概述
总所周知,在 StarkNet Cairo 中,合约需要经过以下步骤进行编译和部署:

在此流程中,我们发现合约首先被编译为 Sierra 这一中间表示层。Sierra 的全称为 Safe Intermediate Representation ,直译为安全中间表示层。在本文中,我们将探讨 Sierra 为什么具有 “安全” 和 “中间表示” 两个特性。
动机
在 Cairo 0 时期,我们使用 Cairo 0 进行合约编程,并将编译后的 CASM 字节码发送给排序器,排序器直接将接受到的 CASM 部署到 StarkNet 网络中。
完成合约部署后,我们继续考察合约调用的情况。假如用户调用 despoit 函数,我们首先讨论调用 Cairo 0 合约的情况,当用户完成交易签名并发送到排序器之后,排序器会根据用户给定的交易费用选择是否运行,假如一切正常完成交易运行后,排序器会生成交易的证明并获得交易的费用。这是较为正常的步骤。但存在一种可能,用户发送的 despoit 函数调用请求中存在错误,交易无法正常执行,此时,排序器无法对错误交易生成证明,这意味着排序器无法获取交易费用。
在以太坊中,这种交易会直接触发
reverted,但节点依旧会将错误交易进行区块打包并正常拿到 gas 费用。
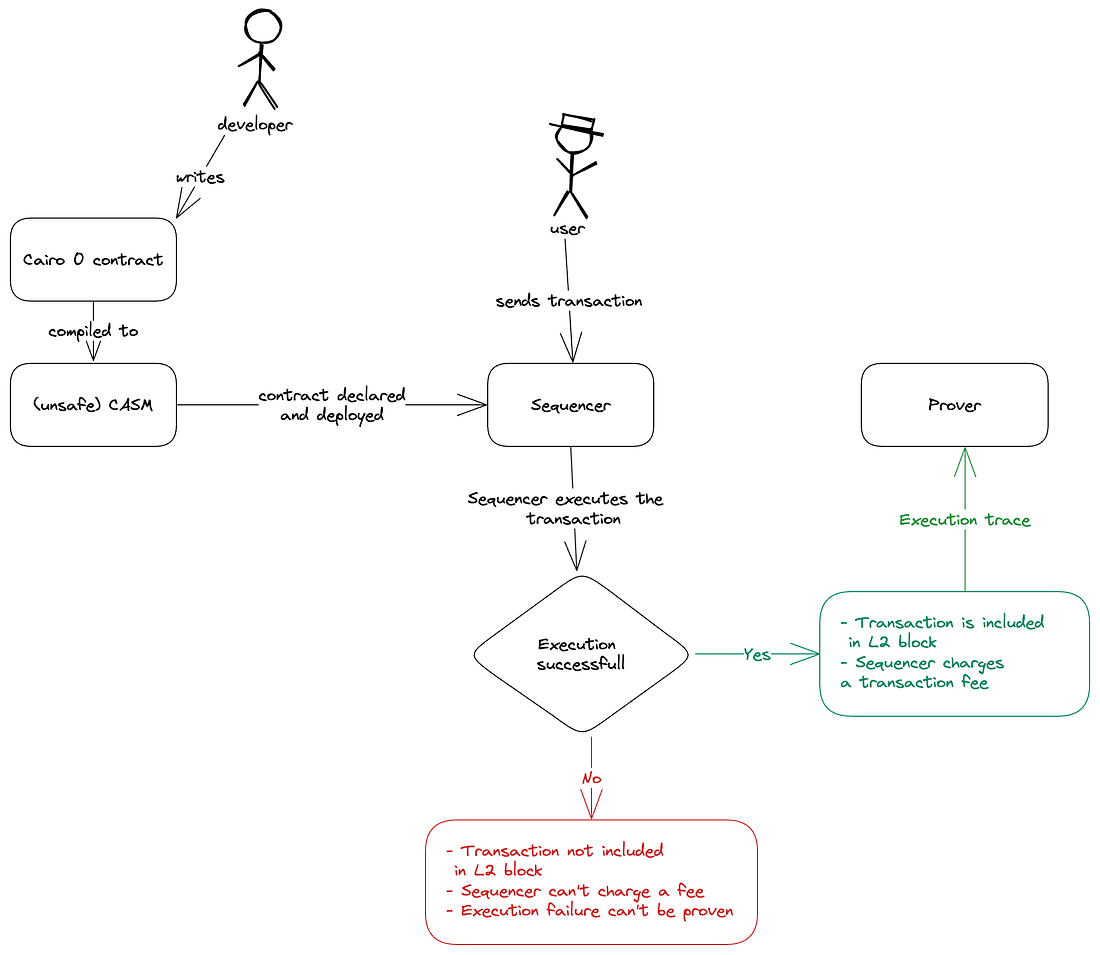
显然,在 StarkNet 中,基于无验证生成无 gas 收入的原则,一旦遇到错误交易,节点无法获得交易费用,这部分交易费用会直接退还给用户。这会导致严重的 DDoS 问题,由于发送错误交易不存在成本,这意味着部分用户可以向排序器高频发送错误交易,这会严重影响排序器的正常运行。
这也导致了一个潜在的审查问题,我们无法确定排序器是因为交易运行失败还是由于审查因素而拒绝某笔交易,因为这些交易都不会显示在链上。
我们需要特别处理无效交易,一个最简单的解决方案是排序器对错误交易也可以生成证明。一个最简单的方法是将会发生错误的代码改写为逻辑分支结构,如下:
假如存在以下代码:
#[external]
fn transfer(to: ContractAddress, amount: u256) -> bool {
let from = get_caller_address();
_balances::write(from, _balances::read(from) - amount);
...
}
我们可以通过以下改写实现无错误出现:
#[external]
fn transfer(to: ContractAddress, amount: u256) -> bool {
let from = get_caller_address();
if _balances::read(from) < amount {
False
}
_balances::write(from, _balances::read(from) - amount);
...
