概述
最近发现了一个 非常有意思的 PPT 介绍了大量的 gas 优化技巧,本文为此 PPT 的文字版本,但与 PPT 不同的是,本文会会介绍合约内函数 gas 的计算并尽可能介绍每种优化方案的原理。
存储优化
在 Solidity 中,存储的操作码为 SSTORE 和 SLOAD 操作码,此操作码为 EVM 内最为昂贵的操作码,其 gas 计算也较为复杂。
对于用于数据读取的 SLOAD 操作码,其 gas 计算方法如下:
GAS_WARM_ACCESS = Uint(100)
GAS_COLD_SLOAD = Uint(2100)
def sload(evm: Evm) -> None:
"""
...
# GAS
if (evm.message.current_target, key) in evm.accessed_storage_keys:
charge_gas(evm, GAS_WARM_ACCESS)
else:
evm.accessed_storage_keys.add((evm.message.current_target, key))
charge_gas(evm, GAS_COLD_SLOAD)
# OPERATION
value = get_storage(evm.env.state, evm.message.current_target, key)
push(evm.stack, value)
...
上述代码节选自 execution-specs 中的 instructions/storage.py 文件,如无特殊说明,后文所有 Python 代码都来自此仓库。
我们可以看到如果访问的键位于 accessed_storage_keys,实际上,就是位于 access lists 内,其读取的 gas 消耗为 GAS_WARM_ACCESS = 100;否则为 GAS_COLD_SLOAD = 2100。但注意,在缴纳 GAS_COLD_SLOAD 也会将存储槽放入 accessed_storage_keys 内,这意味着在同一笔交易内的第二次读取则只需要缴纳 GAS_WARM_ACCESS = 100 gas。
事实上,我们也可以直接在交易内修改 access lists,此行为在 EIP-2930 内定义,目前较少见其使用,此处我们不再详细讨论。简单来说,access lists 允许用户预支付一笔 gas 费用将存储槽缓存到 accessed_storage_keys 内。
举例说明,假设用户发起了一笔 EIP-2930 交易,其交易的 access lists 包含存储槽 1 的费用,但在这笔交易内,合约读取了 2 次存储槽 1 并读取了 2 次未在交易预设 access lists 中的存储槽 2,读者可以计算一下这 4 笔读取的 gas 消耗。
完整计算过程如下:
- 由于交易的预设
access list,2 次存储槽 1 的读取均按GAS_WARM_ACCESS = 100计算,总体消耗为 200 gas - 存储槽 2 在第一次读取时消耗
GAS_COLD_SLOAD = 2100,而第二次读取则只消耗GAS_WARM_ACCESS = 100,总计花费 2300 gas
总体上,用户花费了 2500 gas 完成了四笔读取。
而用于存储槽写入的 SSTORE 的 gas 计算更加复杂,代码如下:
if (evm.message.current_target, key) not in evm.accessed_storage_keys:
evm.accessed_storage_keys.add((evm.message.current_target, key))
gas_cost += GAS_COLD_SLOAD
if original_value == current_value and current_value != new_value:
if original_value == 0:
gas_cost += GAS_STORAGE_SET
else:
gas_cost += GAS_STORAGE_UPDATE - GAS_COLD_SLOAD
else:
gas_cost += GAS_WARM_ACCESS
上述逻辑可能比较复杂,但是我们可以基于以下分析方法理解:
- 操作的存储槽如果不在
