概述
在上一篇中,我们介绍了如何使用 Clickhouse 进行基础的信息提取,这些信息往往依赖于以太坊底层机制,我们只能获得如 ETH 转账、 gas 等信息,这些信息并没有涵盖以太坊中最重要的智能合约的相关数据。这使我们无法获得 ERC-20 代币转账或 NFT 转移等数据。
对于很多数据分析师而言,了解智能合约相关数据更加重要。本文主要介绍如何获得关于智能合约的相关数据,以进一步完善数据分析。本篇仍主要聚焦于数据清洗,但仍会给出部分数据分析案例以帮助读者理解。
前置知识
如果需要获取合约内的数据,我们必须了解对于智能合约非常重要的 Event 数据类型。该数据类型的一般定义如下:
event Transfer(address indexed _from, address indexed _to, uint256 _value)
上述定义来自 ERC-20 的 EIP 文档。在智能合约中,我们可以通过 emit Transfer(...) 来将 event 释放到区块空间中,这使我们可以从外部读取智能合约运行的结果。我们可以将此释放行为认为是日志记录,在 etherscan 中,该部分记录在 Logs 中,如下图:
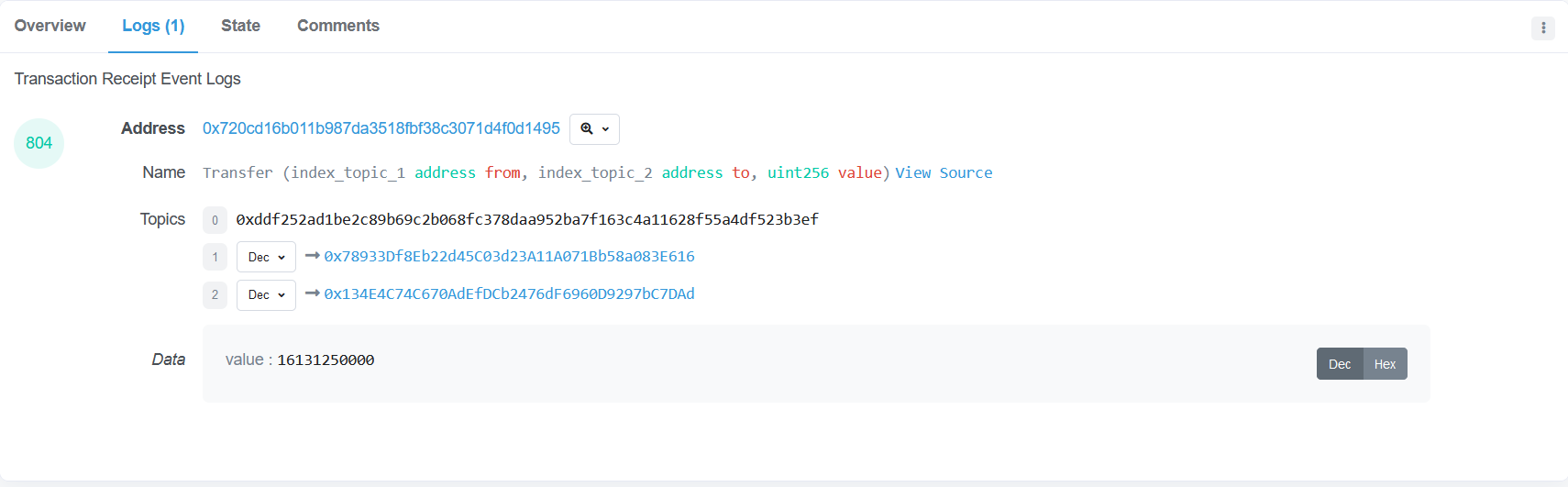
我们需要关注 Topics 栏中的内容,该部分内容与上述定义是对应的:
Topics 0是Transfer(address,address,uint256)的Keccak-256哈希结果Topics 1对应为address indexed _from表示代币转移的发起方Topics 2对应为address indexed _to表示代币转移的接受发Data对应为_value表示代币转移的数量
总结来说,Topics 0 是对事件整体名称的 Keccak-256 哈希结果,通过此 Topics ,我们可以获得区分不同的事件。读者可以通过 Signature Database 反查具体的事件名称,如下图:

标有 indexed 的变量为根据顺序逐一显示在 Topics 中,通过这些 Topics 我们可以获得合约运行过程中的大量信息。事实上,这也是获得链上智能合约运行信息最常见和最有效的方法,包括钱包在内的大量区块链基础设施都依赖于Event 释放获得的日志信息。由于 Event 如此重要,所以常见的 Event 基本都是由 EIP 规定,以实现兼容性。
假如你构造的 ERC-20 代币进行代币转移时不释放
Transfer事件,这会导致钱包内对此 ERC20 代币余额信息不更新,对持币人造成巨大困扰。
最后,所有没有标识 indexed 的变量会被放在 Data 内,这部分数据往往重要性不高。
关于
emit事件释放的底层逻辑,我们在 NFT合约分析:ERC721A 内已经进行过讨论。
在我们的数据源 0xfast 中,这部分数据结构如下:
"logs": [
{
"address": "0xdac17f958d2ee523a2206206994597c13d831ec7",
"topics": [
"0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef",
"0x0000000000000000000000004ad8d9cf9424b477e77a0d7c339c4de792b92fc6",