}
函数返回的 bool 值代表当前交易是否为有效的交易,一旦出现错误,错误会从发生的函数位置传播至入口函数。排序器通过入口函数返回的布尔值可以判定当前交易是否需要更新合约状态,进而生成证明获得交易费用。但是开发者很难做到完全执行上述规定,在所有可能产生错误的地方进行 if 判定。这使得引入 Sierra 是必要的。关于 Sierra 是如何实现这一要求的,我们会在后文详细介绍。
Sierra 的最大特点是不包含中断,始终可以返回包含运行是否成功的布尔值(以及某些函数运行成果后返回的正常结果)。这意味着我们需要保证所有的可能导致中断的情况都可以以错误形式抛出,而不是运行时错误而中断。
引入 Sierra 也导致了 StarkNet 合约部署方式的变化,在 Cairo 0 时代,我们将 cairo 0 合约编译为 CASM 直接交给排序器部署,但在 Cairo 1 时代,我们需要将 Sierra 交给排序器,由排序器将其编译为 CASM 进行部署。
显然,Cairo 0 合约不存在对应的 Sierra 代码,我们可以由此区分 Cairo 0 和 Cairo 1 合约
Sierra 设计
在上文中,我们已经明确 Sierra 的目的是为了构造绝对不会运行中断的程序。如果需要避免运行中断,我们需要知道哪些情况会导致运行中断,具体来说包括以下情况:
- 非法指针解引用
- 未定义的操作码
asserts断言,cairo 0 中设计的一种如果不满足条件则直接中断运行的语法。除了用户手动编写的asserts外,还包含一系列 CairoVM 自带的断言,如重复地址写入、不连续地址写入等情况- 无限循环
- 对单一内存地址的多次写入,由于 CairoVM 使用的特殊内存模型,单一内存地址仅能写入一次
除了“安全”这一属性外,Sierra 的开发团队还有以下开发目标:
- 高效编译
- 简单
- 零抽象开销
首先讨论对非法指针解引用的解决方案,Sierra 引入了快照 Snapshots 类型,此类型只能通过已有的变量使用 snapshot_take 获得,这有效避免了空悬指针的出现。
当然,Sierra 也引入了 Rust 中的所有权系统来检测编译过程中的指针安全。
接下来,我们解决内存多次写入的问题,该问题仅出现在数组类型中,Sierra 为了避免该问题出现,引入了 Array<T> 类型并引入了 array_append(Array<T>, T) -> Array<T> 方法实现数组的 append 操作。仅允许用户使用 append 操作数组避免了内存多次写入的情况出现。除此之外,Sierra 引入了 Linear Type System,该系统也是 Rust 使用的系统,该系统的一大特点是任何实例只能使用一次。我们给出一个示例代码:
array_new<felt>() -> ([0]);
felt_const<1>() -> ([1]);
store_temp<felt>([1]) -> ([1]);
array_append<felt>([0], [1]) -> ([2]);
felt_const<1>() -> ([4]);
store_temp<felt>([4]) -> ([4]);
array_append<felt>([2], [4]) -> ([5]);
此处的 [0] 及 [1] 等系列变量可以被认为是变量名(更加准确的说应该为变量 ID )。假如我们在此代码末尾增加对 [0] 的 array_append 操作则会直接报错,因为 Linear Type System 仅允许单个实例被使用一次。
对于未定义的操作码和 asserts 断言问题,前者可以通过编译解决,由于 StarkNet 不允许用户直接上传 CASM 而是上传 Sierra 通过排序器编译为 CASM,所以不可能出现未定义操作码的情况。而 asserts 断言则被修正为分支结构,当不满足断言时会返回错误而不是直接停止代码运行。
除了上述内容外,我们需要讨论一个特殊的字典类型 Dict<K, V> 类型,但此处的字典类型指代码运行过程中的字典类型,由于 CairoVM 要求内存连续,所以我们需要对字典进行 squash_dict(Dict<K, V>) -> () 操作,该操作用于压缩字典,即将字典从非连续状态压缩为内存中的连续状态。对于创建字典,Sierra 提供了 dict_new() -> Dict<K, V> 函数,而检索字典则使用了 dict_get(Dict<K, V>, K) -> (Dict<K, V>, V) 函数。需要注意的是,压缩字典 squash_dict 是生成证明的必要阶段,我们在 Sierra 中保证所有的 Dict<K, V> 都会被 squash_dict。
简单讨论一下为什么需要压缩字典?在 CairoVM 中,我们不允许非连续内存的大量出现,显然对于依赖随机内存访问的字典而言,CairoVM 理论上不会支持。但是 CairoVM 使用了一些迂回手段(
SegmentArena)实现了字典,但最终用户需要压缩字典并写入内存。如果不进行字典压缩操作会导致一些 ZK 证明生成问题
我们发现上述内容没有讨论无限循环的避免方法,接下来,我们介绍一些解决方案:
最简单且直接的方法就是限定交易的 gas 。Sierra 在用户编写的 Cairo 1 中插入了一些关于 gas 的函数,这些函数一般被插入在函数的开头,会比较当前环境内的 gas 与函数体消耗的 gas 直接的关系。如果消耗的 gas 大于当前环境的 gas 会直接抛出一些异常。当然,这些异常会导致函数运行的停止,但采用了上文给出的返回 bool 值的形式。
当然,此处为了避免函数运行的完全失败,即运行失败后无法生成证明,这往往是由于一些特殊操作导致的,最常见的是 Dict<T> 类型需要 squash_dict 后才能进行证明生成,无论是成功运行还是失败运行。但这一步骤需要消耗大量 gas ,所以对于这部分包含 Dict<T> 等类型的函数,其 gas 限额会留有缓冲空间以避免 gas 的完全消耗,该机制被称为 Pre-Charged Costing。
关于 Sierra gas 部分是一个较为复杂的话题,读者可以参考 StarkWare Sessions 23 | Not Stopping at the Halting Problem | Ori Ziv 视频中的内容进行进一步理解。
Sierra 保证程序运行不会失败的另一大方法是使用了 CASM 的安全子集。在 Cairo 程序中,我们会使用一些库函数,这些库函数往往也会在 Sierra 中直接使用,最终被编译为 CASM 字节码。此过程中,Sierra 限定了部分库函数的调用,因为官方实现的库函数中部分未经过审计不一定产生运行不会中断的 CASM 字节码。这具体表现为编译参数中的 libfuncs,具体内容可以参考 Scarb 文档。
重返 Cairo 0
在进行 Sierra 的阅读前,我们首先学习一部分关于 Cairo 0 的内容,事实上这部分内容与 CairoVM 的关系更加突出。
CairoVM 是一个基于 CPU 架构的 STARK 虚拟机,在 CairoVM 里存在以下三种寄存器,分别命名为:
pc指向当前程序运行的指令所在位置ap指向当前空闲的内存地址fp记录函数起始位置,我们会在后文详细介绍