access lists中,则 gas 增加GAS_COLD_SLOAD = 2100,但在这笔交易后续的数据写入过程中则不需要再次缴纳此费用 - 在此交易内,用户第一次修改某个存储槽内容,如果该存储槽在交易前为空,则用户需要缴纳
GAS_STORAGE_SET = 20000;而如果此存储槽在交易前不为空,则用户缴纳GAS_STORAGE_UPDATE(5000) - GAS_COLD_SLOAD(2100) = 2900 - 在此交易内,用户第 n 次(n > 1) 修改存储槽内容,则只需要缴纳
GAS_WARM_ACCESS = 100
我们还是给出一个示例,设当前合约在存储槽 1 内存有 0x123,用户发起交易对存储槽 1 和 存储槽 2 都进行了修改,且存储槽 1 先写入了 0x456 然后又重新写入 0x123,存储槽 2 则写入了 0x789,且用户没有使用 EIP-2930 交易,请读者计算 gas 消耗。
计算过程如下:
- 存储槽 1 修改消耗
- 未处于
access lists,gas 增加GAS_COLD_SLOAD = 2100 0x123 -> 0x456,gas 增加GAS_STORAGE_UPDATE - GAS_COLD_SLOAD = 29000x456 -> 0x123,gas 增加GAS_WARM_ACCESS = 100
- 未处于
- 存储槽 2 修改消耗
- 未处于
access lists,gas 增加GAS_COLD_SLOAD = 2100 0x000 -> 0x123,gas 增加GAS_STORAGE_SET = 20000
- 未处于
研究到此处,读者自然会想到一种 gas 优化方案,即用于不要将一个已有数值的存储槽完全清空,这会导致后续操作 gas 消耗极具增加。
SSTORE也存在退费(Gas refund) 的一些机制,这些机制不会直接影响 gas (使用refund_counter记录退费)所以在此处我们不在讨论。SSTORE的退费相关计算可以参考 此处,而退费的链上操作可以参考 Geth 节点内实现的 refundGas 函数
最新的关于存储的进展是 Transient storage (以下翻译为闪存)基本确定进入主网,在本文编写时该操作码已经在测试网进行测试,此概念由 EIP-1153 引入。Transient storage 提供了一种特殊的存储,在交易结束后,位于 Transient storage 内的所有数据会被自动清除。其中 TSTORE 用于向闪存内写入数据,其 gas 消耗未 100,而 TLOAD 则用于读取数据,其 gas 也为 100。目前对于 TSTORE 讨论较多的使用需求是重入锁等,这些代码由于涉及到跨合约调用,所以需要将数据存储到存储内,但重入锁在交易结束后会自动归零,这导致重入锁消耗的 gas 较高。
接下来,我们可以详细介绍与存储相关的 gas 优化技巧。
存储打包
危险等级: 无,使用此优化策略不会对合约安全性产生影响
易用程度: 简单,原理容易理解,使用非常方便
总体评价: 只要遇到可以使用的地方一定要使用,但在代理合约系统内可能要谨慎使用
我们首先给出一个未经优化的合约:
contract PackingBad {
uint8 public a;
uint256 public b;
uint32 public c;
uint256 public d;
address public e;
function interact() public {
a = 12;
c = 34;
e = address(0x1234);
}
}
该合约优化后如下:
contract PackingGood {
uint256 public b;
uint256 public d;
address public e;
uint32 public c;
uint8 public a;
function interact() public {
a = 12;
c = 34;
e = address(0x1234);
}
}
使用 forge test --gas-report 对函数调用的 gas 消耗进行统计,结果如下:
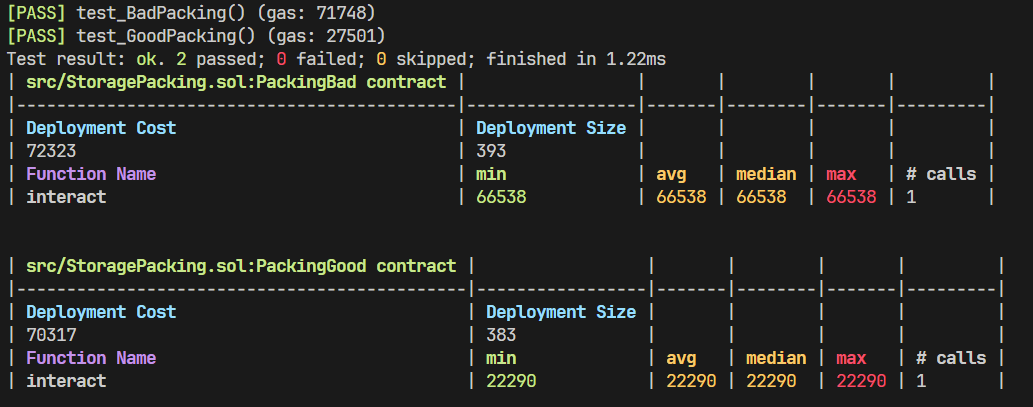