"0x000000000000000000000000a144a5c6aaa3a11dfb63a9b7b836ec35ff7a9bf3"
],
"data": "0x00000000000000000000000000000000000000000000000000000000886f5e40",
"blockNumber": "0xfcd79e",
"transactionIndex": "0x1",
"logIndex": "0x4",
"@type": "Log"
}
]
我们需要使用 SQL 语言提取出这一部分并进行保存。
数据清洗
数据导入
此部分与上一篇 一致,如果您当前数据库内仍存在 jsonTemp 表格,可不进行此部分。为方便读者,我们列出 SQL 代码:
CREATE TABLE jsonTemp
(
field String
)
ENGINE = Memory
INSERT INTO jsonTemp
SELECT * FROM url('https://eth-uswest.0xfast.com/stream/free?range=16448580-16448680', 'JSONAsString', 'field String');
此处,我们不再详细分析 SQL 代码,读者如感兴趣,请自行参考 上一篇。
数据提取
我个人习惯于在进行表格建立前使用 SELECT 进行数据提取,以方便后期的表格建立和插入。
在此处,我决定提取交易的以下数据:
- hash 交易的 hash 值
- blockNumber 交易所处区块位置
- value 交易转移的 ETH 价值
- logs 获取智能合约数据,也是本篇文章的核心数据,具体来看,我们需要以下数据:
- topics
Event的具体内容 - address 释放
Event的合约地址
- topics
读者可根据自身需求选择需要提取的数据。
接下来,我们需要构造提取字段,如下:
WITH JSONExtract(
field,
'Tuple(transactions Nested(hash String, blockNumber String, value String, logs Nested(address String, data String, topics Array(String))))'
) AS parsed_json
SELECT
untuple(arrayJoin(tupleElement(parsed_json, 'transactions'))) as tx
FROM
jsonTemp jt
LIMIT 5
如果读者无法理解上述 SQL 代码,请自行阅读 上一篇文章
结果如下:
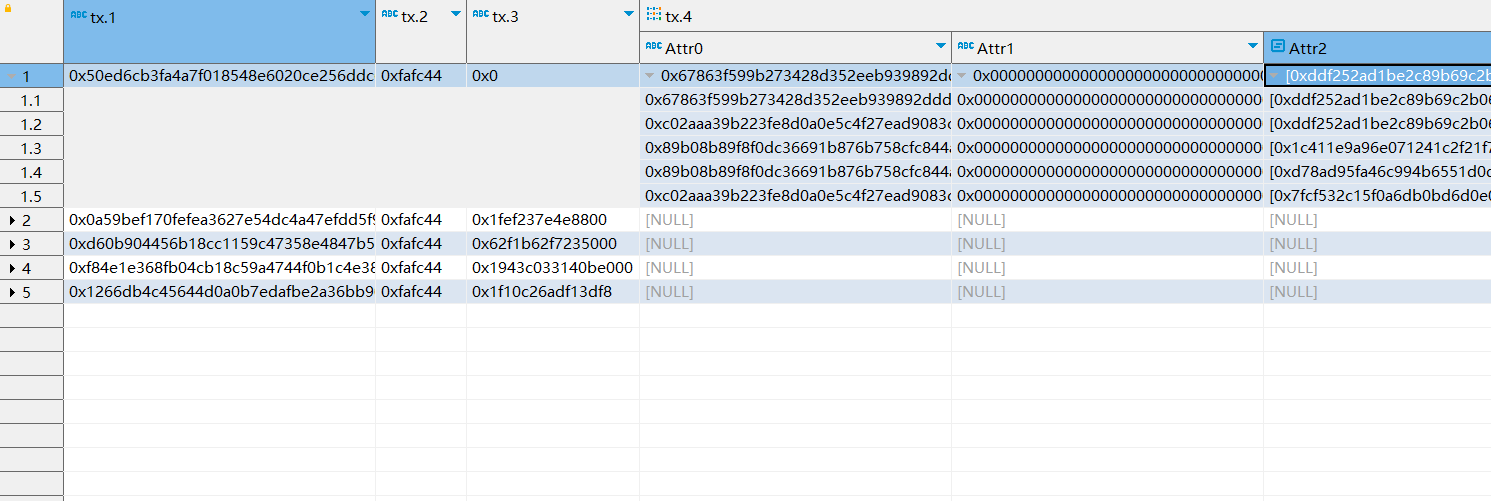
其中 tx.4 由于其为 Nested 导致较难理解,此处我们特别分析,如下:
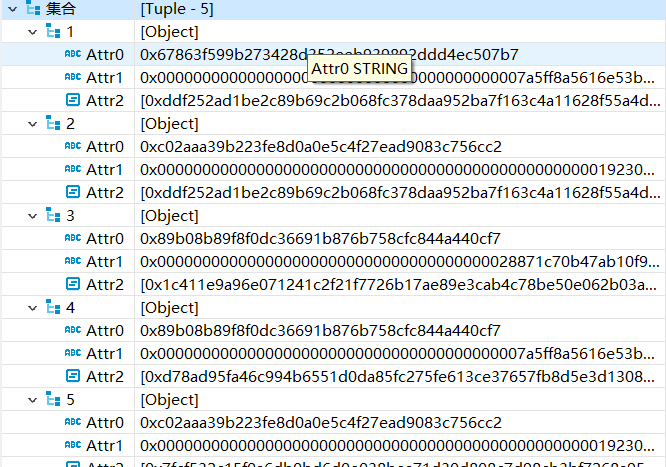
通过上图,我们知道 tx.4(即 logs) 的具体构成。显然,我们需要将此部分进行重构。我们的目标是将 logs 的每一项拆分出来将其作为单独的一列存在。通过这种方式,我们既保留了 topics 的完整性,也将 logs 由过去的 3 层嵌套转变为 2 层嵌套。前者是几乎无法检索的而后者具有良好的可检索性。