为了更加方便读者直观理解 CairoVM 的相关内容,可以前往 Cairo 0 Playground 进行编写代码和 debug。建议读者在函数运行成功后,开启 debug 模式查看 pc/ap/fp 的具体变化。
我们以如下代码为例进行介绍:
func add(x: felt, y: felt) -> felt {
let z = x + y;
return z;
}
func main() {
let x = 5;
let y = 10;
let z = add(x, y);
let r = y + z;
return ();
}
上述代码应该较为容易理解。给出此段代码的作用只是为了向读者演示 cairo 0 中的函数调用功能是如何运行的。
当代码初始化后,我们可以观察到以下内存情况:
| ... |
+--------------+
12 | 5 | <-- ap, fp
+--------------+
13 | 10 |
+--------------+
14 | 12 |
+--------------+
| ... |
此时 pc 处于 3 位置
步进一次后,我们发现内存变成了以下情况:
| ... |
+--------------+
12 | 5 | <-- fp
+--------------+
13 | 10 | <-- ap
+--------------+
14 | 12 |
+--------------+
| ... |
此处的步进可以展开为以下操作:
[ ap ] = [ ap + 1 ]
[ ap ] = 10
简单来说,我们将 ap 进行了自增来找到下一个空闲位置,并对其进行了赋值操作,将 y 的值进行了写入。
当然,cairo playgroud 的 Debug 界面没有显示这一过程,而是直接显示了所有内存位置的最终结果。
接下来,进行步进,我们进入本节内容的重点,即函数调用问题。我们发现 ap 位置被写入了 12 数值,此数值似乎正好为当前 fp 的值。进一步步进,我们发现内存结构突然发生转变:
| ... |
+--------------+
14 | 12 |
+--------------+
15 | 9 |
+--------------+
16 | 15 | <-- ap, fp
正如上文所述,fp 记录函数起始位置,所以当我们进入函数时,fp 立即更新到了 ap 位置。
事实上,上述内存示意图的含义如下:
| ... |
+--------------+
| old_fp |
+--------------+
| return_pc |
+--------------+
| | <-- ap, fp
+--------------+
| ... |
14 地址记录了上一个函数的起始位置,而 15 位置则记录了返回时需要调用的代码所在的位置,而 16 值则是当前函数的起点,当然也是函数内第一个本地变量的记录点。
首先,为什么需要更新 fp 位置,这是因为 fp 实际上是一个锚点,当我们知道 fp 位置时,可以通过 fp - 1 拿到返回时需要运行的代码,更进一步可以提供 fp - 2 返回上一级。
到此,我们可以结束对 cario 0 的进一步研究,因为 palyground 的编译器可能没有内置优化功能,导致实际情况下的代码运行与 playground 的 debug 给出的情况可能有所不同。
Sierra 解析
为了更加深入了解 Sierra ,我们准备直接实战阅读部分 Cairo 程序的 Sierra 字节码。
使用以下命令创建 helloSierra 项目:
scarb new helloSierra
在项目内增加 cairo_project.toml 文件并写入以下内容:
[crate_roots]
helloSierra = "src"
修改 Scarb.toml ,填写以下内容:
[package]
name = "helloSierra"
version = "0.1.0"
[lib]
sierra = true
将 lib.cairo 中的 fib 函数删除并写入以下内容:
fn add(a: felt252, b: felt252) -> felt252 {
a + b
}
在项目根目录中运行 scarb build 命令,我们可以在 target/dev/helloSierra.sierra 内获得以下输出:
// 类型声明
type felt252 = felt252 [storable: true, drop: true, dup: true, zero_sized: false];
// 库函数
libfunc felt252_add = felt252_add;
libfunc store_temp<felt252> = store_temp<felt252>;
// 语句
felt252_add([0], [1]) -> ([2]); // 0
store_temp<felt252>([2]) -> ([3]); // 1
return([3]); // 2
// 用户自定义函数
helloSierra::add@0([0]: felt252, [1]: felt252) -> (felt252);
我们可以发现如下语法规则:
- 变量使用
[1]和[2]形式存储 - 语句遵循
<libfunc>(<inputs>) -> (<outputs>);的形式,如felt252_add([0], [1]) -> ([2]); - 函数声明与语句分离,函数声明通过索引与语句相关联,如
helloSierra::add@0中的@0即意味着从第一个语句开始执行函数,直到执行到return意味着函数结束
有了以上基础,我们尝试使用更加复杂的类型进行 add 操作:
fn add(a: u8, b: u8) -> u8 {
a + b
}
此处的 + 会调用 corelib(即 cairo 标准库) 中的以下函数:
extern fn u8_overflowing_add(lhs: u8, rhs: u8) -> Result<u8, u8> implicits(RangeCheck) nopanic;
impl U8Add of Add<u8> {
fn add(lhs: u8, rhs: u8) -> u8 {
u8_overflowing_add(lhs, rhs).expect('u8_add Overflow')
}
}
注意此处的 u8_overflowing_add 是一个 extern 函数,没有给出 cairo 实现,这一类函数在 corelib 中大量存在,这些函数是 StarkNet 的 内置函数 。这些内置函数具有相当高效率的专用证明电路,使用此类函数进行计算将大幅度提高证明生产的效率。
如果读者希望获得更多关于内置函数的细节,可以参考 内置函数与动态布局:高效证明工作的必经之路 文章
此处,我们也可以看到函数声明内存在 implicits(RangeCheck) nopanic 标识。其中 implicits(RangeCheck) 代表此函数使用了 RangeCheck 功能,简单来说,RangeCheck 是一个用于验证数据是否处于某一个范围的内置函数。该函数在 cairo 0 的极早期版本内就已经存在。更多关于此函数的内容,请参考 Cairo 0 文档。