合约调用的 gas 消耗从未优化的 65538 降低至 22290。如此大幅度的优化只是因为我们调整了变量的声明顺序,其实优化的背后是 solidity 编译器的功劳。当 solidity 编译器遇到连续的多个占据位数较少的变量声明时,solidity 编译器会选择打包这些变量。
比如此处的 address public e 为 160 bit 而 c 和 a 各占据 32 bit 和 8 bit,这三个声明时紧邻的变量位数之和为 200 bit,所以 solidity 编译器则会选择直接将其打包起来一起存储,即对 a c 和 e 的赋值只进行了一次存储槽写入。
而 PackingBad 内的变量声明没有满足这一点,即其占据位数较少的变量没有一并声明,所以a c 和 e 的赋值是逐个写入的,三次存储槽写入的 gas 远远高于一次存储槽写入。
常量
危险等级: 无
易用程度: 简单
总体评价: 对于合约内的不变值使用常量可以减少 gas 优化,但该方案实际上适用场景比较少
在 Solidity 中,存在 constant 和 immutable 两种常量声明方案。两者的区别如下:
constant在 solidity 编译过程中就被写入字节码immutable在 solidity 合约部署过程中被写入字节码,所以我们可以在构造器constructor内对其进行赋值
上述两个关键词都是直接将变量打包进入字节码,我们可以使用 CODECOPY 操作码直接访问使用 constant 或 immutable 定义的常量。而 CODECOPY 操作码只需要固定的 3 gas,相比于访问存储槽,直接访问常量显然更加便宜的。
但需要注意,没有免费的午餐。运行时更低成本的 gas 对应着部署时的合约体积增加,我们需要消耗更多的 gas 以部署合约。但一般来说,合约部署时多消耗的 gas 远小于用户多次交互时消耗的 gas,所以我们建议任何开发者都在使用常量时进行此优化。
我们给出未优化和已优化的合约代码:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.13;
contract ConstantWithImmutableBad {
uint256 public neverChange = 0x49206e65766572206368616e6765;
function interact() public view returns (uint256) {
return neverChange;
}
}
contract ConstantWithImmutableGood {
// 0x49206e65766572206368616e6765 is "I never change"
uint256 public constant neverChange = 0x49206e65766572206368616e6765;
function interact() public pure returns (uint256) {
return neverChange;
}
}
上述合约的测试结果如下:
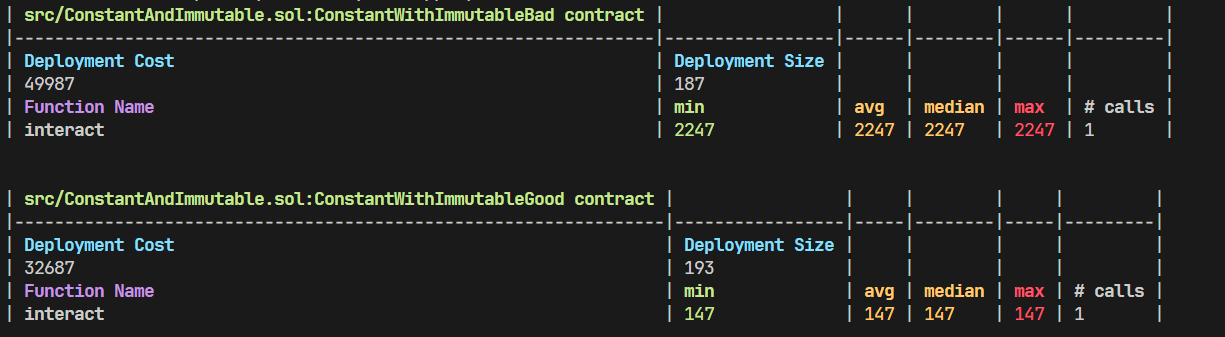
我们可以看到虽然 ConstantWithImmutableGood 使用常量后其 Deployment Size 有部分上升,这会一定程度上增加部署时的 gas 消耗。但此处读者看到了一种相反的情况,即 ConstantWithImmutableBad 合约没有使用常量,但在部署时仍消耗了大量 gas,这是因为 ConstantWithImmutableBad 需要在部署阶段将 neverChange 初始化至存储槽内,存储槽写入的 gas 是巨大的。
缓存
危险等级: 无
易用程度: 中等
总体评价: 缓存进入内存写起来比较丑陋,一定程度上降低了代码可读性,权衡使用
如上文介绍的存储相关的 gas 消耗,第一次读取存储会使用 2100 gas,而后每一次读取都消耗 100 gas。这里就有一个问题在于是否存在一些方案降低后期的读取消耗?部分读者可能已经想到了,直接将存储槽内容使用 MSTORE 操作码放到内存里即可,后续使用 MLOAD 操作码直接在内存内读取。我们使用以下代码强制将存储内的数据缓存到内存内:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.20;