我们分析 ARRAY JOIN 是可以解决这一问题的,简单来说,该函数可以进行如下转化:
原表格
┌─s───────────┬─arr─────┐
│ Hello │ [1,2] │
│ World │ [3,4,5] │
│ Goodbye │ [] │
└─────────────┴─────────┘
LEFT ARRAY JOIN转化后的表格
┌─s───────────┬─arr─┐
│ Hello │ 1 │
│ Hello │ 2 │
│ World │ 3 │
│ World │ 4 │
│ World │ 5 │
│ Goodbye │ 0 │
└─────────────┴─────┘
请参考文档 获得其详细介绍。
SQL 代码如下:
SELECT *
FROM
(
WITH JSONExtract(
field,
'Tuple(transactions Nested(hash String, blockNumber String, value String, logs Nested(address String, data String, topics Array(String))))'
) AS parsed_json
SELECT
untuple(arrayJoin(tupleElement(parsed_json, 'transactions'))) as tx
FROM
jsonTemp jt
LIMIT 5
)
LEFT ARRAY JOIN `tx.4`;
此处选择
LEFT ARRAY JOIN的原因是部分没有合约交互的交易的logs为空,但这部分交易在数据分析中不能丢弃。
结果为:
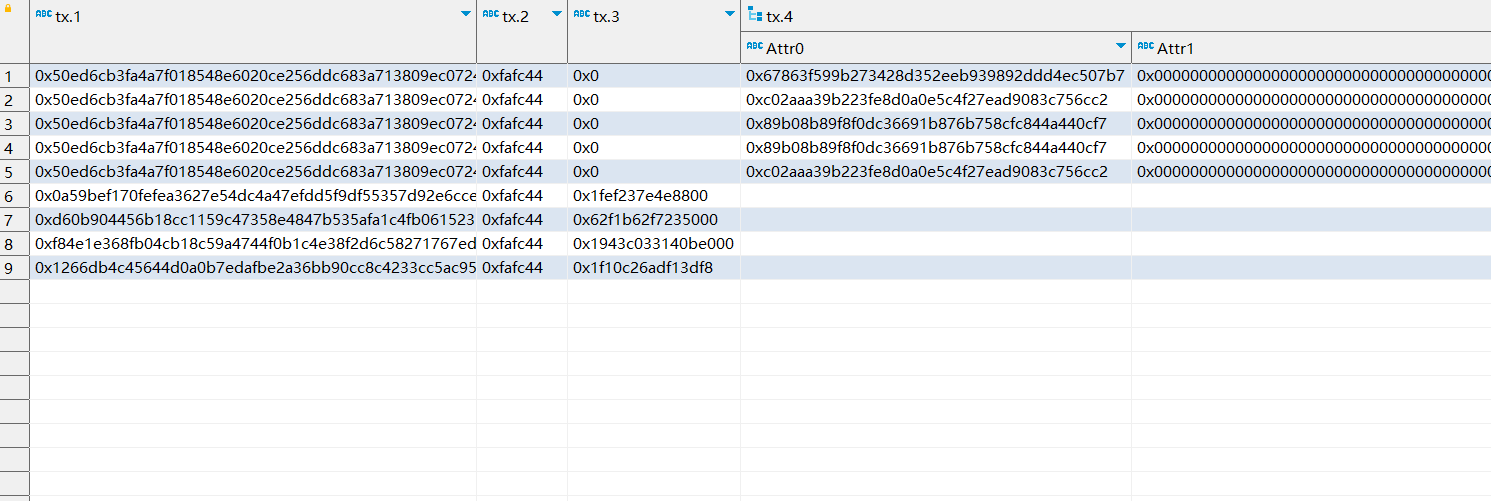
此数据已经可以进行导入步骤。
数据导入
在数据导入前,我们需要建立对应的表格,根据上文结果,我们可以使用以下 SQL 进行表格创建:
CREATE TABLE logsTemp
(
txHash String,
txblockNumber String,
value String,
contractAddress String,
txlogsData String,
topics Array(String)
)
ENGINE = MergeTree
ORDER BY txblockNumber
执行数据导入:
INSERT
INTO
logsTemp
SELECT
`tx.1`,
`tx.2`,
`tx.3`,
untuple(`tx.4`)
FROM
(
SELECT
*
FROM
(
WITH JSONExtract(
field,
'Tuple(transactions Nested(hash String, blockNumber String, value String, logs Nested(address String, data String, topics Array(String))))'
) AS parsed_json
SELECT
untuple(arrayJoin(tupleElement(parsed_json,
'transactions'))) as tx
FROM
jsonTemp jt
)
LEFT ARRAY