注意,此处的 implicits(RangeCheck) 对函数的参数存在实质影响,实际上 u8_overflowing_add 的参数定义如下:
fn u8_overflowing_add(range_check_ptr, lhs: u8, rhs: u8) -> Result<u8, u8>
此处的 range_check_ptr 是 RangeCheck 函数对应的函数指针。简单来说,implicits(RangeCheck) 的作用就是指明函数需要 RangeCheck 功能并为函数隐式增加 range_check_ptr 的参数。
而 nopanic 则说明此函数永远不会报错中断 Cairo VM 运行,这也是 Sierra 的最重要的目标。
进一步观察,我们可以发现 u8_overflowing_add 返回了 Result<u8, u8> 类型,此类型的泛型定义如下:
#[derive(Copy, Drop, Serde, PartialEq)]
enum Result<T, E> {
Ok: T,
Err: E,
}
该类型是实现 nopanic 的核心,当函数运行出现错误时,函数仍会返回数据,但此数据是经过包装的,我们可以使用 unwarp 等方法进行解包装,关于 Result 类型的所有 trait 可以参考:
trait ResultTrait<T, E> {
fn expect<impl EDrop: Drop<E>>(self: Result<T, E>, err: felt252) -> T;
fn unwrap<impl EDrop: Drop<E>>(self: Result<T, E>) -> T;
fn expect_err<impl TDrop: Drop<T>>(self: Result<T, E>, err: felt252) -> E;
fn unwrap_err<impl TDrop: Drop<T>>(self: Result<T, E>) -> E;
fn is_ok(self: @Result<T, E>) -> bool;
fn is_err(self: @Result<T, E>) -> bool;
}
简单来说,u8 的加法就是对内置函数 u8_overflowing_add 的包装,使其在错误时抛出错误信息且可以正常退出运行。
此部分的 Sierra 代码如下:
store_temp<RangeCheck>([0]) -> ([5]); // 0
store_temp<u8>([1]) -> ([6]); // 1
store_temp<u8>([2]) -> ([7]); // 2
function_call<user@core::integer::U8Add::add>([5], [6], [7]) -> ([3], [4]); // 3
enum_match<core::panics::PanicResult::<(core::integer::u8,)>>([4]) { fallthrough([8]) 12([9]) }; // 4
branch_align() -> (); // 5
struct_deconstruct<Tuple<u8>>([8]) -> ([10]); // 6
struct_construct<Tuple<u8>>([10]) -> ([11]); // 7
enum_init<core::panics::PanicResult::<(core::integer::u8,)>, 0>([11]) -> ([12]); // 8
store_temp<RangeCheck>([3]) -> ([13]); // 9
store_temp<core::panics::PanicResult::<(core::integer::u8,)>>([12]) -> ([14]); // 10
return([13], [14]); // 11
branch_align() -> (); // 12
enum_init<core::panics::PanicResult::<(core::integer::u8,)>, 1>([9]) -> ([15]); // 13
store_temp<RangeCheck>([3]) -> ([16]); // 14
store_temp<core::panics::PanicResult::<(core::integer::u8,)>>([15]) -> ([17]); // 15
return([16], [17]); // 16
u8_overflowing_add([0], [1], [2]) { fallthrough([3], [4]) 23([5], [6]) }; // 17
...
enum_match<core::result::Result::<core::integer::u8, core::integer::u8>>([0]) { fallthrough([2]) 51([3]) }; // 44
...
helloSierra::add@0([0]: RangeCheck, [1]: u8, [2]: u8) -> (RangeCheck, core::panics::PanicResult::<(core::integer::u8,)>);
core::integer::U8Add::add@17([0]: RangeCheck, [1]: u8, [2]: u8) -> (RangeCheck, core::panics::PanicResult::<(core::integer::u8,)>);
core::result::ResultTraitImpl::<core::integer::u8, core::integer::u8>::expect::<core::integer::u8Drop>@44([0]: core::result::Result::<core::integer::u8, core::integer::u8>, [1]: felt252) -> (core::panics::PanicResult::<(core::integer::u8,)>);
为了简化讨论,我们省略了大部分非核心代码,包括标准库的 core::integer::U8Add::add 的具体实现,而仅聚焦于我们编写的 helloSierra::add 函数。我们再次给出此函数的定义:
fn add(a: u8, b: u8) -> u8 {
a + b
}
正如上文所述,此函数的底层调用 u8_overflowing_add 是存在隐性参数 RangeCheck 的,所以我们的函数入口出现了 RangeCheck 参数。进一步观察,我们会发现 RangeCheck 参数会在函数调用过程中被传递,这是因为很多函数都依赖此功能,通过入口函数传入 RangeCheck 函数指针是一个比较优雅的解决方案。
Sierra 的前三行代码在处理输入值,将传入的参数使用 store 改写到了 [5] [6] 和 [7] 位置,而后调用 core::integer::U8Add::add 函数使用 [5] [6] 和 [7] 作为参数进行 u8 的加法计算,最后将结果写入 [3] 和 [4]。
