概述
笔者最近遇到了许多关于数据分析的文章,大部分都使用了 Dune 等 SaaS 工具,这些工具往往提供了清洗后的区块链数据和数据库分析工具。对于大部分数据分析师而言,这些工具可以应对一系列复杂的数据分析问题,而且免去了搭建数据处理平台的苦恼。
但作为一个爱折腾的工程师,我决定几乎从零开始搭建一套区块链历史数据数据分析系统。在此项目中,我们仅使用了 0xfast 作为数据提供商,如果读者追求纯粹的自建,可以考虑自建以太坊节点抓取历史数据。
为尽可能提高分析系统的效率,我使用了 Clickhouse 作为数据存储和分析工具。本文仅使用 Clickhouse 以完成以下工作:
- 环境搭建。讨论在服务器内安装
Clickhouse可能会遇到的问题并在个人计算机上安装客户端。 - 数据导入。使用纯粹的 SQL 代码导入数据,此处会涉及到使用
Clickhouse进行 JSON 处理的内容。 - 数据分析。完成一些基础的数据分析任务,这并不是本文的核心。
注意,Clickhouse 对服务器似乎有着严格的性能要求,但由于本文分析的样本仅为 100 个区块,笔者使用 3 核心 3.5 GB 内存的服务器已经可以完成本博客中的任务。VPS负载如下:
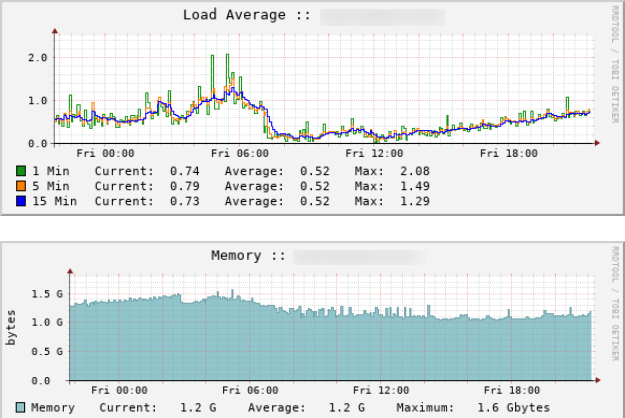
当然,读者也可以考虑使用个人计算机完成此博客中的内容。如果涉及以太坊全区块链数据分析,建议使用高规格服务器,毕竟以太坊全节点数据集近 650GB。
环境搭建
服务端
如果你是一个时间价值比较高的工程师,且不想折腾clickhouse的安装,你可以选择 Clickhouse Cloud,似乎有一个月的试用期,价格数据如下:
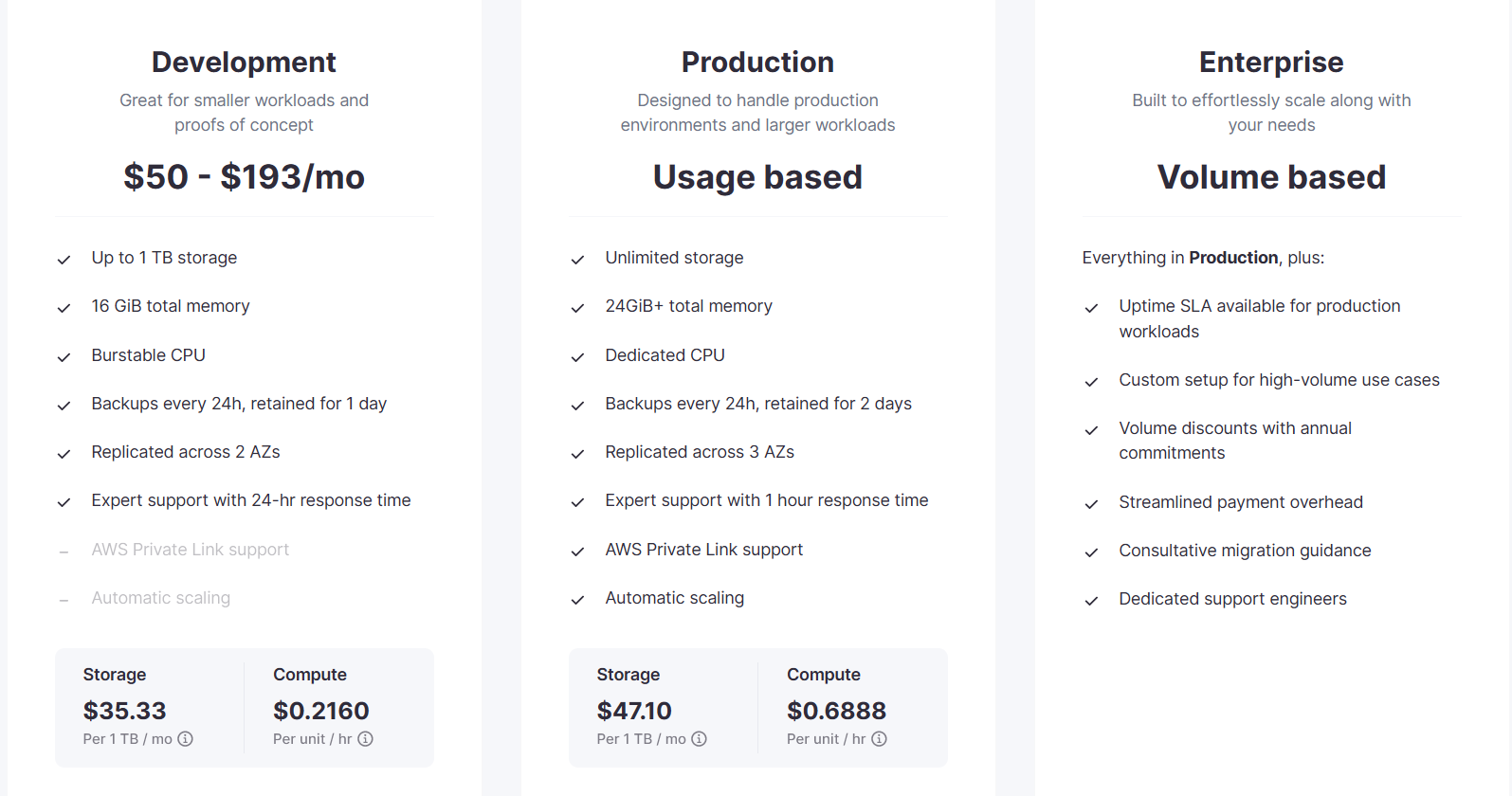
如果你选择此方案,就无需阅读本节。
以下介绍如何在服务器上安装Clickhouse,本部分主要参考了 Clickhouse install,同时本文也会补充一些部分错误的修复方法。
由于笔者并不是一边搭建一边编写的博客,错误的截图并未给出,如果读者遇到错误,可在本文的评论区内留下截图。
安装Clickhouse相当简单,步骤如下:
- 下载脚本并执行
curl https://clickhouse.com/ | sh - 执行安装程序执行此安装程序过程中,请耐心等待,在前期安装过程中,不会有任何输出提示。