JOIN `tx.4`
)
此处遇到了一个小问题,详情可以参考 使用 clickhouse 遇到的一个奇怪问题
完成导入后,我们可以进行一个简单的检索以获得所有 ERC-20 转移交易:
SELECT
*
FROM
logsTemp lt
WHERE
topics[1] == '0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef';
LIMIT 10
注意在
Clickhouse中只有单引号可以标识字符串,且Array的索引从 1 开始
数据补充
我们获得了很多合约地址,其中包含大量的 ERC-20 合约抛出的 Event ,我们希望可以获得这些代币的名字。
这意味着我们需要构造一个代币名称与合约地址的映射关系,使用关系型数据库很容易做到这一点。但数据来源可能对很大读者来说是一个问题,但很幸运,我找到了 Token Lists 网站。该网站以 JSON 的形式给出了一系列代币数据源。此处我们选择的是 1inch 提供的包含 987 种代币的数据源,版本为 145.0.0,读者可以点击 此链接 查看数据。
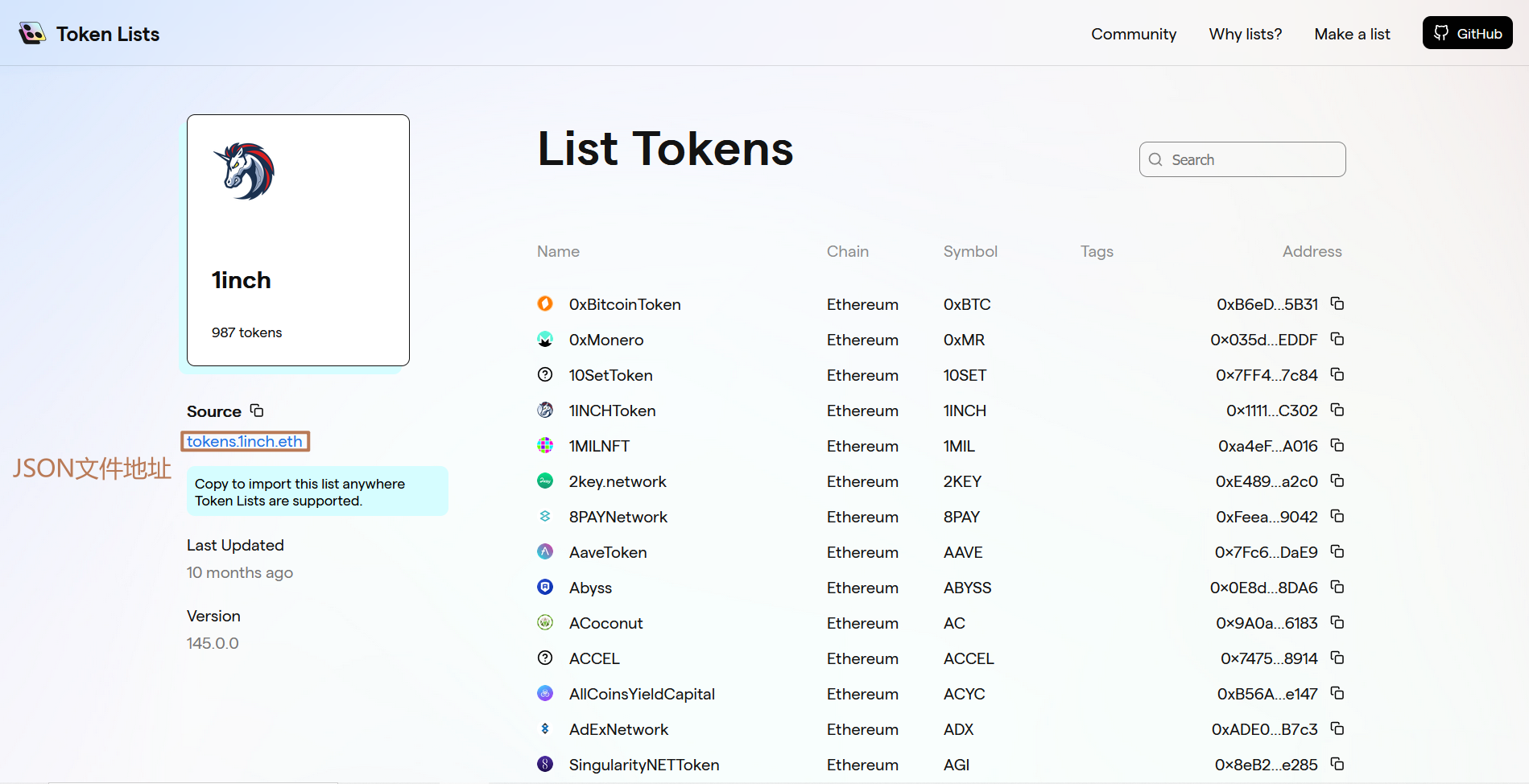
我们可以看到 JSON 文件地址为以 ens 地址,使用 eth.limo 网关(即访问 https://tokens.1inch.eth.limo/ )就可以获得其中的数据。
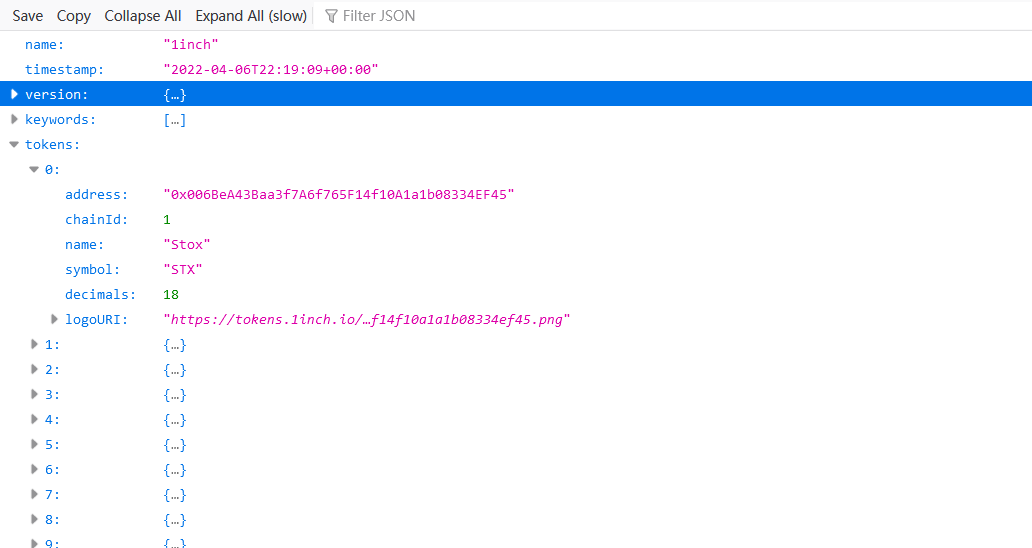
相信读者已经不想使用复杂的 Tuple 提取数据,所以此处我们直接使用 Clickhouse 的实验性数据结构 JSON 来提取数据。
在进行具体操作前,我们需要修正 Clickhouse 客户端:
- 右键数据库点击
编辑 连接如下图:
- 点击
驱动属性,如下图:
- 找到
session_id属性,点击修改值,填入一个UUID
UUID 可以使用命令行工具
uuidgen或者 Online UUID Generator 网站生成
如果读者在后文操作时遇到
DB::Exception: There is no session or session context has expired. (THERE_IS_NO_SESSION)报错则说明上述设置错误。
为什么需要设置
seesion_id? 因为后文我们使用了SET语句,此语句需要上下文指引,但http本身是无状态的,所以此处设置了session_id以方便服务端确定上下文,类似cookie的作用
为后文方便数据存储,我们创建如下表格:
SET allow_experimental_object_type = 1;
CREATE table tokenListJson(
tokenInfo JSON
)
ENGINE = Memory
在 DBeaver 中,; 隔断的 SQL 语句会根据光标位置运行,如下图:

由于光标位置位于第一个分号前,所以运行时只会运行 SET allow_experimental_object_type = 1;语句,如果需要运行 CREATE table 语句,则需要调整光标位置到第二行或之后的行。
在操作中,如果读者遇到
