概述
本篇文章主要适用于Python爬虫程序员使用Go注释(Golang,在下文中主要使用goalng名词。)编写爬虫,由于目前我个人水平有限,所以此篇文章主要介绍一些简单的爬虫编写,主要包括使用requests、bs4等库的初级Python爬虫的改写,暂时不涉及多线程、异步、反爬、登录等复杂情况。
本教程假设您具有编写Python爬虫的能力和基本的编程能力。本教程使用的案例是爬取豆瓣书籍搜索内容。
注释:众所周知,go是一个常见英语单词,所以在一般的搜索中,我们一般使用golang代替go进行搜索。
基础准备
首先,在个人电脑上安装Golang,您可以自行参考官网教程。该过程较为简单,在此不再赘述。
安装完golang后,我们进行项目的初始化,首先创建一个文件夹,在文件夹中打开终端,输入以下命令:
go mod init github.com/wangshouh/python2go
init后的参数为包名,您可以自行设定,一般使用网站名称+包名的形式,更多关于go mod的信息可以参考官网教程
接下来,我们创建如下两个文件夹douban和doubanTest,前者用来存储主要的爬虫模块,后者用来进行测试程序是否可以正确运行。最终的目录结构如下:
.
├── douban
├── doubanTest
└── go.mod
本教程没有使用单元测试等复杂内容,设计
doubanTest只是为了提供main函数入口
页面获取
抓取页面并打印
豆瓣书籍搜索页面的URL的形式为https://www.douban.com/search?cat=1001&q={搜索内容},需要注意的是搜索内容需要使用url进行编码。需要注意的是豆瓣具有简单的反爬机制,要求请求必须含有User-Agent。
使用Python程序编写如下:
import requests
def get_html(search_text):
url = "https://www.douban.com/search"
params = {
"q": search_text,
"cat": "1001"
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0',
}
response = requests.get(url, headers=headers, params=params)
print(response.text)
显然,golang中没有requests这种库,但标准库net/url可以实现url编码,标准库net/http可以实现各类http请求。
首先,我们在douban文件夹内创建getSearchResult.go文件,输入以下内容。
以下给出golang的代码:
package douban
import (
"fmt"
"io/ioutil"
"log"
"net/http"
"net/url"
)
func GetSearchHtml(term string) {
q := url.QueryEscape(term)
searhUrl := "https://www.douban.com/search?cat=1001&q=" + q
client := &http.Client{}
req, err := http.NewRequest("GET", searhUrl, nil)
if err != nil {
log.Fatalln(err)
}
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0")
resp, err := client.Do(req)
if err != nil {
log.Fatalln(err)
}
returnHTML, err := ioutil.ReadAll(resp.Body)
if err != nil {
log.Fatalln(err)
}
fmt.Printf("%s \n", returnHTML)
resp.Body.Close()
}
第1行,package关键词声明当前所在的包,值得注意的是golang代码都以包作为基本的组织形式而且包内的所有代码位于同一文件夹内,与python常常单文件作为包进行import有所不同。