sudo ./clickhouse install - 在安装过程的最后,会要求输入默认密码,建议键入复杂密码:读者可能已经发现此处使用了
Creating log directory /var/log/clickhouse-server. Creating data directory /var/lib/clickhouse. Creating pid directory /var/run/clickhouse-server. chown -R clickhouse:clickhouse '/var/log/clickhouse-server' chown -R clickhouse:clickhouse '/var/run/clickhouse-server' chown clickhouse:clickhouse '/var/lib/clickhouse' Enter password for default user:clickhouse:clickhouse用户进行了一系列授权操作,而不是root用户,所以进行应用操作时请使用clickhouse用户 - 启动
clickhouse:sudo clickhouse start - 校验状态:合理的输出如下:
sudo clickhouse status如果您的输出格式与之不符,就说明启动失败。/var/run/clickhouse-server/clickhouse-server.pid file exists and contains pid = 10818. The process with pid = 10818 is running.
一旦启动失败,我们就要进入痛苦的debug阶段,读者可以使用以下命令启动clickhouse:
sudo clickhouse server --config-file /etc/clickhouse-server/config.xml
此处我们指定了启动配置文件
/etc/clickhouse-server/config.xml,否则会使用默认文件,造成启动失败的问题。
此命令会将log输出到终端,读者可以自行查看进行debug,大部分问题都出现在用户权限配置问题上。