DB::Exception: Cannot create table with column 'tokenInfo' which type is 'Object('json')' because experimental Object type is not allowed. Set setting allow_experimental_object_type = 1 in order to allow it. (ILLEGAL_COLUMN)报错,则说明SET allow_experimental_object_type = 1;语句过期,需要重新运行此语句。
使用以下语句插入数据:
INSERT INTO tokenListJson
SELECT *
FROM
url('https://tokens.1inch.eth.limo/', 'JSONAsObject', 'token JSON');
此处也可以使用
https://wispy-bird-88a7.uniswap.workers.dev/?url=http://tokens.1inch.eth.link替换https://tokens.1inch.eth.limo/,前者速度似乎更快。
运行以下语句,检查数据情况:
DESCRIBE tokenListJson SETTINGS describe_extend_object_types=1;
返回值如下:
Tuple(keywords Array(String), logoURI String, name String, timestamp String, tokens Nested(address String, chainId Int8, decimals Int8, logoURI String, name String, symbol String), version Tuple(major Int16, minor Int8, patch Int8))
可以发现事实上 JSON 数据格式在 Clickhouse 就是以 tuple 进行存储的。
使用以下代码直接提取 tokens 中的内容并转化为表:
SELECT untuple(arrayJoin(tokenInfo.tokens))
FROM tokenListJson tlj
构造表格以方便存储检索结果(数据类型和名称可参考 DESCRIBE 的返回结果):
CREATE TABLE tokenInfo(
address String,
chainId Int8,
decimals Int8,
logoURI String,
name String,
symbol String
)
ENGINE = MergeTree
ORDER BY address
使用以下语句插入表格:
INSERT INTO tokenInfo
SELECT untuple(arrayJoin(tokenInfo.tokens))
FROM tokenListJson tlj
我们可以尝试查询 USDC 的相关数据:
SELECT *
FROM tokenInfo ti
WHERE symbol == 'USDC'
数据分析
事实上,我们的数据清洗并不完整,我们没有加入比如 event 与文字的对应关系表等数据。我进行了大量搜索,并没有此类开源数据库,读者可以考虑自建此类基础设施。但本文中给出的数据以足够支持一般的数据分析工作。
ERC-20 交易频度
