5)
绘制误差图如下:
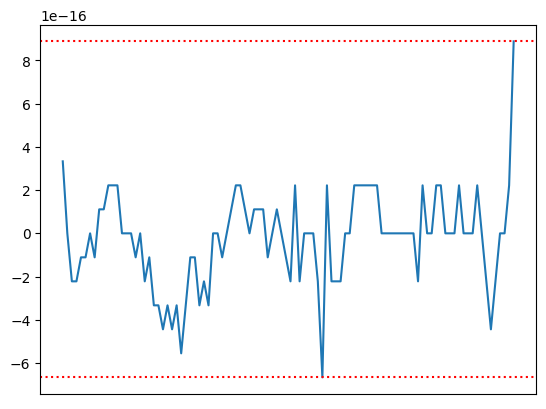
使用 gmpy2 进行重新计算:
import flamp
import gmpy2
flamp.set_dps(100)
f = np.vectorize(gmpy2.exp)
r = baryrat.brasil(f, interval=(-0.5 * gmpy2.log(2), 0.5 * gmpy2.log(2)), deg=5)
此处使用了 np.vectorize 来向量化函数操作,使用向量化的原因是在 brasil 函数内部传参的时候使用了 ndarry 数据类型。
此时,我们重新绘制误差图像,如下:
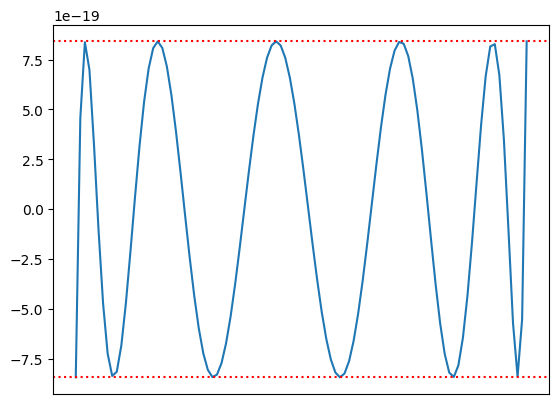
可见精度存在明显的上升,且报错消失。所以,对于生产级应用的插值而言,使用 gmpy2 进行高精度计算是可以显著提高计算精度的。
总结
本文介绍了多种多项式插值的方法,包括泰勒展开、多项式插值、有理多项式插值等插值方案,及其优化算法,如 Chebyshev nodes 和 Remez algorithm 方法。
在本系列的下篇中,我们会正式将本文中的多项式插值方法迁移至智能合约计算中,并进行误差评估。