可能有读者好奇,为什么不直接使用用户传入的 [0] [1] 和 [2] 参数直接调用函数进行计算?这涉及到优化问题,如上文所述,在 CairoVM 中,对于大部分变量都是使用 fp 进行定位的,这意味着变量距离 fp 越近,被寻址的难度就越小。如下图所示:

显然,如果我们将 core::integer::U8Add::add 的返回值写入 [3] 和 [4] 位置,则会大大降低后期使用 core::integer::U8Add::add 函数返回值的难度。在 Sierra 中,大部分函数调用都采用了返回值写入在调用函数参数前的习惯,比如 core::integer::U8Add::add 调用 user@core::result::ResultTraitImpl::<core::integer::u8, core::integer::u8>::expect::<core::integer::u8Drop> 函数也使用此优化方法:
function_call<user@core::result::ResultTraitImpl::<core::integer::u8, core::integer::u8>::expect::<core::integer::u8Drop>>([13], [14]) -> ([12]); // 30
根据 core::integer::U8Add::add 的函数定义,即 core::integer::U8Add::add@17([0]: RangeCheck, [1]: u8, [2]: u8) -> (RangeCheck, core::panics::PanicResult::<(core::integer::u8,)>);
,我们可以判定此处的 [3] 为 RangeCheck ,而 [4] 为 core::panics::PanicResult::<(core::integer::u8,)> 类型,该类型实际上可以展开:
enum Result<T, E> {
Ok: T,
Err: E,
}
当我们拿到 core::integer::U8Add::add 的返回值后,我们使用了 enum_match 进行了匹配操作。
enum_match<core::panics::PanicResult::<(core::integer::u8,)>>([4]) { fallthrough([8]) 12([9]) }; // 4
此处使用 enum_match 进行了 core::panics::PanicResult::<(core::integer::u8,)>> 结果的模式匹配,当 [4] 不包含错误时,代码继续按顺序向下运行,同时将结果写入 [8] 位置,此处涉及到上文提及的 Linear Type System ,即单个变量只能使用一次;但如果 [4] 包含错误,则跳转至 12 行继续运行,同时将 [4] 存储到 [9] 中。
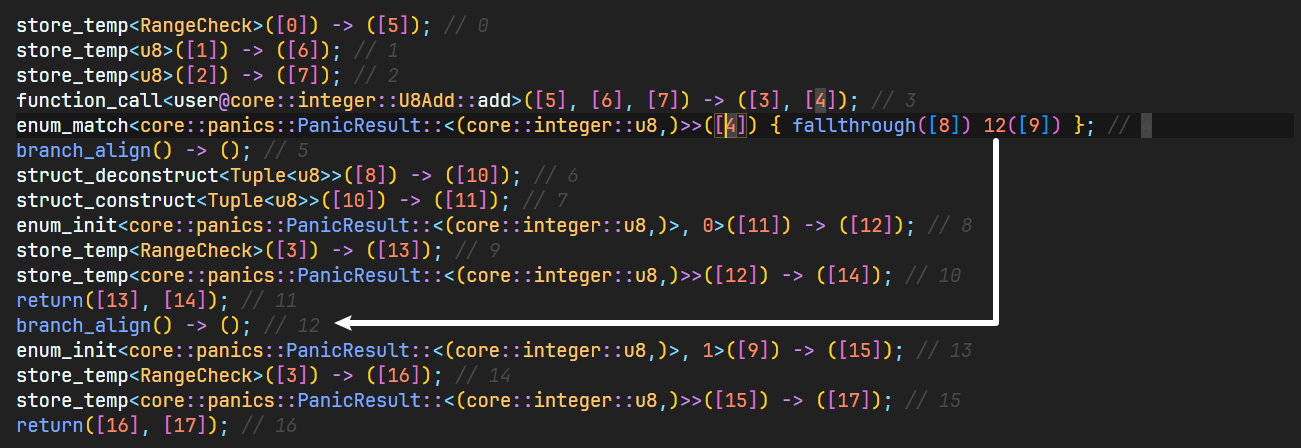
我们可以看到第 12 行代码处存在 branch_align 用于标识跳转终点。
此处可能有读者好奇
enum_match如何区分Result内是否包含错误?Cairo 采用了类似Rust的处理方法,即增加标志位,通过标志位判定Result为Ok或是Err类型,当标志位为 1 时,代表返回结果包含错误
我们首先分析 [4] 不包含错误时,会执行以下 Sierra 代码:
branch_align() -> (); // 5
struct_deconstruct<Tuple<u8>>([8]) -> ([10]); // 6
struct_construct<Tuple<u8>>([10]) -> ([11]); // 7
enum_init<core::panics::PanicResult::<(core::integer::u8,)>, 0>([11]) -> ([12]); // 8
store_temp<RangeCheck>([3]) -> ([13]); // 9
store_temp<core::panics::PanicResult::<(core::integer::u8,)>>([12]) -> ([14]); // 10
return([13], [14]); // 11
此处的 [8] 即为传入的 u8 加法的结果 [4] 。然后我们看到了迷惑操作解构 struct_deconstruct<Tuple<u8>> 后合成 struct_construct<Tuple<u8>>。这个迷惑操作的底层是为了更换当前变量的存储位置,使其越过 [9] 这一被占用的位置。但是为什么采用解构和重构的方法?这是因为 Sierra 没有提供 store_temp<Tuple<u8>> 这类函数,我们只能手动解构然后再另一个位置重构实现变量位置的转移。
使用这种方法进行结构体数据类型的转移是有必要的,因为大部分结构体都是用户进行自定义的,很难自动生成转移函数,而使用手动解构再重构反而是一种更加快捷且安全的方法
接下来,我们使用 enum_init 将运算结果包装为 core::panics::PanicResult::<(core::integer::u8,)>。此操作正是保证 Sierra 不会中断运行的核心操作。我们将所有函数的返回值包装为 core::panics::PanicResult 类型,正如上文所述,该类型定义如下:
enum Result<T, E> {
Ok: T,
Err: E,
}
我们可以将发生的错误进行包装返回,而不是直接中断函数运行。
然后,我们转移 RangeCheck 指针位置,将其存储至 [13] 位置。最后,我们将存储的结果 [12] 使用 store_temp 函数转移至 [14] 位置。这一操作的目的是为了后期返回,因为返回值要求为 RangeCheck, core::panics::PanicResult::<(core::integer::u8,)>
接下来,我们分析另一个分支,此分支会在 u8 加法溢出后执行:
branch_align() -> (); // 12
enum_init<core::panics::PanicResult::<(core::integer::u8,)>, 1>([9]) -> ([15]); // 13
store_temp<RangeCheck>([3]) -> ([16]); // 14
store_temp<core::panics::PanicResult::<(core::integer::u8,)>>([15]) -> ([17]); // 15
return([16], [17]); // 16
此处的 [9] 实际上是 u8 加法溢出的报错信息,我们使用 enum_init<core::panics::PanicResult::<(core::integer::u8,)>, 1> 将其包装为错误返回结构体。此处我们可以看到当 enum_init<core::panics::PanicResult::<(core::integer::u8,)>, 0> 进行包装说明返回值为正常结果,而使用 enum_init<core::panics::PanicResult::<(core::integer::u8,)>, 1> 则说明返回值为错误报错.