首先,我们需要确认转账的交易的 event 名称,使用 etherface text 可以解决这一问题。
搜索 e#Transfer(e# 表述搜索 event),得到如下结果:
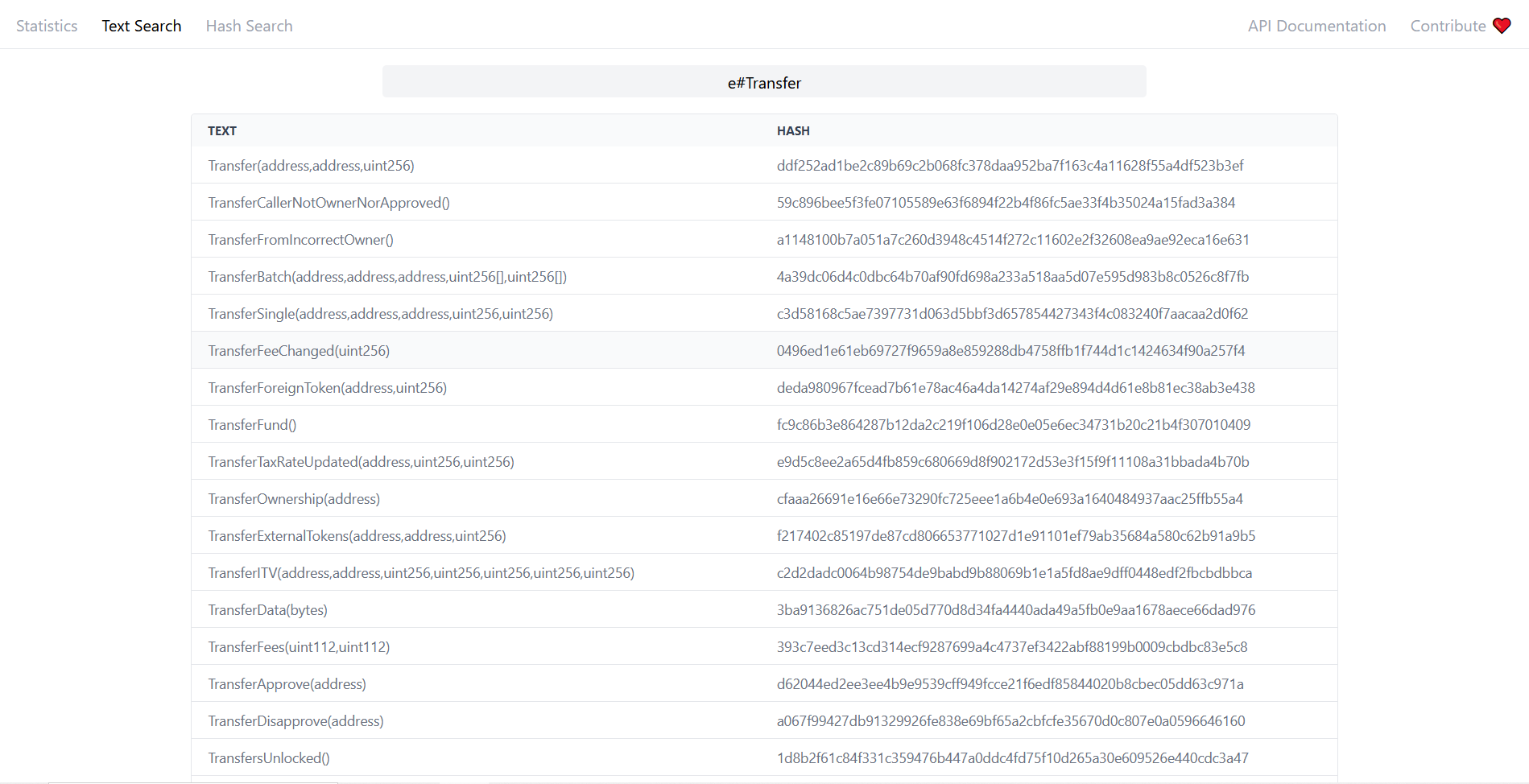
建立以下 SQL 检索:
SELECT
contractAddress,
symbol,
COUNT(*) AS txCount
FROM
logsTemp lt
LEFT OUTER JOIN tokenInfo ti ON
lt.contractAddress = LOWER(ti.address)
WHERE
topics[1] == '0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef'
AND
topics.size0 == 3
GROUP BY
contractAddress,
symbol
ORDER BY
txCount DESC
传说 Clickhouse 在 JOIN 关联索引方面性能较差,但此处我们的数据量较小,所以不考虑优化问题。一个可行的优化方案是构建宽表,直接把 tokenInfo 数据合并到 logsTemp 中。
此处使用了 topics.size0 == 3 来区别 ERC20 代币的转账事件和 ERC721 的转账事件。
前者 ERC20 定义为:
event Transfer(address indexed _from, address indexed _to, uint256 _value)
后者 ERC721 定义为:
event Transfer(address indexed _from, address indexed _to, uint256 indexed _tokenId);
所以两者在 topics 数量上是不同的,前者为 3 而后者为 4。为实现对 topics 的长度查询,我们使用了 size0 函数,具体请参考 文档
上述检索的返回结果如下:
| contractAddress | symbol | txCount |
|---|---|---|
| 0xc02aaa39b223fe8d0a0e5c4f27ead9083c756cc2 | WETH | 2525 |
| 0xdac17f958d2ee523a2206206994597c13d831ec7 | USDT | 2365 |
| 0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48 | USDC | 1085 |
| 0x32c319ac8d2f4a79b2fbdea543473cc03a986aaf | 787 | |
| 0x4d224452801aced8b2f0aebe155379bb5d594381 | APE | 368 |
可以看到此处存在部分数据丢失,这是因为我们使用的 tokenList 较小,读者可有考虑使用 CoinGecko 的超大数据集。
ERC721 交易情况
NFT 是区块链的热门话题,我们可以使用以下检索获得 NFT 的全部转账情况:
SELECT
contractAddress,
COUNT() AS transferCount
FROM
logsTemp lt
WHERE