contract CachingBad {
uint256 public a = 10;
function interact(uint256 input) external view returns (uint256) {
uint256 i = 0;
uint256 result = 0;
for(i; i < a; i++) {
result += input;
}
return result;
}
}
contract CachingGood {
uint256 public a = 10;
function interact(uint256 input) external view returns (uint256) {
uint256 i = 0;
uint256 result = 0;
uint256 aCached = a;
for(i; i < aCached; i++) {
result += input;
}
return result;
}
}
我们可以看到 uint256 aCached = a; 实现了存储到内存的缓存。上述合约的调用成本如下:
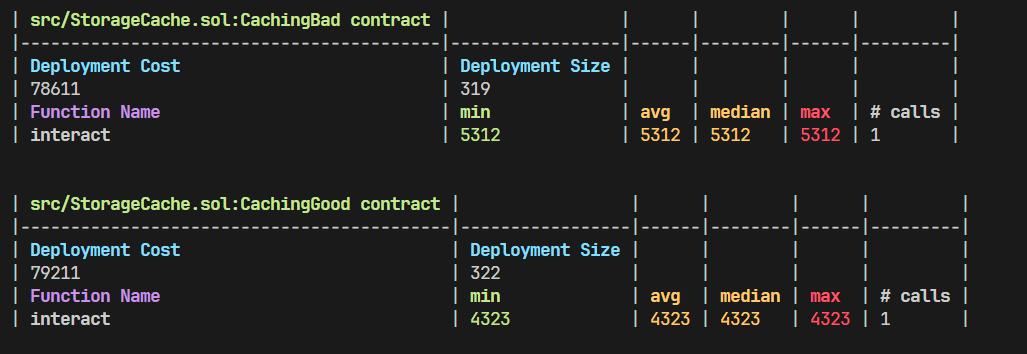
我们可以观察到将存储变量缓存到内存后,在循环调用过程中节省了大量 gas。
有读者可能思考此处是否可以将数据缓存到闪存内?实际上,将数据缓存到闪存内并不会降低以上代码的 gas 消耗,因为使用
TLOAD读取闪存的 gas 仍为 100。如果读者需要跨合约调用过程中的缓存,那么只能使用闪存,因为闪存在跨合约调用返回时还可以进行读取,而内存在跨合约调用时会被清空。
Calldata 与 Memory
Calldata 和 Memory 是 EVM 的两个重要区域,其中 calldata 区域用于存储来自用户或者其他合约的请求参数,该区域的内容是不可变的,我们可以通过 CALLDATALOAD 操作码在此区域内读取数据至栈内,也可以通过使用 CALLDATACOPY 操作码将一定长度的数据读取到内存内部。其中,CALLDATALOAD 操作码消耗固定的 3 gas,而 CALLDATACOPY 操作码则根据复制的 calldata 长度与写入到内存的位置(offset)决定 gas 消耗。其计算方法如下:
words = ceil32(Uint(size)) // 32
copy_gas_cost = GAS_COPY * words
extend_memory = calculate_gas_extend_memory(
evm.memory, [(memory_start_index, size)]
)
charge_gas(evm, GAS_VERY_LOW + copy_gas_cost + extend_memory.cost)
我们可以看到 gas 被分为以下三部分:
- 固定的
GAS_VERY_LOW = 3 - 复制
calldata付出的copy_gas_cost成本,其数值为需要复制的words乘以 3 - 写入
memory付出的extend_memory.cost成本,此部分成本可以理解为内存占用成本,其计算方法较为复杂
在此处,我们深入研究一下内存占用成本的计算,其 gas 计算代码如下:
before_size = ceil32(current_size)
after_size = ceil32(Uint(start_position) + Uint(size))
size_to_extend += after_size - before_size
already_paid = calculate_memory_gas_cost(before_size)
total_cost = calculate_memory_gas_cost(after_size)
to_be_paid += total_cost - already_paid
上述代码中 before_size 值为我们写入前内存已被使用的长度,after_size 为我们写入后内存被使用的长度。我们可以看到内存占用成本实际上只对两次的差值收取 gas。此处的 calculate_memory_gas_cost 对应的代码如下:
size_in_words = ceil32(size_in_bytes) // 32
linear_cost = size_in_words * GAS_MEMORY
quadratic_cost = size_in_words**2 // 512
total_gas_cost = linear_cost + quadratic_cost
上述代码展示了内存占用的 gas 计算公式: $$ Gas_{memory} = memory\ size \times 3 + \lfloor\frac{{memory\ size}^2}{512}\rfloor $$
对于内存的读取,我们使用 MLOAD 操作码,该操作码接受 offset 参数,从指定位置向后读取 256bit 数据。而对于内存写入,我们使用 MSTORE 操作码,该操作码接受 offset 参数,该参数决定从内存那个位置开始写入,同时接受 value 参数,确定内存写入内容。这两个操作码都使用上文介绍的内存占用实际成本计算 gas 费用。在 gas 计算时,我们可以认为 MLOAD 操作码是 MSTORE 操作码的变体,其 value 为 256 bit 长度的全零数据。
Calldata 使用
基于上述内容,我们可以发现直接把 calldata 的数据全部写入到 memory 中是一种浪费行为,一种更好的方案是保持参数位于 calldata 中,当我们需要的时候再进行读取。
我们首先给出该方案的概述:
危险等级: 无
易用程度: 简单
总体评价: 使用 calldata 关键词保持函数调用参数保持在 calldata 内,避免复制问题
接下来,我们给出一段优化前后的代码:
contract CalldataBad {
string public word;
function interact(string memory input) external {
word = input;
}
}
contract CalldataGood {
string public word;
function interact(string calldata input) external {
word = input;
}
}
上述代码中 CalldataBad 使用 string memory input 作为参数的类型标注,使用此类型标注后就意味着 input 会被从 calldata 内被复制到内存中,而 CalldataGood 使用了 string calldata input 作为类型标注,使用此类型标注不会进行 calldata 的复制转移。
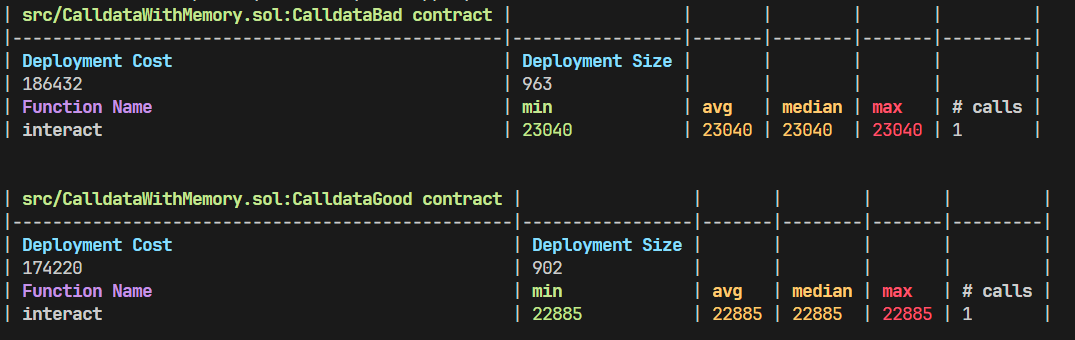
我们可以看到 CalldataGood 相比于 CalldataBad 节省了 155 gas
避免 Memory 扩展
在上文内,我们介绍了使用内存的 Gas 消耗情况,我们可以观察到当使用的内存越多时,消耗的 gas 越多,所以我们应该避免使用大量内存。在 Solidity 内,Solidity 会实现垃圾回收以避免更多内存的使用,但在某些情况下,Solidity 会出现了垃圾回收失效的情况导致大量内存消耗。
在知名 Gas 优化专家 optimizoor 的一篇推文内,给出了以下代码:
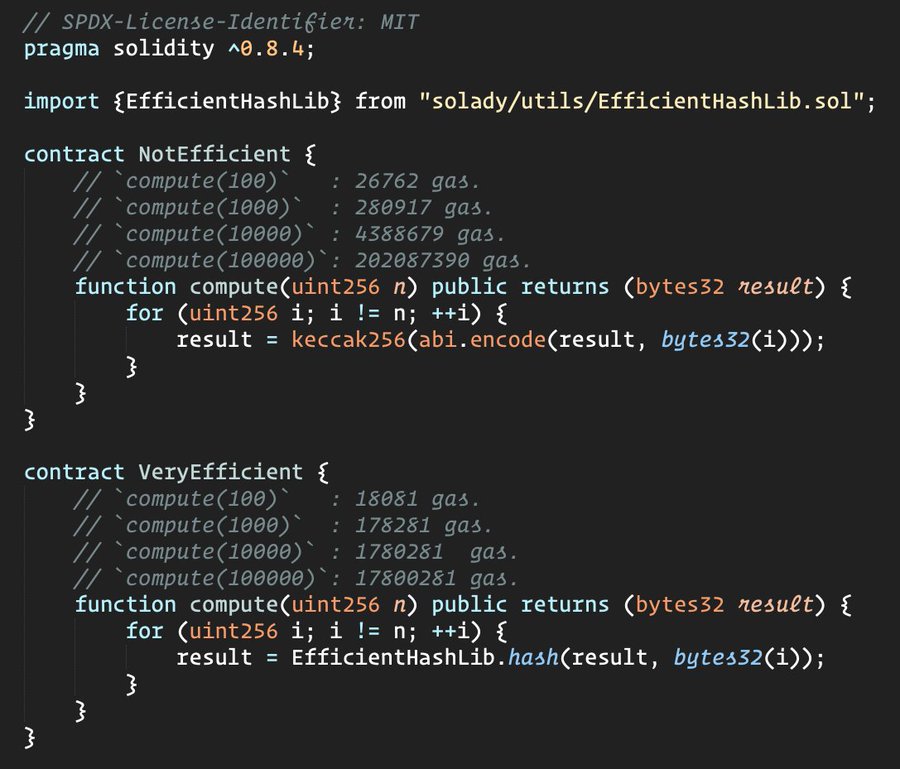
在上文代码内,我们发现使用了
for (uint256 i = 0; i != n; ++i)的语句,而不是常见的for (uint256 i = 0; i < n; ++i)语句,这是因为前者更加节省 gas。关于其节省 gas 的具体原理,我们会在后文加以介绍
我们可以看到伴随着哈希次数的增加 NotEfficient 内的 compute 函数消耗的 gas 指数级增加,这是因为 abi.encode 方法会导致 solidity 为编码后的数据重新分配内存,但该分配出的内存并不会被 solidity 的垃圾回收机制监控到,这导致每次调用 abi.encode 都会分配一个新的内存,这导致内存的膨胀。
而优化版本内使用的 EfficientHashLib 内部的 hash 函数的相关实现代码如下:
/// @dev Returns `keccak256(abi.encode(value0, value1))`.