第3行,import关键词声明包的导入,与python不同,golang可以实现多个包的导入,其中net/http和net/url作用在前文有所提及,此处不再说明。fmt主要用于print,log主要用于日志输出,io/ioutil用于io操作,在写代码时,如果您的IDE存在类型提示功能,您会发现resp.Body属于io.ReadCloser类型,此处使用ioutil提供的功能将其读取为string,即字符串。这也充分显示了golang作为强类型语言与python较为随意进行类型转换的不同。
如果您不想选择GoLand这类付费的JetBrains家的IDE,您可以选择在VSCode上安装
Go插件,也具有类型提示等功能。
初次使用golang时,你会发现会出现一系列类型错误,这正是强类型语言的魅力,但也是会使我们Python程序员头疼。
从第11行开始就进入了核心部分,GetSearchHtml函数,在go语言中参数需要指明其类型,返回值也需要指明类型,在此处为了方便各位理解,此函数被设计为无返回值类型(void),直接使用fmt在终端输出,在后文中我们会更改此函数使它产生返回值。
注意如果您的函数需要在包外调用,需要将函数进行首字母大写,否则默认函数为私有类型,无法在包外调用,因为下文我们会编写入口文件调用此函数,所以进行了首字母大写处理
第12行代码实现了url编码,:=的含义是短变量声明(Short Variable Declarations),不同于python,在golang中我们需要对变量进行初始化,最为简单的方式就是:=,该符号会根据值的类型自动初始化变量名并进行赋值,更多赋值操作,可以参考该教程,或参考《Go程序设计语言》这本书的28页至32页。url.QueryEscape函数实现了url的编码,具体可以参考文档
第13行代码对searhUrl使用前缀和编码后的数据进行拼接生成,在python中这一步直接委托给了requests包,使用params在请求前生成,而在golang中我们需要自行生成。
第14行代码声明client属于http.Client,此处使用了指针,使用&获得http.Client的内存地址,此处使用指针的原因可以简单的理解为第25行使用的Do函数要求client属于指针类型。当然,更深层的原因是http.Client是一个结构体,使用指针调用可以有效的节省内存,在后文中,我们会再次使用指针。
在python转go的过程中最为棘手的就是指针问题,我目前也没有完全能用好指针,如果在学习过程中无法理解,可以先凭借IDE的类型检查用指针。比如类型检查此函数需要指针类型,则在代码中将变量声明改为使用指针。
第17行较为简单,声明了一个新的Request,具体各个参数的含义可以参考文档。值得注意的是err,这是golang最为人诟病的一点,由于golang没有内置错误冒泡机制,我们需要手动处理错误跟踪,较为简单的方式就是代码中给出的第19行至21行的处理方式,如果错误不为空,则直接使用log库抛出并打印异常。
Python提供了完整的错误跟踪机制,可以从错误发生的代码一次次向上回溯至最初发生错误的地方,但golang没有提供这一功能,你可以通过函数的返回值实现冒泡,较为复杂,此处不再说明,如感兴趣,可以参考《Go程序设计语言》第127页 5.4. Errors 此节内容。
第23行对请求头进行设置,类似python代码中的headers设置,较为简单。
第25行使用client.Do函数发生请求,上文我们所构造的req只是一个待发送请求,使用clien.Do函数真正进行请求发生,同时将函数返回值赋值给resp和err。函数具体说明参考文档
第27-29行处理错误。
第31行对resp.Body进行读取,如上文所说resp.Body属于io.ReadCloser类型,此处调用ioutil.ReadAll进行io读取,也可简单的认为此流程就是进行了一个类型转换,将io.ReadCloser类型转换为string类型。
第33-35行处理错误。
第37行打印结果,该Printf函数与C语言同源,但与Python有所不同,python为了方便print已不再大量使用%作为格式化符号,而大量使用{}作为格式化符号,具体可参见PEP 3101,但在golang中依旧保持%作为格式化符号(verb),如果您需要获得所有的格式化字符,可以参考文档,也可以参考《Go程序设计语言》第10页。