topics[1] == '0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef'
AND topics.size0 == 4
GROUP BY contractAddress
ORDER BY transferCount DESC
输出结果如下:
| contractAddress | transferCount |
|---|---|
| 0x5f12a00a9deabfb1299dcbbdc654904c3273f842 | 1171 |
| 0x9f44bb8fedb144c6b8e9c46e01375429e04244c3 | 1019 |
| 0x58c7ffcf5591166384beabca7661666c9d47709c | 895 |
| 0x7eba6418388cac0b81c26f9b76d7ea6877bf8308 | 304 |
| 0x11b3cf25f300b8ec587dfc349d419b5181084909 | 289 |
可惜,我们没有 NFT 数据集来补充更多信息,但存在部分 API 可以实现此步骤,可以参考我写的 基于Python与GraphQL的链上数据分析实战 给出的 ERC721 数据获取
当然,对于 NFT 的铸造也是很多人关心的,我们可以通过以下检索查询 NFT 铸造:
SELECT
contractAddress,
COUNT() AS mintCount
FROM
logsTemp lt
WHERE
topics[1] == '0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef'
AND topics[2] == '0x0000000000000000000000000000000000000000000000000000000000000000'
AND topics.size0 == 4
GROUP BY contractAddress
ORDER BY mintCount DESC
铸造交易本质上就是 from 为空地址的交易,所以我们可以通过指定 topics[2] 为空地址来完成检索。
检索结果如下:
| contractAddress | mintCount |
|---|---|
| 0x9f44bb8fedb144c6b8e9c46e01375429e04244c3 | 1019 |
| 0x5f12a00a9deabfb1299dcbbdc654904c3273f842 | 946 |
| 0x58c7ffcf5591166384beabca7661666c9d47709c | 887 |
| 0x6e87070593daa38ac275e718d11e0b496f075fc8 | 189 |
| 0x11b3cf25f300b8ec587dfc349d419b5181084909 | 188 |
WETH 平衡问题
众所周知,WETH 是以太坊中最重要的 ERC20 代币,我们想知道 WETH 在某一时间段内的存款(即 ETH 包装为 WETH) 和取款(即 WETH 兑换 ETH) 是否平衡。
首先,我们知道 WETH 合约地址为 0xC02aaA39b223FE8D0A0e5C4F27eAD9083C756Cc2,使用 智能合约开发效率工具 中介绍的 链上合约阅读 方法,使用 此链接 查看 WETH 合约源代码。