function hash(bytes32 value0, bytes32 value1) internal pure returns (bytes32 result) {
/// @solidity memory-safe-assembly
assembly {
mstore(0x00, value0)
mstore(0x20, value1)
result := keccak256(0x00, 0x40)
}
}
我们可以看到此代码将输入置于 0x00 和 0x20 空间,然后直接进行了 keccak256 的哈希操作。可能有读者好奇这个操作结束后,没有对空闲内存指针进行处理,该内联汇编是内存的安全的吗?结论是此内联汇编是内存安全的,这是因为上述代码仅使用 0x00-0x40 部分的内存,查看 Layout in Memory 文档,我们可以看到如下结果:
0x00-0x3f(64 bytes): scratch space for hashing methods0x40-0x5f(32 bytes): currently allocated memory size (aka. free memory pointer)0x60-0x7f(32 bytes): zero slot
可以看到 0x00 - 0x3f 就是用于哈希函数的空间,占用此处内存并不会导致任何意外情况的发生。
操作符优化
在本节内介绍的所有方案都会影响一定的代码可读性,而且其原理也会比较底层,但是这些特殊的优化技巧并不会带来极大的 gas 优化效果,读者可以权衡代码可读性与 gas 优化,斟酌使用。
自增优化
危险等级: 中等
易用程度: 中等
总体评价: 实际上就是 i++ 和 ++i 使用的问题,对于 C 语言程序员而言,这是一个简单的问题,但对于大部分使用高级语言的工程师而言并不会意识到两者的区别。
i++ 和 ++i 是存在区别的。两者轻微的区别会导致 Gas 消耗有所不同。
为了更好的讨论 i++ 和 ++i 的 gas 区别及其原理,我们编写如下示例合约:
// SPDX-License-Identifier: UNLICENSED
pragma solidity ^0.8.13;
contract PlusplusBad {