下面列出一个仅用于学习的配置方法,为方便使用,我直接将root用户置为clickhouse的管理者,并手动启动服务器,相关命令如下:
- 配置权限:
sudo chown -R root /var/lib/clickhouse /var/log/clickhouse-server /etc/clickhouse-server - 手动启动服务器:
sudo /usr/bin/clickhouse-server --config-file /etc/clickhouse-server/config.xml --pid-file /var/run/clickhouse-server/clickhouse-server.pid --daemon
如果读者遇到其他问题,请直接放在评论区,或加入我的 telegram 讨论群
最后,请放行相关端口,此过程需要配置系统防火墙,读者请根据自身系统来进行配置。读者可尝试开启 http://服务器IP:配置端口/play 查看是否可以配置正确,若配置正确且放行端口正确,会出现如下显示:
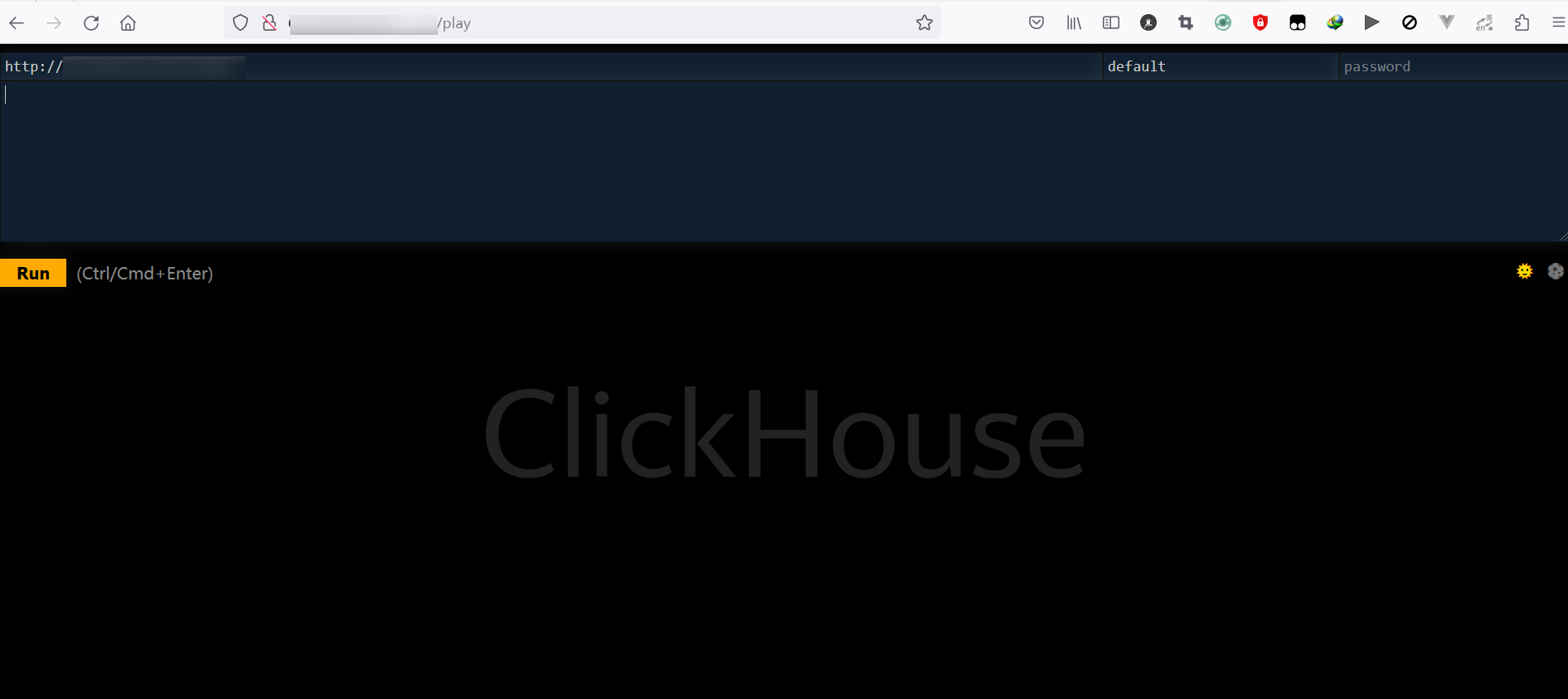
客户端
使用一个优秀的本地SQL客户端会大幅提高工作效率,由于不想在服务端安装一套clickhouse,所以我选择了其他的sql客户端,读者可以查看自己常用的 SQL 客户端是否支持 clickhouse。在本博客中,我使用了 dbeaver 作为客户端,原因在于:
- 社区版开源且免费
- 压缩后体积仅为 110 MB,较为小巧
- 主流操作系统均支持
读者可以根据自己的系统选择下载对应的版本。
关于 dbeaver 与 clickhouse 服务器的链接问题,由于clickhouse的 官方文档 提供了图文并茂的教程,此处不再赘述。
数据导入
数据来源
此处我们使用了0xfast提供的相关服务,读者可提供我写的 智能合约开发效率工具 了解此服务。
简单来说,我们可以提供以下链接获取数据:
- https://eth-uswest.0xfast.com/stream/free?range=latest 获取最新区块数据
- https://eth-uswest.0xfast.com/stream/free?range=1 获取单一区块数据