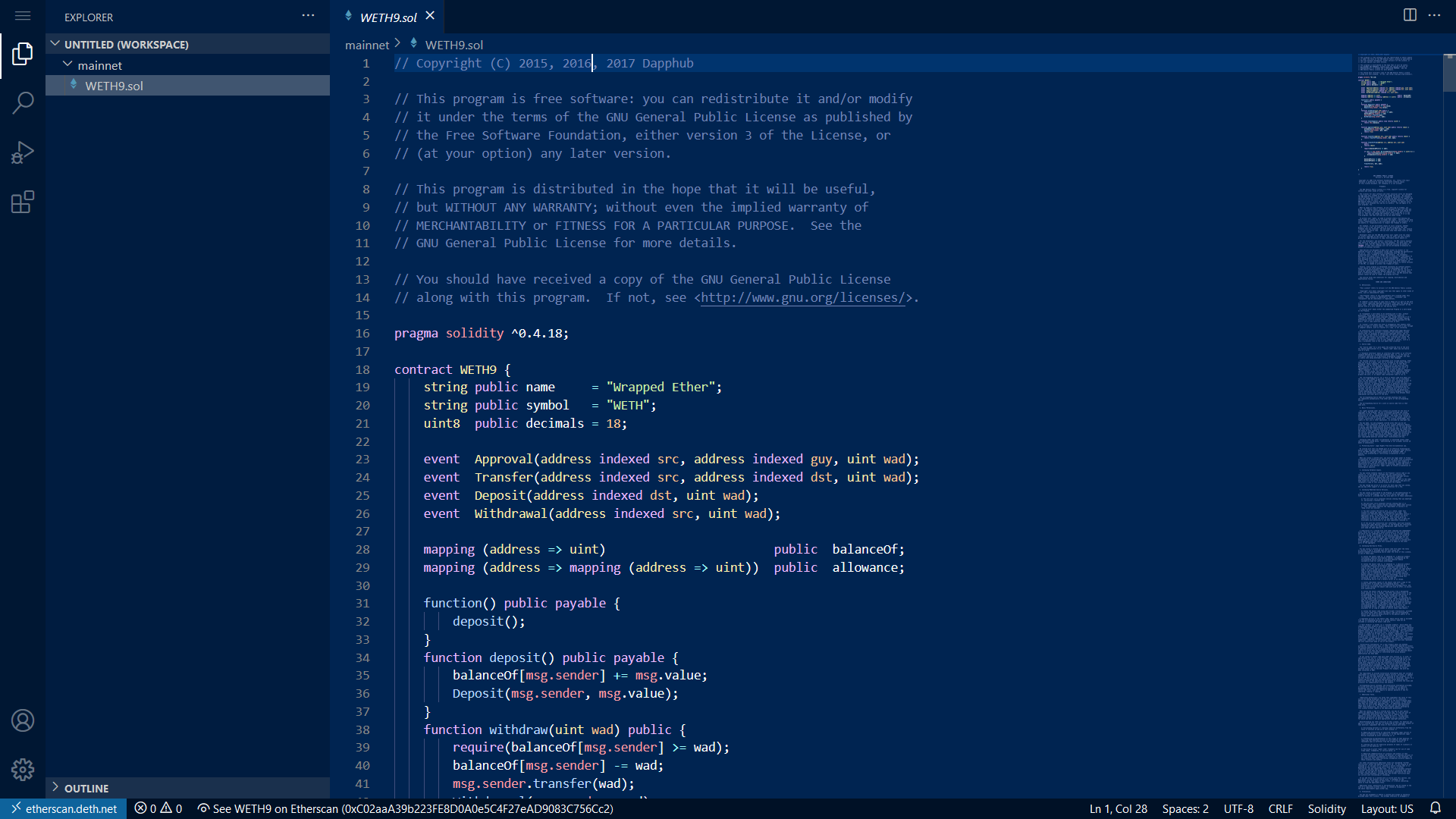
使用 Ctrl + F 快捷键进行 event 搜索,发现定义如下:
event Approval(address indexed src, address indexed guy, uint wad);
event Transfer(address indexed src, address indexed dst, uint wad);
event Deposit(address indexed dst, uint wad);
event Withdrawal(address indexed src, uint wad);
分析实现代码,发现 Deposit 为存款而 Withdrawal 为取款。
使用 foundry 中的 cast 工具获得 topics1 的内容:
cast sig-event "Deposit(address indexed dst, uint wad)"
输出如下:
0xe1fffcc4923d04b559f4d29a8bfc6cda04eb5b0d3c460751c2402c5c5cc9109c
同理可得,Withdrawal 的 topics1 内容如下:
0x7fcf532c15f0a6db0bd6d0e038bea71d30d808c7d98cb3bf7268a95bf5081b65
根据以上信息,我们可以构造如下检索:
SELECT
topics[1],
COUNT(),
SUM(reinterpretAsUInt128(reverse(unhex(txlogsData))))
FROM
logsTemp lt
WHERE
topics[1] == '0xe1fffcc4923d04b559f4d29a8bfc6cda04eb5b0d3c460751c2402c5c5cc9109c'
OR topics[1] == '0x7fcf532c15f0a6db0bd6d0e038bea71d30d808c7d98cb3bf7268a95bf5081b65'
GROUP BY topics[1]
输出结果如下:
| name | count() | sum(reinterpretAsUInt128(reverse(unhex(txlogsData)))) |
|---|---|---|
| 0xe1fffc… | 866 | 714652525202720698543661912 |
| 0x7fcf53… | 798 | 959677908506807633161 |
由此我们发现进入 ERC20 体系流转的 ETH 大于退出的 ETH,可见以太坊智能合约生态系统是吸引人的。
总结
本文对以太坊智能合约的 event 数据进行了提取,又介绍了部分实战项目。总结来说,使用 Event 数据进行分析是目前以太坊智能合约数据分析中使用最广泛的方法,具体分析思路如下:
- 阅读项目文档和合约源代码找到与分析相关的
Event - 获得
Event对应的topics1对数据进行筛选 - 进行分组聚合分析
当然,在本文中,我们没有进行更加复杂且细致的分析工作,在未来,我们会引入图数据以便更加详细的分析数据。