后续操作与正常返回类似,主要进行内存位置迁移和返回。
通过以上可能包含错误的 Sierra 代码分析可以发现,Sierra 构造的 绝对不会运行中断的程序 的基础在于 core::panics::PanicResult 类型,基于此类型可以同时包装错误和正确结果的性质,我们可以在每个函数内生成错误处理函数,当函数执行发生错误时,将错误向上传播最终返回给调用者。在这个过程中,gas 记录模块也可以正常运行记录函数消耗的 gas 以实现对错误交易收费的目标。而 STARK 证明也可以正常生成,也实现了错误交易可生成证明的需求。
Why Cairo
本节是更加切合 Cairo 开发者的一节,正如本节标题所示,本节内容主要讨论一些 cairo 语法的底层内容。本节部分内容参考了 Under the hood of Cairo 1.0: Exploring Sierra Part 3: Become a better Cairo developer with Sierra 。
注意 Sierra 的给出的变量ID ,如 [1] 等其实并不代表在内存中的真实排布,很多情况下,这些变量 ID 只是一个用于所有权分析的工具。
可变引用 Mutable References
给出以下代码:
fn main() -> felt252 {
let mut x = 1;
increment(ref x);
x
}
fn increment(ref x: felt252) {
x += 1;
}
我们在 increment 函数中使用 ref 对变量 x 进行了标识,说明该函数接受可变引用,且会在函数内部对 x 的值进行自增操作。我们使用 scarb build 将其编译为 sierra 代码,如下:
felt252_const<1>() -> ([0]); // 0
store_temp<felt252>([0]) -> ([3]); // 1
function_call<user@helloSierra::increment>([3]) -> ([1], [2]); // 2
drop<Unit>([2]) -> (); // 3
store_temp<felt252>([1]) -> ([4]); // 4
return([4]); // 5
felt252_const<1>() -> ([1]); // 6
felt252_add([0], [1]) -> ([2]); // 7
struct_construct<Unit>() -> ([3]); // 8
store_temp<felt252>([2]) -> ([4]); // 9
store_temp<Unit>([3]) -> ([5]); // 10
return([4], [5]); // 11
helloSierra::main@0() -> (felt252);
helloSierra::increment@6([0]: felt252) -> (felt252, Unit);
首先,我们看函数定义,发现 increment 的定义被展开为 helloSierra::increment@6([0]: felt252) -> (felt252, Unit); 。此处的 Unit 参数实际上无返回值函数的默认返回值。简单来说,Sierra 中所有函数都会存在返回值,如果我们在 cairo 中没有进行返回值定义,则会返回 Unit 作为默认值。但是此处除了默认增加的 Unit 外,还增加了 felt252 作为返回值。这就是 ref 的真实作用。当函数某一参数存在 ref 标识时,Sierra 会自动将此参数列为返回值。
事实上,当我们调用使用 ref 参数时,我们只是将参数传入函数并将返回的新的参数存储以取代原参数。
快照 Snapshots
快照一般用于数组 Array<T> 和结构体等类型中,可以认为快照属于一种不可变引用。不可变引用往往会在关于“所有权”的场景下使用。关于 Cairo 的所有权规则,读者可以参考 What Is Ownership? 文章。简单来说,一个变量符合以下所有权规则:
- 每一个值都对应一个变量作为所有者
- 每一个值有且仅有一个所有者
- 当所有者离开作用域后,值会被释放
事实上,在 Cairo 中,我们无需太过于关心所有权规则,Rust 的所有权规则对应的 Rust 无 GC 的设计而且与堆栈有较大关系,但在 Cairo 中,没有堆栈设计。Cairo 采用所有权规则很大程度上只是使用 Linear Type System 的副作用,事实上是为了避免内存的重复写入。
在大部分情况下,开发者只需要记住一个复杂变量,如数组或结构体直接作为函数参数后无法使用第二次,如下包含错误的代码:
fn main(){
let mut x = array![1, 2];
error_calculate_length(x);
x.append(3);
}
fn error_calculate_length(x: Array<felt252>) -> u32 {
x.len()
}
此处 x.append(3); 会出现报错,因为 error_calculate_length 已经消耗了 x 变量。
可能有读者好奇,为什么 flet252 等变量没有这个特性,并拿出来以下代码:
fn main() -> felt252 {
let mut x = 20;
error_add(x);
x + 1
}
fn error_add(x: felt252) -> felt252 {
x + 1
}
与上文给出的存在报错的代码不同,此处并没有报错。这是为什么?其实可以通过此代码对应的 Sierra 代码获得原因,Sierra 代码如下:
felt252_const<20>() -> ([0]); // 0
dup<felt252>([0]) -> ([0], [2]); // 1
store_temp<felt252>([2]) -> ([2]); // 2
function_call<user@helloSierra::error_add>([2]) -> ([1]); // 3
...
是因为在调用函数前进行了 dup 操作,复制了一份变量用于函数调用。在 Cairo 代码层面上而言,是因为 flet252 类型实现了 Clone 这个 trait ,会在进行函数调用时会自动复制,所以无需担心所有权问题。
继续介绍 Array 的报错问题,一个修复版本可以参考以下代码:
use core::array::ArrayTrait;
fn main() -> u32 {
let mut x = array![1, 2];
calculate_length(@x);
x.append(3);
calculate_length(@x)
}
fn calculate_length(x: @Array<felt252>) -> u32 {
x.len()
}
此处我们将 calculate_length 的参数变量 @Array<felt252> 类型,该类型是 Array<felt252> 的引用。我们给出上述代码的 Sierra 代码:
array_new<felt252>() -> ([0]); // 0
felt252_const<1>() -> ([1]); // 1
store_temp<felt252>([1]) -> ([1]); // 2
array_append<felt252>([0], [1]) -> ([2]); // 3
felt252_const<2>() -> ([3]); // 4
store_temp<felt252>([3]) -> ([3]); // 5
array_append<felt252>([2], [3]) -> ([4]); // 6
snapshot_take<Array<felt252>>([4]) -> ([5], [6]); // 7
store_temp<Snapshot<Array<felt252>>>([6]) -> ([6]); // 8
array_len<felt252>([6]) -> ([7]); // 9
drop<u32>([7]) -> (); // 10
felt252_const<3>() -> ([8]); // 11
store_temp<felt252>([8]) -> ([8]); // 12
array_append<felt252>([5], [8]) -> ([9]); // 13
snapshot_take<Array<felt252>>([9]) -> ([10], [11]); // 14
drop<Array<felt252>>([10]) -> (); // 15
store_temp<Snapshot<Array<felt252>>>([11]) -> ([11]); // 16
array_len<felt252>([11]) -> ([12]); // 17
store_temp<u32>([12]) -> ([13]); // 18
return([13]); // 19
helloSierra::main@0() -> (u32);
此处没有展示 calculate_length 函数的 Sierra 实现,因为该函数由于较为简单,所以编译器进行了内联处理。我们可以看到实现不可变引用的核心函数为 snapshot_take<Array<felt252>>,此函数返回值为可变数组 [5] 与数组快照 [6],我们可以使用前者继续进行原数组的操作,也可以使用后者进行原数组的只读操作。
我们可以发现数组快照 @Array<felt252> 存在特殊的 store_temp<Snapshot<Array<felt252>>> 方法,与其他函数不同,此函数调用后变量在内存的位置不会改变。随后我们调用 array_len<felt252> 方法获得数组快照的长度。读者可以发现 @Array<felt252> 似乎可以使用 Array<felt252> 的方法,事实也正是如此,我们甚至可以执行以下代码:
@x.append(3);
上述代码会被编译为:
felt252_const<3>() -> ([8]); // 11
store_temp<felt252>([8]) -> ([8]); // 12
array_append<felt252>([5], [8]) -> ([9]); // 13
与正常的 Array<felt252> 执行追加的方法是一致的。简单来说,@Array<felt252> 就是将原有的 Array<felt252> 进行了复制操作,并使用复制出的数组进行函数调用操作以实现在不进行所有权转移的情况下进行函数调用操作。
在 Cairo 中,存在一个几乎与 @Array<felt252> 等价的类型,即 Span<felt252> ,该类型定义如下:
struct Span<T> {
snapshot: @Array<T>
}
该类型几乎具有 Array<felt252> 的全部特性,除了无法使用 append 方法。我们给出一段使用 Span<T> 类型的代码:
fn main() -> u32 {
let mut x = array![1, 2, 3];
calculate_length(x.span());
x.append(3);
calculate_length(x.span())
}
fn calculate_length(x: Span<felt252>) -> u32 {
x.len()
}
其对应的部分 Sierra 代码如下:
...