- https://eth-uswest.0xfast.com/stream/free?range=1-10 获取系列区块数据
我们需要观察数据的具体结构,读者可在任一浏览器内打开https://eth-uswest.0xfast.com/stream/free?range=latest链接,返回值如下:
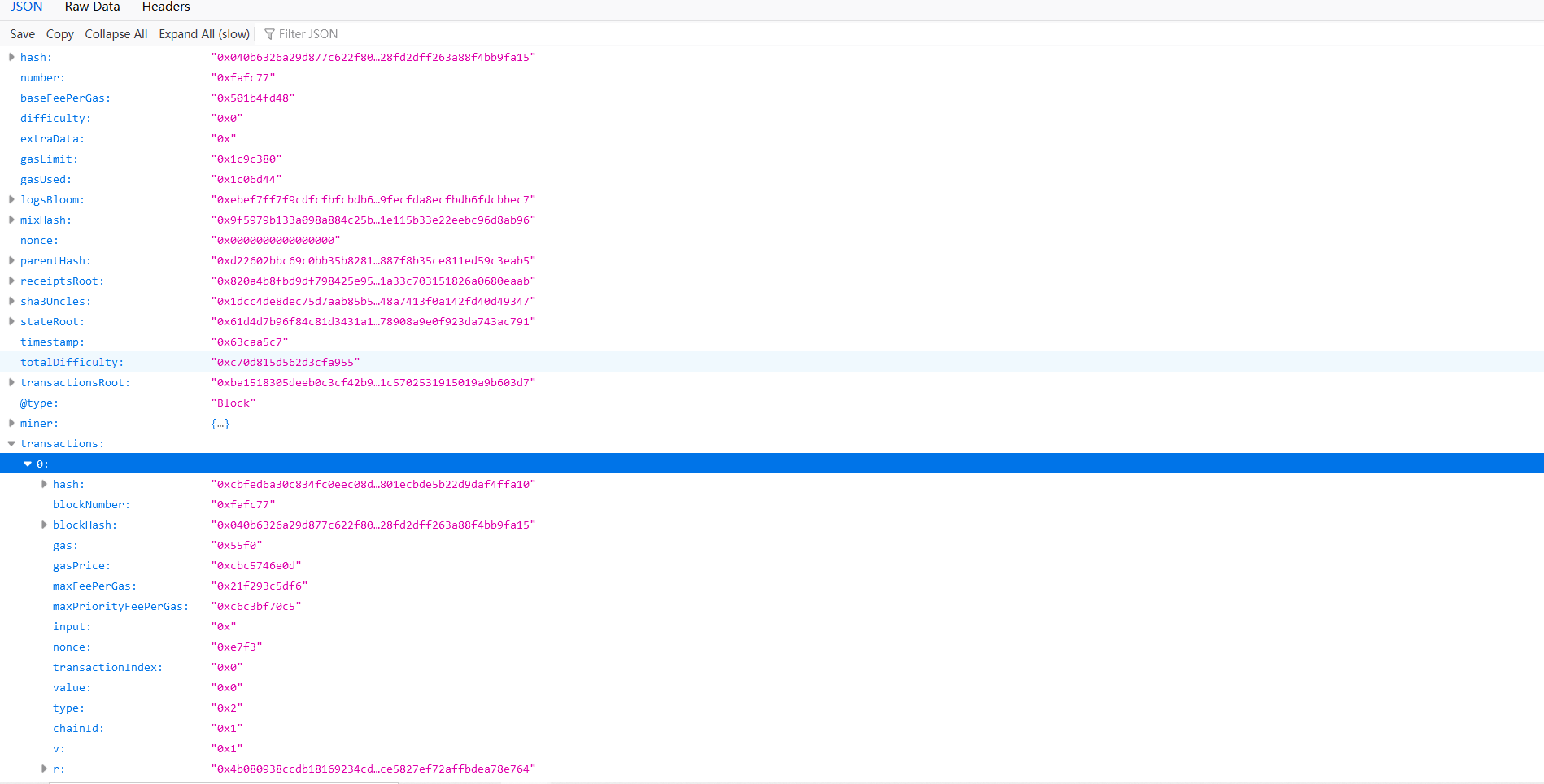
我们会经常查阅此json数据以确定数据导入的格式等。
基础导入
使用以下命令创建临时表格:
CREATE TABLE jsonTemp
(
field String
)
ENGINE = Memory
导入基础数据并将json列表中的每一项解析为一个json行:
INSERT INTO jsonTemp
SELECT * FROM url('https://eth-uswest.0xfast.com/stream/free?range=16448580-16448680', 'JSONAsString', 'field String');
此处使用了clickhouse可以直接使用url作为数据来源的方法,其中JSONAsString可以初步拆分形如[{"a": "b"}, {"a": "c"}],将每一项列为表格中的一行。读者可查阅相关文档了解使用。
最后一项为表结构,事实上,我们将url提供的数据视为一张表,最后的field String用于规定表结构,具体请参考文档
键入以下SQL进行查询:
SELECT * FROM jsonTemp jt LIMIT 5;
获得的结果如下图:
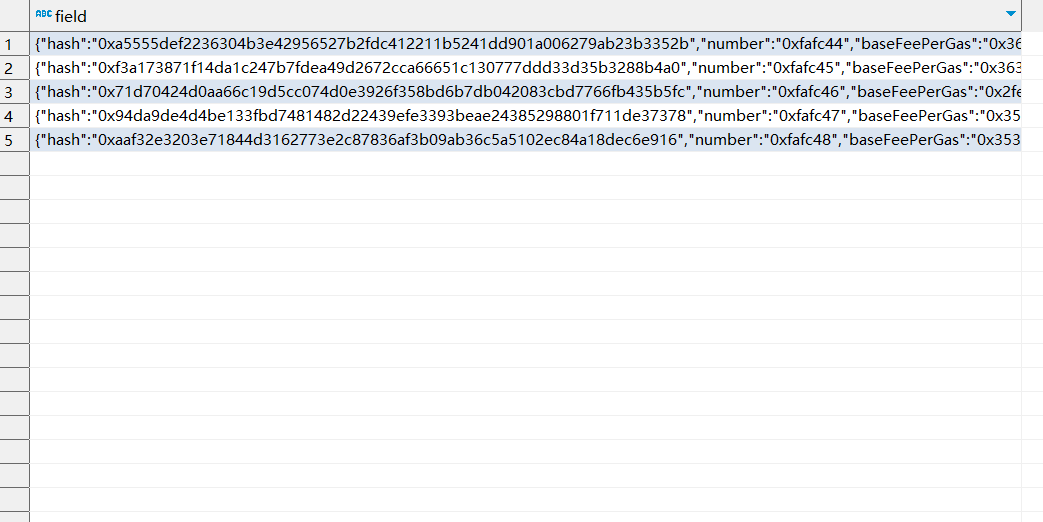
我们发现每一个区块的数据变成了数据库中的一行,这对于我们后期处理是极为重要的。
清洗数据
将数据导入完成后,我们需要对数据进行进一步清洗,这涉及到JSON提取问题,在这一方面的资料一直较少,笔者认为目前分析最好的文章是JSONExtract to parse many attributes at a time,虽然此文章仅给出了一个示例,但对于笔者有很大的启发作用。