吐槽一下,由于golang的创始人肯·汤普逊也是utf-8的设计者,在《Go程序设计语言》这本书中对utf-8进行了极为详细的介绍。
第38行对resp.Body进行Close操作,不同与python,在golang中往往需要手动关闭一些数据流,否则会产生一些意料之外的错误。
进行测试
python的测试较为简单,直接运行即可,以下主要考虑goalng如何进行测试。
在golang中,我们需要一个main包作为入口,我们需要在doubanTest文件夹内编写入口程序进行测试。
在doubanTest中创建main.go文件,输入以下内容:
package main
import "github.com/wangshouh/python2go/douban"
func main() {
douban.GetSearchHtml("金融")
}
注意,此处的import需要您自行更改,当然您可以直接在main()函数中键入GetSearchHtml函数使用IDE的补齐功能。
在终端中输入以下命令:
go run main.go
需要注意终端位置是否位于doubanTest文件夹内。
解析页面获取信息
对于爬虫程序而言,访问并获得页面信息只是第一步,最重要的应该是信息提取的步骤,在此教程中,我们主要抓取下文红框中的内容并输出为JSON格式。
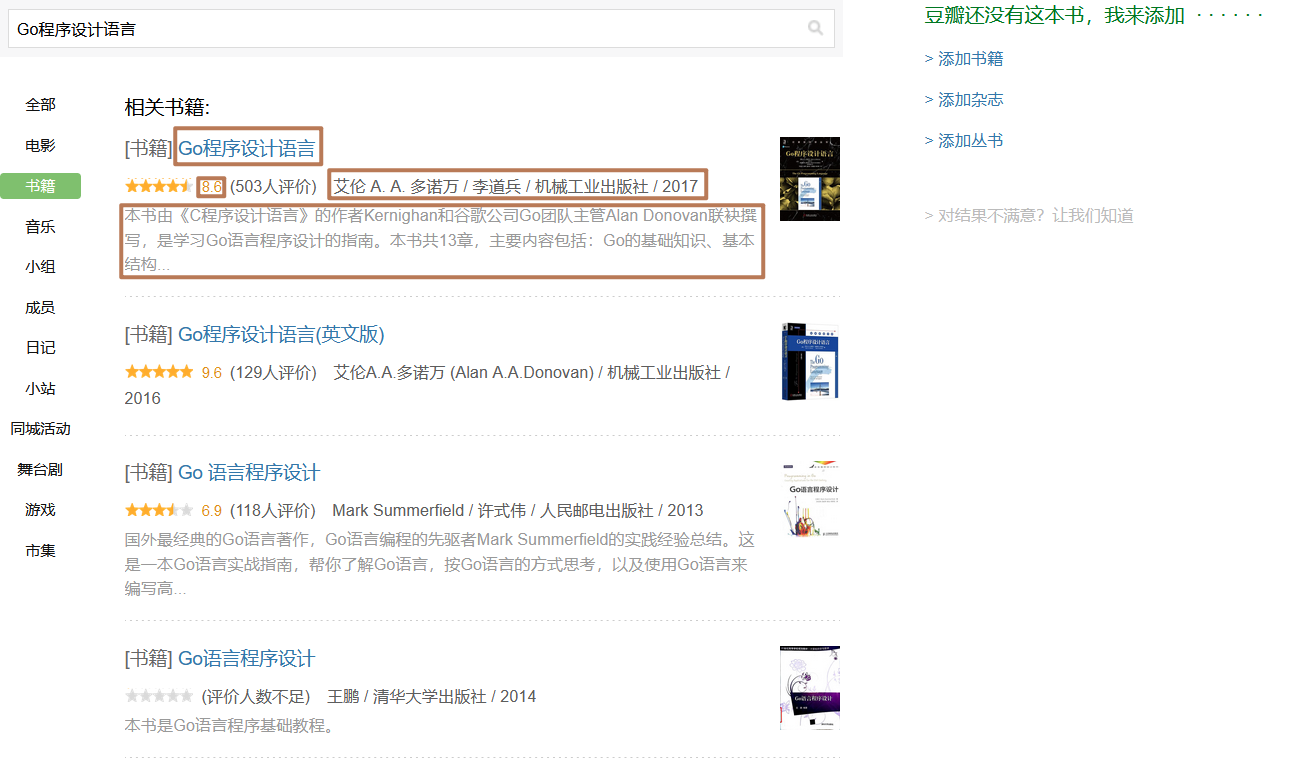
目标结果:

我们需要知道爬虫抓取的元素的特征,通过开发者工具的Inspector我们可以很快确定抓取的目标。
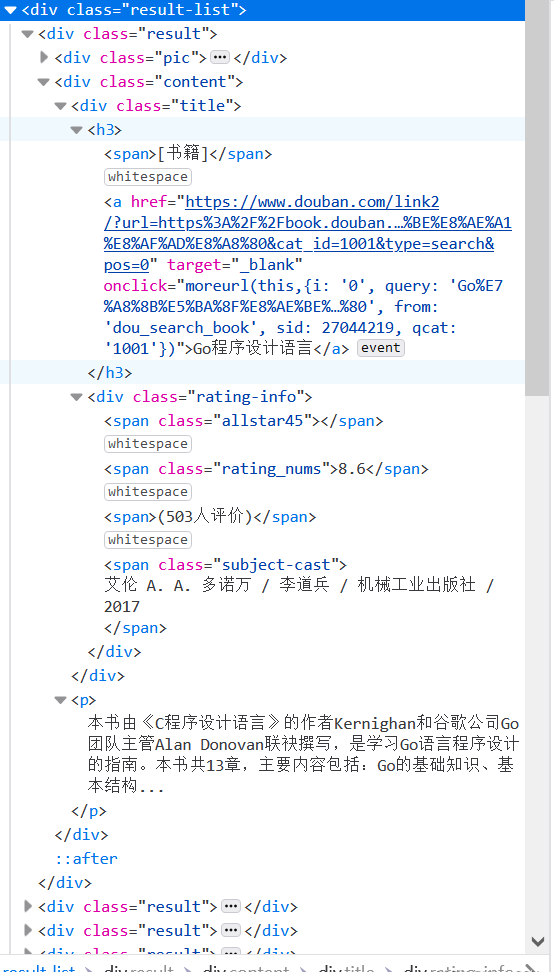
正如上图所见,豆瓣的搜索结果位于div.result-list中,Title位于div.content > div.title > a; RatingNum位于span.rating_nums; subjectCast位于span.subject-cast; Introduction位于div.content > p。
Python代码
这个过程比较简单,在python中我们一般使用bs4库实现这一功能,下面给出具体代码:
import json
import requests
from bs4 import BeautifulSoup
def get_html(search_text):
url = "https://www.douban.com/search"
params = {
"q": search_text,
"cat": "1001"
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0',
}
response = requests.get(url, headers=headers, params=params)
html = BeautifulSoup(response.text, 'lxml')
return html
def get_json(html):
return_list = []
results_list = html.find_all('div', class_='result')
for search_result in results_list:
title = search_result.find("a").get_text()
rating_tag = search_result.find('span', class_='rating_nums')
rating_num = rating_tag.get_text() if rating_tag else ""
subject_cast_tag = search_result.find(
'span', class_='subject-cast')
subject_cast = subject_cast_tag.get_text() if subject_cast_tag else ""
intro_tag = search_result.find('p')
intro = intro_tag.get_text() if intro_tag else ""