snapshot_take<Array<felt252>>([6]) -> ([7], [8]); // 10
struct_construct<core::array::Span::<core::felt252>>([8]) -> ([9]); // 11
struct_deconstruct<core::array::Span::<core::felt252>>([9]) -> ([10]); // 12
store_temp<Snapshot<Array<felt252>>>([10]) -> ([10]); // 13
array_len<felt252>([10]) -> ([11]); // 14
drop<u32>([11]) -> (); // 15
...
此处省略了 x 的初始化流程,此处的 [6] 即为初始化后的数组 x ,此处的 12/13/14 对应了我们编写的 calculate_length 函数,由于该函数较为简单,所以 Sierra 编译器进行自动的内联。
我们可以发现当 Span<felt252> 进入函数后会立即执行 struct_deconstruct<core::array::Span::<core::felt252>> 操作对其进行解引用操作取出其中的 @Array<T> 并使用 store_temp<Snapshot<Array<felt252>>> 进行存储。
实际上,Span<felt252> 就是等价于 @Array<252>,但需要注意的是标准库内对 Span<felt252> 实现了较多的 trait,大部分情况下,我们可以看到使用 Span<T> 是多于 @Array<T> 类型的。
关于 Span<T> 所具有具体 trait ,可以参考 标准库。
在某些场景下,我们可以需要 @felt252 类型,如 test::test_utils::assert_eq 函数,该函数定义如下:
#[inline]
fn assert_eq<T, +PartialEq<T>>(a: @T, b: @T, err_code: felt252) {
assert(a == b, err_code);
}
原因在于此函数 assert_eq 可能会接受数组等类型的未实现 Clone 的变量,所以使用 @T 可以避免很多所有权问题,这样带来的后果就是,我们需要对 felt252 等类型也使用其快照形式。
此处的
T, +PartialEq<T>是要求输入此函数的类型需要使用PartialEq的trait,Cairo 内的原生数据类型都已经实现了此 trait,对于用户定义到结构体,可以使用#[derive(PartialEq)]创建默认实现
在此处,我们给出一个简单的总结:
- 对函数进行按值传参会导致值的所有权转移,但对于
felt252等简单类型无需考虑 - 如果不希望所有权转移且确定函数不会修改值的内容,使用
@快照传参 - 如果不希望所有权转移且确定函数会修改值的内容,使用
ref传参
解引用 Desnap Operator
当我们使用结构体时,我们可能会以快照的形式将其传入函数,但我们往往需要获取结构体内某个字段的具体值,此时我们需要引入解引用的操作符。
#[derive(Drop)]
struct Rectangle {
height: u64,
width: u64,
}
fn main() -> u64 {
let rec = Rectangle { height: 3, width: 10 };
let area = calculate_area(@rec);
area
}
fn calculate_area(rec: @Rectangle) -> u64 {
*rec.height * *rec.width
}
此处我们使用 #[derive(Drop)] 为结构体自动派生 trait,派生出的 Drop 是为了 Cairo 可以在 Rectangle 离开作用域后进行自动删除。Drop 是最基本的 trait 之一,任何结构体似乎都需要实现此 trait,否则会出现报错。
dup<helloSierra::Rectangle>([1]) -> ([1], [2]); // 21
struct_deconstruct<helloSierra::Rectangle>([2]) -> ([3], [4]); // 22
drop<u64>([4]) -> (); // 23
rename<u64>([3]) -> ([5]); // 24
struct_deconstruct<helloSierra::Rectangle>([1]) -> ([6], [7]); // 25
drop<u64>([6]) -> (); // 26
rename<u64>([7]) -> ([8]); // 27
store_temp<RangeCheck>([0]) -> ([11]); // 28
store_temp<u64>([5]) -> ([12]); // 29
store_temp<u64>([8]) -> ([13]); // 30
...
以上片段截取了 calculate_area 函数的实现,我们可以看到解引用操作是先将结构体使用 dup 进行复制,然后通过解构结构体来获得 rec.height 和 rec.width。这段代码存在一定的优化空间,优化后的代码如下:
#[derive(Drop)]
struct Rectangle {
height: u64,
width: u64,
}
#[generate_trait]
impl RectangleImpl of RectangleTrait {
#[inline(always)]
fn calculate_area(self: @Rectangle) -> u64 {
*self.height * *self.width
}
}
fn main() -> u64 {
let rec = Rectangle { height: 3, width: 10 };
let area = rec.calculate_area();
area
}
此处我们为 Rectangle 结构体实现了 calculate_area 并且增加了 #[inline(always)] 标识,该标识声明函数内联。此代码仅会消耗 3170 gas。我们给出以上代码的 Sierra 实现:
dup<helloSierra::Rectangle>([5]) -> ([5], [6]); // 6
struct_deconstruct<helloSierra::Rectangle>([6]) -> ([7], [8]); // 7
drop<u64>([8]) -> (); // 8
rename<u64>([7]) -> ([9]); // 9
struct_deconstruct<helloSierra::Rectangle>([5]) -> ([10], [11]); // 10
drop<u64>([10]) -> (); // 11
rename<u64>([11]) -> ([12]); // 12
store_temp<RangeCheck>([0]) -> ([15]); // 13
store_temp<u64>([9]) -> ([16]); // 14
store_temp<u64>([12]) -> ([17]); // 15
function_call<user@core::integer::U64Mul::mul>([15], [16], [17]) -> ([13], [14]); // 16
...