目前,clickhouse已支持JSON数据类型,但由于我们的目标是提取出transactions交易列表并进行进一步分析,所以JSON格式并不适用当前方案。对于clickhouse的JSON数据结构的分析,读者可以参考ClickHouse Newsletter April 2022: JSON, JSON, JSON
继续我们的项目,为方便后文的讨论,我们首先进行一些简单的JSON检索。首先,我们尝试获得区块数据中的number和gasUsed:
WITH JSONExtract(
field,
'Tuple(number String, gasUsed String)'
) AS parsed_json
SELECT
tupleElement(parsed_json, 'number') as blockNumber,
tupleElement(parsed_json, 'gasUsed') as gasUsed
FROM jsonTemp jt LIMIT 5;
输出结果如下:
blockNumber|gasUsed |
-----------+---------+
0xfafc44 |0xcd7e49 |
0xfafc45 |0xf3bf2 |
0xfafc46 |0x1c98c36|
0xfafc47 |0xce5243 |
0xfafc48 |0x156b2a8|
其中的核心在于我们构造的Tuple(number String, gasUsed String)字符串,该字符串指示我们需要提取的部分及其数据类型。接下来,我们尝试交易部分,请读者注意构造的提取字符串:
WITH JSONExtract(
field,
'Tuple(transactions Nested(value String, type String))'
) AS parsed_json
SELECT
tupleElement(parsed_json, 'transactions') as tx
FROM jsonTemp jt LIMIT 5;
我们可以使用Nested指示提取列表内的数据,对于很多使用Juila等编程语言进行数据分析的程序员可能对其很熟悉。返回值如下:
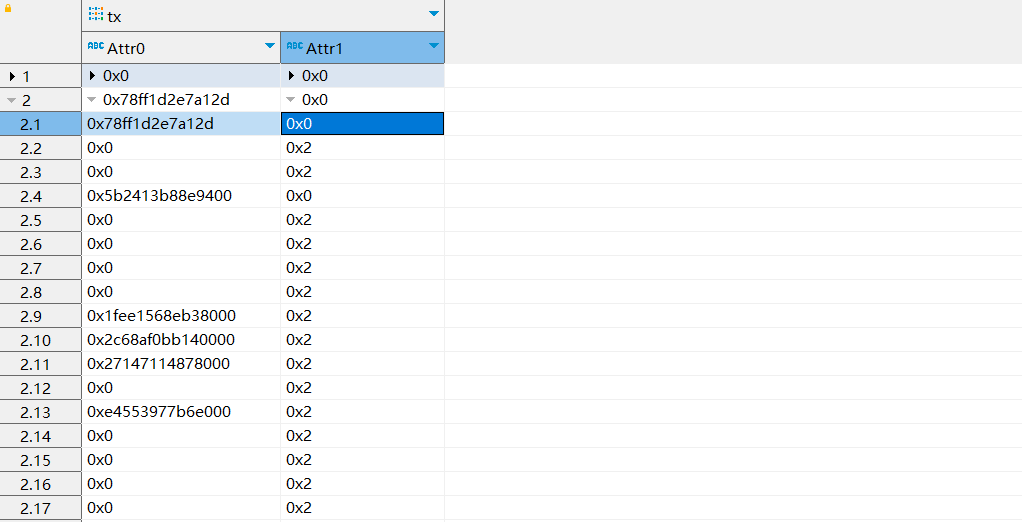
返回值为多层列表嵌套,如下:
['[0x0, 0x0]','[0x1fef237e4e8800, 0x0]','[0x62f1b62f7235000, 0x0]' ...]