return_json = {
"Title": title,
"RatingNum": rating_num,
"subjectCast": subject_cast,
"Introduction": intro
}
return_list.append(return_json)
return return_list
html = get_html("Go程序设计语言")
print(get_json(html))
以上代码可以很好的完成爬取工作,值得注意的一点是由于bs4解析后对无法查询到的结果返回NoneType,为了避免报错,此处使用了判断进行规避,使用的shortcut conditional
expression,规则较为简单,如下:
a if condition else b
Go代码
在此处,我们可以选择golang扩展库中的net/html,但为了减少大家的心智负担,我们在此处引入第三方库goquery,你可以在这个Github仓库找到源代码。该仓库可以以jQuery的形式检索html tag。在golang中安装第三库和python一样简单,使用以下命令即可:
go get github.com/PuerkitoBio/goquery
当然与pip类似,golang也需要换源操作,具体可参考七牛云的goproxy官网,官网中给出了具体的换源方法。
首先,正如上文所提,golang需要对每个变量进行初始化,在此处我们引入复合数据类型struct,并定义一个文件存储struct变量的定义。你可以在这里找到教程,或者查阅《Go程序设计语言》第99页 4.4 Struct节的内容。Go中的struct基本与C语言类似。
在douban文件夹下新建douban.go文件,输入以下内容:
package douban
type DoubanResultList []DoubanResult
type DoubanResult struct {
Title string
RatingNum string
SubjectCast string
Introduction string
}
该代码第3行声明DoubanResultList是由DoubanResult组成的列表,第5行对DoubanResult进行定义。
接下来我们对getSearchResult.go进行修改,具体如下:
package douban
import (
"log"
"net/http"
"net/url"
"github.com/PuerkitoBio/goquery"
)
func GetSearchHtml(term string) (result *DoubanResultList) {
q := url.QueryEscape(term)
searhUrl := "https://www.douban.com/search?cat=1001&q=" + q
client := &http.Client{}
req, err := http.NewRequest("GET", searhUrl, nil)
if err != nil {
log.Fatalln(err)
}
req.Header.Set("Host", "www.douban.com")
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0")
resp, err := client.Do(req)
if err != nil {
log.Fatalln(err)
}
result = GetBookInfo(resp)
return result
}
func GetBookInfo(resp *http.Response) *DoubanResultList {
var resultList DoubanResultList = make([]DoubanResult, 20)
var result DoubanResult
doc, err := goquery.NewDocumentFromReader(resp.Body)
resp.Body.Close()
if err != nil {
log.Fatalln(err)
resp.Body.Close()
}