function interact(uint256 input) external pure returns (uint256) {
uint256 i = 0;
uint256 result = 0;
for(i; i < 10; i++) {
result += input;
}
return result;
}
}
contract PlusplusGood {
function interact(uint256 input) external pure returns (uint256) {
uint256 i = 0;
uint256 result = 0;
for(i; i < 10; ++i) {
result += input;
}
return result;
}
}
对上述合约进行 gas 测试,我们可以得到如下结果:
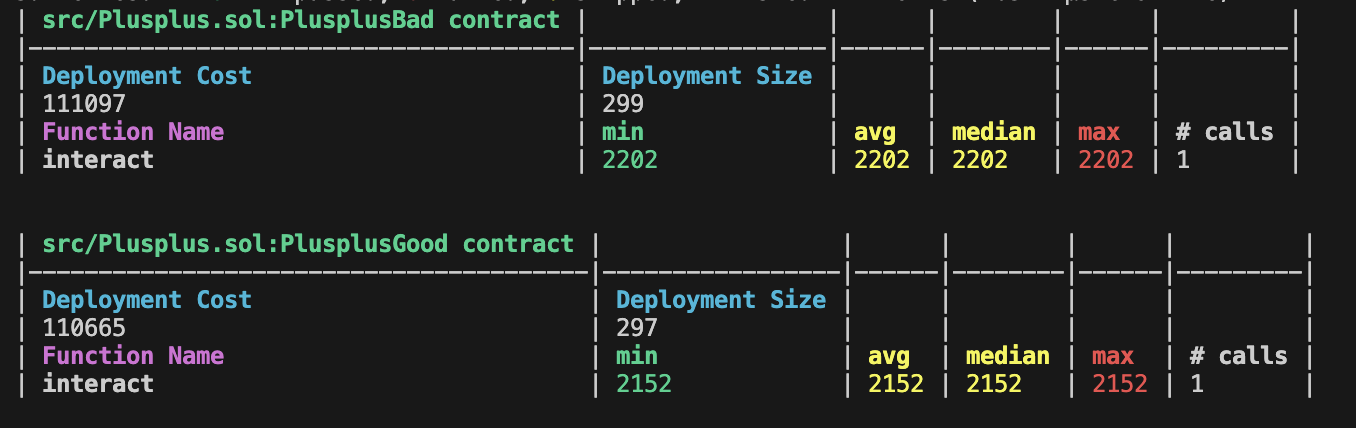
为了解释上述 gas 区别产生的原因,我们需要更加细致的研究。在研究 gas 时,最深入的方法就是对 EVM 字节码的执行进行分析。在 Foundry 组件内,我们可以使用 forge test --debug $FUNC 在 Debug 环境内执行指定测试函数。Foundry Debug 工具将完整报告字节码执行过程中的栈、内存、字节码和 Gas 情况。一个典型的 Debug 终端如下:
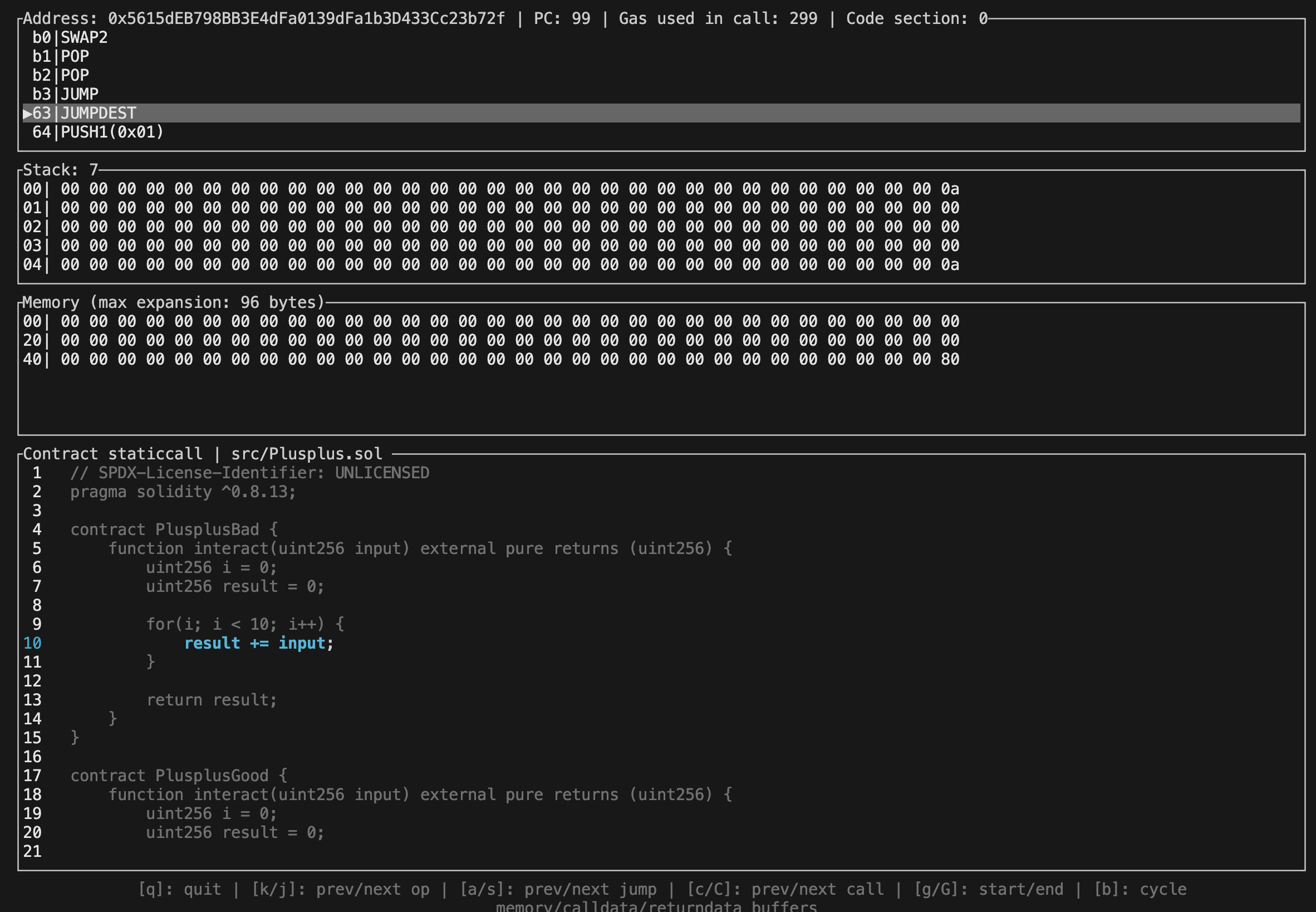
为了得到以上终端页面,我们首先需要编写一个基座测试合约,将以下代码放在 test/Plusplus.t.sol 文件内:
// SPDX-License-Identifier: UNLICENSED
pragma solidity ^0.8.13;
import {Test, console} from "forge-std/Test.sol";
import {PlusplusBad, PlusplusGood} from "../src/Plusplus.sol";
contract PlusplusTest is Test {
PlusplusBad public plusplusBad;
PlusplusGood public plusplusGood;
function setUp() public {