['[0x78ff1d2e7a12d, 0x0]','[0x0, 0x2]','[0x0, 0x2]','[0x5b2413b88e9400, 0x0]' ...]
['[0x14d809f18123, 0x2]','[0x68f59ce9e20fd57, 0x2]','[0x1643684073ce, 0x2]' ...]
['[0xb4e5452324, 0x2]','[0x7c9e43a16382df2, 0x0]','[0xc0a2b45ba0, 0x2]' ... ]
['[0x0, 0x2]','[0x2353376319bb8968, 0x2]','[0x85d5077a8c000, 0x0]' ...]
每行为一个区块,内部为嵌套的提取结果。我们希望其中的每一个交易数据转化为数据库中的一行。在clickhouse中,存在一个函数 arrayJoin 可以解决这一问题。修改提取代码,如下:
WITH JSONExtract(
field,
'Tuple(transactions Nested(value String, type String))'
) AS parsed_json
SELECT
arrayJoin(tupleElement(parsed_json, 'transactions')) as tx
FROM jsonTemp jt LIMIT 5;
返回值如下:
tx |
-------------------------+
[0x0, 0x0] |
[0x1fef237e4e8800, 0x0] |
[0x62f1b62f7235000, 0x0] |
[0x1943c033140be000, 0x0]|
[0x1f10c26adf13df8, 0x0] |
我们成功将交易数据分解成立数据库中的一行,虽然现在仍属于嵌套列表的形式。使用另一个函数 untuple 可以解决这一问题,sql代码如下:
WITH JSONExtract(
field,
'Tuple(transactions Nested(value String, type String))'
) AS parsed_json
SELECT
untuple(arrayJoin(tupleElement(parsed_json, 'transactions'))) as tx
FROM jsonTemp jt LIMIT 5;
返回值如下:
tx.1 |tx.2|
------------------+----+
0x0 |0x0 |
0x1fef237e4e8800 |0x0 |
0x62f1b62f7235000 |0x0 |
0x1943c033140be000|0x0 |
0x1f10c26adf13df8 |0x0 |
这与我们的目标的表结构基本一致。接下来,我们编写所需要数据的完整sql代码,此处提取的数据是我所需要的,读者可根据自身需求自行更改:
WITH JSONExtract(
field,
'Tuple(transactions Nested(blockNumber String, value String, type String, gasUsed String, from Tuple(address String), to Tuple(address String)))'
) AS parsed_json
SELECT
untuple(arrayJoin(tupleElement(parsed_json, 'transactions'))) as tx
FROM jsonTemp jt LIMIT 5;
此处我们在提取字符串内部Nested再次嵌套了一个tuple以处理以下字段:
{
...
"from": {
"@type": "Account",
"address": "0x30741289523c2e4d2a62c7d6722686d14e723851"
},
"to": {
"@type": "Account",
"address": "0x525a8f6f3ba4752868cde25164382bfbae3990e1"
}
...
}
请读者注意,此数据也会影响我们后期搭建数据库。
运行上述代码后,返回值如下:
tx.1 |tx.2 |tx.3|tx.4 |tx.5 |tx.6 |
--------+------------------+----+-------+-------------+-------------+
0xfafc44|0x0 |0x0 |0x1f10c|[0x6001a7...]|[0x255538...]|