doc.Find(".result").Each(func(i int, s *goquery.Selection) {
result.Title = s.Find("a").Text()
result.RatingNum = s.Find(".rating_nums").Text()
result.SubjectCast = s.Find(".subject-cast").Text()
result.Introduction = s.Find("p").Text()
resultList[i] = result
})
return &resultList
}
此代码中的GetSearchHtml基本与原函数类似,但在函数定义上加入了返回值,即(result *DoubanResultList),该返回值声明返回DoubanResultList对应变量指针的具体值。正如前文所述,此处使用指针正是为了减少内存使用。
一般来说,涉及到
struct使用指针是一种常见的方式
修改后的GetSearchHtml函数中嵌套了GetBookInfo函数,GetBookInfo函数是实现数据抓取的核心函数。
第38行代码对DoubanResultList进行声明和赋值,此处没有使用短变量声明而是直接使用了完整的变量声明方式,另一方面直接使用了make函数,而且规定了该列表的长度为20。因为确定豆瓣单页返回数据最多为20条所以此处直接规定了列表长度。这种固定长度列表可以提升代码性能。
使用完整变量声明方式可以直接生成没有赋值的变量名,方便复杂代码编写。
第39行代码直接声明result变量,且规定其类型为DoubanResult
第40行代码对resp.Body这一变量进行读取,类似python中的html = BeautifulSoup(response.text, 'lxml')操作。
第43-46行进行错误处理,注意此处也进行了resp.Body的关闭操作。
第48-55行代码为核心代码,Find函数将寻找指定检索tag的所有内容,正如上文所提,首先对class=result所有内容进行提取,这些内容组成一个列表,使用Each函数对列表中的每一项进行迭代,迭代使用了一个匿名函数。具体可以参考文档,但对于我们初级程序员而言只需要知道这个函数必须这么写,第一个参数代表索引值,第二个参数代表列表项即可。函数体内部的代码较为简单在此不进行详细介绍。
第57行代码返回resultList的指针。
注意Each函数为
goquery包内的函数,在golang的原生语法中并不存在,在golang原生中请使用for循环,可以参考这个,当然使用for和range可能更好地达到效果,可以参考这里
同样,我们需要在doubanTest文件夹下修改main函数,为了输出JSON格式,我们需要对struct进行Marshal(编排),此过程需要引入encoding/json标准库。给出代码如下:
package main
import (
"encoding/json"
"fmt"
"log"
"github.com/wangshouh/python2go/douban"
)
func main() {
doubanROutput := douban.GetSearchHtml("Go程序设计语言")
doubanResultJson, err := json.MarshalIndent(doubanROutput, "", " ")
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s", doubanResultJson)
}
关于JSON的Marshal和Unmarshal可以参考《Go程序设计语言》中的第107页 4.5. JSON这一节的内容,此处使用MarshalIndent是为了方便输出。
最后使用go run main.go进行测试,输出结果与我们设想的类似。
总结
与解释型语言python不同,golang中有着大量从C中继承过来的东西,毕竟golang的创造者也是C语言的创造者。如果您对golang真的感兴趣,那么一定要买一本《Go程序设计语言》,最好再学习一部分C语言。接下来会有博客介绍我对C语言的学习情况,随着我技术的进步,这篇文章可能会不断更新,请注意。