此处 calculate_area 运行的基本原理与非内联版本是基本一致的,但是由于使用了内联函数,所以类似 PanicResult 处理可以放在一起执行。
非内联版本中,我们可以看到多次 PanicResult 的处理:
function_call<user@helloSierra::calculate_area>([8], [9]) -> ([6], [7]); // 7
enum_match<core::panics::PanicResult::<(core::integer::u64,)>>([7]) { fallthrough([10]) 16([11]) }; // 8
branch_align() -> (); // 9
struct_deconstruct<Tuple<u64>>([10]) -> ([12]); // 10
struct_construct<Tuple<u64>>([12]) -> ([13]); // 11
enum_init<core::panics::PanicResult::<(core::integer::u64,)>, 0>([13]) -> ([14]); // 12
store_temp<RangeCheck>([6]) -> ([15]); // 13
store_temp<core::panics::PanicResult::<(core::integer::u64,)>>([14]) -> ([16]); // 14
return([15], [16]); // 15
branch_align() -> (); // 16
enum_init<core::panics::PanicResult::<(core::integer::u64,)>, 1>([11]) -> ([17]); // 17
store_temp<RangeCheck>([6]) -> ([18]); // 18
store_temp<core::panics::PanicResult::<(core::integer::u64,)>>([17]) -> ([19]); // 19
return([18], [19]); // 20
dup<helloSierra::Rectangle>([1]) -> ([1], [2]); // 21
...
function_call<user@core::integer::U64Mul::mul>([11], [12], [13]) -> ([9], [10]); // 31
enum_match<core::panics::PanicResult::<(core::integer::u64,)>>([10]) { fallthrough([14]) 40([15]) }; // 32
branch_align() -> (); // 33
struct_deconstruct<Tuple<u64>>([14]) -> ([16]); // 34
struct_construct<Tuple<u64>>([16]) -> ([17]); // 35
enum_init<core::panics::PanicResult::<(core::integer::u64,)>, 0>([17]) -> ([18]); // 36
store_temp<RangeCheck>([9]) -> ([19]); // 37
store_temp<core::panics::PanicResult::<(core::integer::u64,)>>([18]) -> ([20]); // 38
return([19], [20]); // 39
branch_align() -> (); // 40
enum_init<core::panics::PanicResult::<(core::integer::u64,)>, 1>([15]) -> ([21]); // 41
store_temp<RangeCheck>([9]) -> ([22]); // 42
store_temp<core::panics::PanicResult::<(core::integer::u64,)>>([21]) -> ([23]); // 43
return([22], [23]); // 44
而在内联版本内,对于 PanicResult 的处理集中在了一起:
...
function_call<user@core::integer::U64Mul::mul>([15], [16], [17]) -> ([13], [14]); // 16
enum_match<core::panics::PanicResult::<(core::integer::u64,)>>([14]) { fallthrough([18]) 25([19]) }; // 17
branch_align() -> (); // 18
struct_deconstruct<Tuple<u64>>([18]) -> ([20]); // 19
struct_construct<Tuple<u64>>([20]) -> ([21]); // 20
enum_init<core::panics::PanicResult::<(core::integer::u64,)>, 0>([21]) -> ([22]); // 21
store_temp<RangeCheck>([13]) -> ([23]); // 22
store_temp<core::panics::PanicResult::<(core::integer::u64,)>>([22]) -> ([24]); // 23
return([23], [24]); // 24
branch_align() -> (); // 25
enum_init<core::panics::PanicResult::<(core::integer::u64,)>, 1>([19]) -> ([25]); // 26
store_temp<RangeCheck>([13]) -> ([26]); // 27
store_temp<core::panics::PanicResult::<(core::integer::u64,)>>([25]) -> ([27]); // 28
return([26], [27]); // 29
节省了大量的处理 PanicResult 带来的 gas 消耗。
Box 指针
在 Cairo 中,Box<T> 指针是一个较少见的数据类型,其功能有以下几点:
- 当有大量数据并希望在确保数据不被拷贝的情况下转移所有权的时候,如
ExecutionInfo - 当希望拥有一个值并只关心它的类型是否实现了特定
trait而不是其具体类型的时候,如nullable_from_box等
此处我们仅讨论 1,因为较为常见。
我们给出以下示例代码:
use starknet::{get_execution_info, get_caller_address};
use starknet::{ContractAddress, contract_address_const};
fn main() -> ContractAddress {
get_caller_address()
}
事实上,我们只关注 get_caller_address 的部分实现,我们给出所需要研究的 Cairo 代码:
#[derive(Copy, Drop)]
struct ExecutionInfo {
block_info: Box<BlockInfo>,
tx_info: Box<TxInfo>,
caller_address: ContractAddress,
contract_address: ContractAddress,
entry_point_selector: felt252,
}
#[derive(Copy, Drop, Serde)]
struct BlockInfo {
block_number: u64,
block_timestamp: u64,
sequencer_address: ContractAddress,
}
fn get_execution_info() -> Box<ExecutionInfo> {
get_execution_info_syscall().unwrap_syscall()
}
fn get_caller_address() -> ContractAddress {
get_execution_info().unbox().caller_address
}
以上代码来自 标准库
进行编译后,我们提取 get_caller_address 对应的部分 Sierra 代码:
...
branch_align() -> (); // 22
struct_deconstruct<Tuple<Box<core::starknet::info::ExecutionInfo>>>([7]) -> ([9]); // 23
unbox<core::starknet::info::ExecutionInfo>([9]) -> ([10]); // 24
struct_deconstruct<core::starknet::info::ExecutionInfo>([10]) -> ([11], [12], [13], [14], [15]); // 25
drop<Box<core::starknet::info::BlockInfo>>([11]) -> (); // 26
drop<Box<core::starknet::info::TxInfo>>([12]) -> (); // 27
drop<ContractAddress>([14]) -> (); // 28
drop<felt252>([15]) -> (); // 29
struct_construct<Tuple<ContractAddress>>([13]) -> ([16]); // 30
...
可以看到处于类型为 Box<ExecutionInfo> 可以使用 unbox 进行拆箱,然后使用常规的 struct_deconstruct 进行解构操作。我本人目前没有见过 Box<T> 的大规模使用,所以此处只能列举出这一个较为简单的例子。如果读者见到过复杂的基于 Box<T> 的项目可以将代码发送给我。
总结
本文介绍 Sierra 引入的原因,并给出一些较为复杂的 Cairo 语法的 Sierra 解释,希望这些内容可以帮助 Cairo 开发者进一步了解和理解 Cairo 语法。
Sierra 作为更接近 CASM 的中间表示层可以有效帮助开发者优化 gas 和理解特殊语法。