0xfafc44|0x1fef237e4e8800 |0x0 |0x5208 |[0x05cdb1...]|[0xa20f70...]|
0xfafc44|0x62f1b62f7235000 |0x0 |0x5208 |[0x75e89d...]|[0xbc514e...]|
0xfafc44|0x1943c033140be000|0x0 |0x5208 |[0x75e89d...]|[0x680f68...]|
0xfafc44|0x1f10c26adf13df8 |0x0 |0x5208 |[0xb08cd4...]|[0x0e747e...]|
此处tx.5(即from)和tx.6(即to)都属于tuple类型,这会影响我们创建数据库。
创建数据库
在clickhouse中允许我们创建含有名称的tuple,这正好用于处理上文的 tx.5 和 tx.6 列。
数据库创建代码如下:
CREATE TABLE tx
(
txblockNumber String,
txValue String,
type Enum8('0x0' = 0, '0x1' = 1, '0x2' = 2),
gasUsed String,
txFrom Tuple
(
address String
),
txTo Tuple
(
address String
)
)
ENGINE = MergeTree
ORDER BY txblockNumber
由于考虑长时间存储数据和检索效率,我们使用了MergeTree数据引擎,并将交易类型type设置为Enum8以方便检索。我们可以看到txFrom和txTo均为tuple类型以方便数据输入和分析。
使用
tuple与JSON在功能上基本类似,但前者要求严格的数据顺序,后者则没有要求,在本项目中,使用tuple是合适的。
插入数据的sql代码:
INSERT INTO tx
WITH JSONExtract(
field,
'Tuple(transactions Nested(blockNumber String, value String, type String, gasUsed String, from Tuple(address String), to Tuple(address String)))'
) AS parsed_json
SELECT
untuple(arrayJoin(tupleElement(parsed_json, 'transactions'))) as tx
FROM jsonTemp jt;
结果如下:
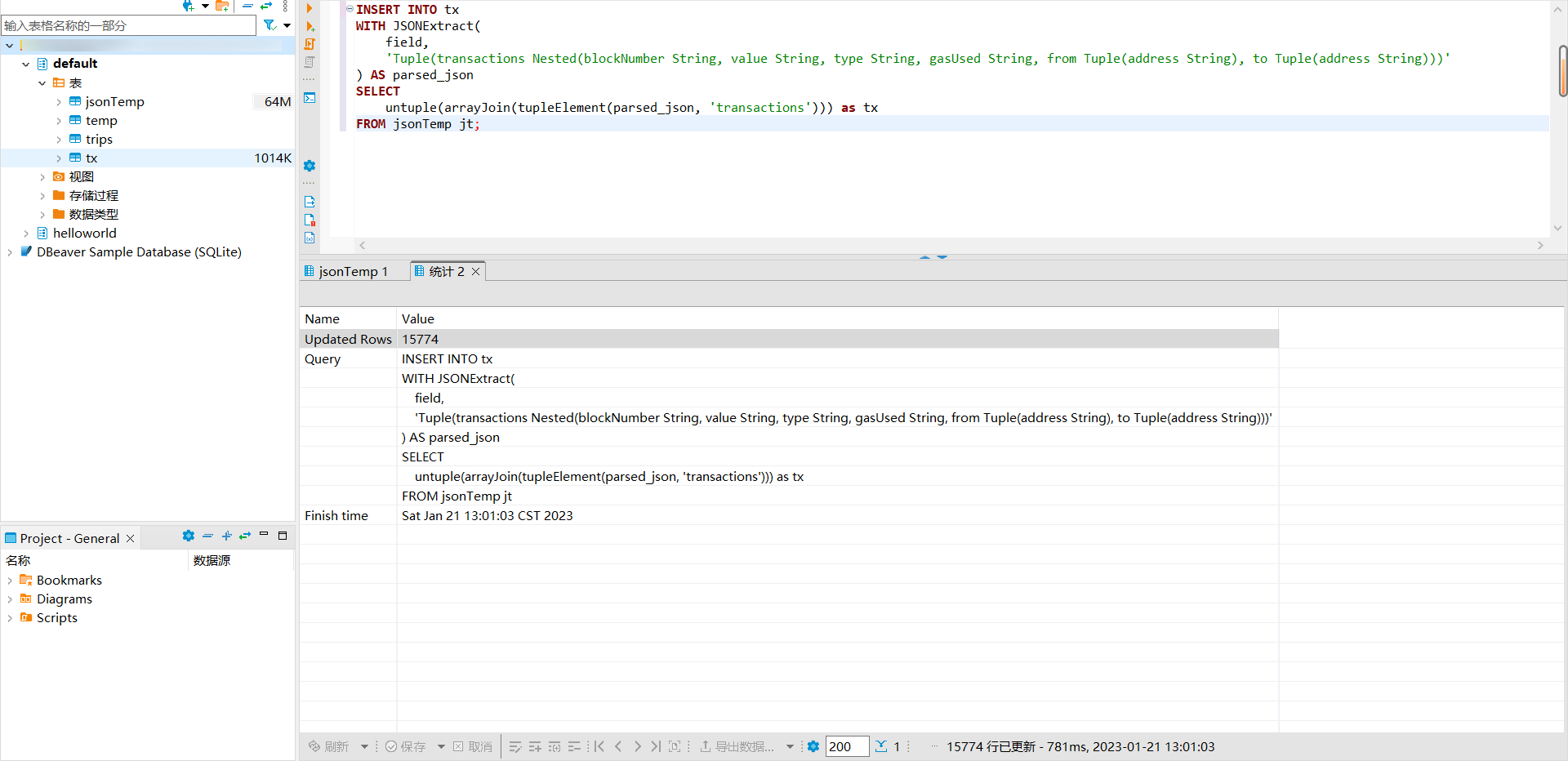
我们写入了 15774 行数据,但数据库仅占用了 1014 KB ,可见数据引擎对数据压缩的影响。
我们在此处仅对数据进行了简单清洗,我们会在此系列文章的后期,增加一些更加复杂的数据抽取和分析
数据分析
由于笔者暂时不知道分析那些内容,本节仅讨论以下问题:
- 交易的
type占比情况 - 各区块的交易数量受
gas的影响情况 - 接受和发起交易最多的地址
- 交易平均转移 ETH 数量
交易类型占比
这是一个比较简单的任务,我们使用的代码如下:
SELECT
COUNT()
FROM tx t
GROUP BY `type`
输出如下:
count()|
-------+
2306|
17|
13451|
显然,目前大部分用户都在使用type 3类型的交易,即符合EIP1559类型的交易。
交易数量影响
在 以太坊机制详解:Gas Price计算 中,我们介绍了baseFee对交易数量的影响并绘制了简单的图像。简单来说,区块内交易数量会在某均值范围内波动,简单来说,就是当前区块交易数量较多时,以太坊会提高交易手续费以抑制下一区块内的交易。在本项目中,我们会再次验证这一事实。
使用的sql代码如下:
SELECT
txblockNumber,
bar(COUNT(), 0, 1250),
SUM(reinterpretAsUInt128(reverse(unhex(`gasUsed`))))
FROM tx
GROUP BY txblockNumber;
输出结果为:

其中的bar用于绘制用于绘制柱状图,其参数格式为bar(x, min, max, width),此处我们省略了width参数。此处我们也使用了reinterpretAsUInt128(reverse(unhex(`gasUsed`)))来转化 16 进制格式的 gasUsed,使用UInt128是为了防止数据溢出。
GROUP BY的用法对于数据分析师而言是一个极为熟悉的函数,此处不再赘述。
显然,以太坊基于交易手续费的策略有效避免了长时间区块链拥堵的问题出现。
交易发起和接受
这其实也是一个较为简单的问题,我们使用以下代码获取交易接受方次数最大的地址:
SELECT
COUNT(),
txTo.address
FROM tx t
GROUP BY txTo.address
ORDER BY COUNT() DESC
LIMIT 5
此处使用ORDER BY进行数据排序,其中DESC代表降序而ASC代表升序。
返回值如下:
count()|txTo.address |
-------+------------------------------------------+
1747|0xdac17f958d2ee523a2206206994597c13d831ec7|
589|0xef1c6e67703c7bd7107eed8303fbe6ec2554bf6b|
540|0x00000000006c3852cbef3e08e8df289169ede581|
485|0xc24f7c14ec350a7dbcc08673aeef4e87c726fe11|
481|0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48|
使用 Etherscan 可以查询到这些地址的标签,交互最多的合约0xdac17f958d2ee523a2206206994597c13d831ec7其实是USDT的代币合约。此处,我们没有详细讨论交易的其他细节,我们可能会在此系列中的下一篇文章内进行分析。
同理,我们可以获得发起交易最多的地址:
count()|txFrom.address |
-------+------------------------------------------+
164|0x21a31ee1afc51d94c2efccaa2092ad1028285549|
148|0xdfd5293d8e347dfe59e90efd55b2956a1343963d|
138|0x28c6c06298d514db089934071355e5743bf21d60|
131|0x46340b20830761efd32832a74d7169b29feb9758|
116|0x56eddb7aa87536c09ccc2793473599fd21a8b17f|
发起交易最多的地址0x21a31ee1afc51d94c2efccaa2092ad1028285549隶属于Binance,用于链上提现。
交易平均价值
注意此处仅讨论了 ETH 转账的数量而不包含其他ERC-20代币,关于ERC-20代币及其他讨论,我们会在后文中讨论。
使用如下代码:
SELECT
AVG(reinterpretAsUInt128(reverse(unhex(txValue)))) as avgTxValue
FROM tx t
此处使用了AVG函数以计算交易均值。
返回如下:
avgTxValue |
---------------------+
546686958851271800000|
此返回值以wei为单位,转换为ETH单位为546.6869588512718,这个过大的数值可能受一些极端值影响,读者可以使用Python或Juila等工具进行归因分析。
拓展思路
此处介绍一些笔者脑洞打开的设想:
Clickhouse集群与kafka流处理拼接已实现高效率数据更新Clickhouse与图数据、大规模机器学习门槛拼接已实现复杂基于链上数据的风控系统- 基于
Clickhouse的区块链浏览器网站
这些设想可用作大数据专业的毕业设计。在本系列的后续文章中,我们会讨论Clickhouse与图数据库的组合以及尝试搭建基于Clickhouse的区块链浏览器。但由于笔者财力有限,对于clickhouse集群搭建等问题则无能为力。
总结
本文重在基础数据的清理,我们没有涉及一些logs等复杂数据的分析,关于一些更加复杂的情况,我们已在 基于Python与GraphQL的链上数据分析实战 进行过过一系列讨论,笔者也计划在本系列未来的文章讨论更加复杂的数据清洗和提取。
本文的一大遗憾是由于编写本文时笔者已完成了Clickhouse的安装,所以在本文中缺失了大量的安装截图,读者可通过评论区反馈您遇到的问题,我会尝试解决并将其纳入正文。
本文最杰出的贡献是完整阐述了在Clickhouse中使用纯SQL导入嵌套(Nested)JSON数据并分析的全流程,介绍此技术的文章在国内外都是缺少的,笔者也是经过数天摸索在完成了这一任务。