plusplusBad = new PlusplusBad();
plusplusGood = new PlusplusGood();
}
function test_PlusplusBad() view public {
plusplusBad.interact(10);
}
function test_PlusplusGood() view public {
plusplusGood.interact(10);
}
}
然后直接在终端内执行 forge test --debug test_PlusplusBad 命令,我们就可以看到上述界面。对于如何具体使用 Foundry 的 Debug 功能,我建议读者自行阅读 文档 。建议读者首先按下 C 键快速跳转到 PlusplusBad 合约内部,然后使用滚轮向下划滚到此处:
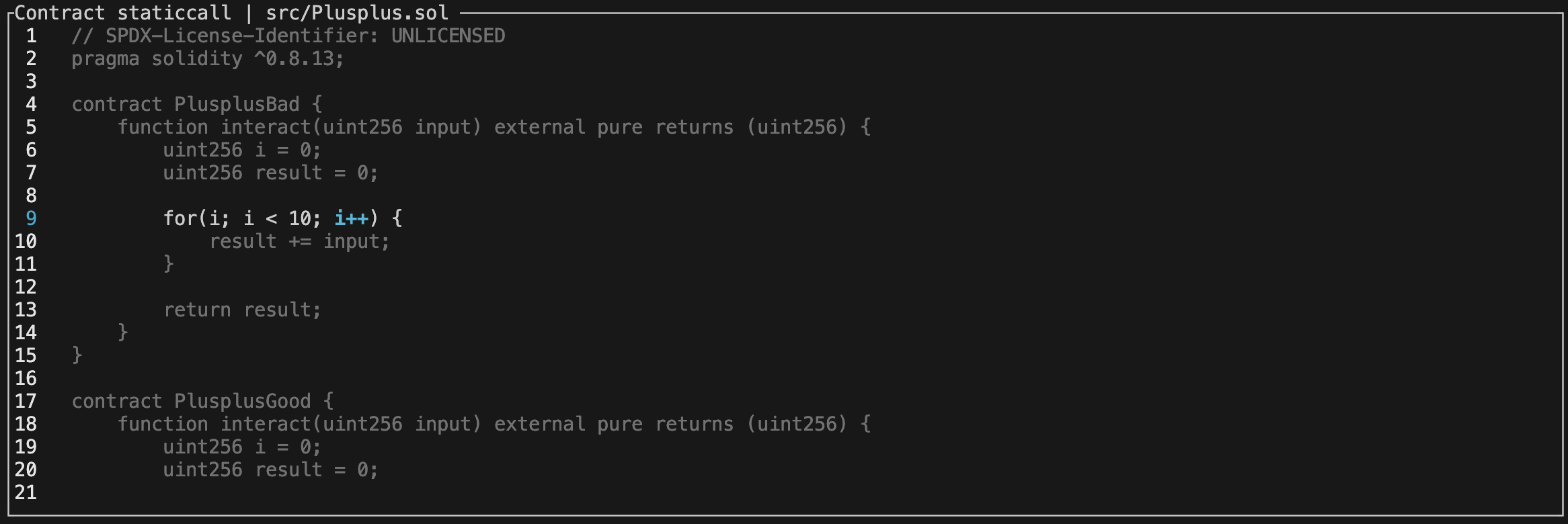
当源代码页面显示 i++ 被高亮时,说明字节码运行到了我们所期待的地方,我们可以看到此时 Debug 告诉我们在进入 i++ 操作前,总共消耗了 299 gas。实际上,PlusplusGood 运行到此处也消耗了 299 gas,读者可以自行使用 forge test --debug test_PlusplusGood 验证。
为了方便分析,我们直接将 i++ 对应部分的字节码拿到本文中,读者可以继续在 Debug 环境内分析:
PUSH1(0x01)
SWAP1
SWAP3
ADD
SWAP2
SWAP1
POP
上述字节码全部执行完成后,Gas 总消耗数值为 320,而栈结构如下:
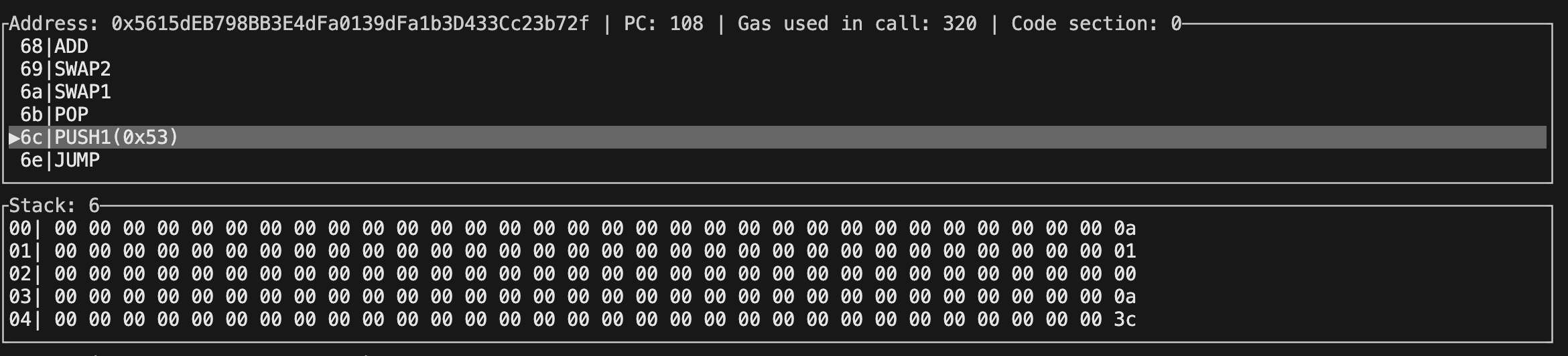
我们可以看到在 i++ 对应的字节码下,solidity 首先选择将 1 使用 PUSH1 指令推送到栈内,然后进行其他操作。
读者可以打开一个新的终端页面,执行 forge test --debug test_PlusplusGood 命令,运行到 ++i 高亮到时候,此时,我们发现 ++i 对应的字节码如下:
SWAP1
POP
DUP2
PUSH1(0x01)
ADD
SWAP2
POP
上述字节码执行完成后,我们可以得到以下 Debug 界面,如下:
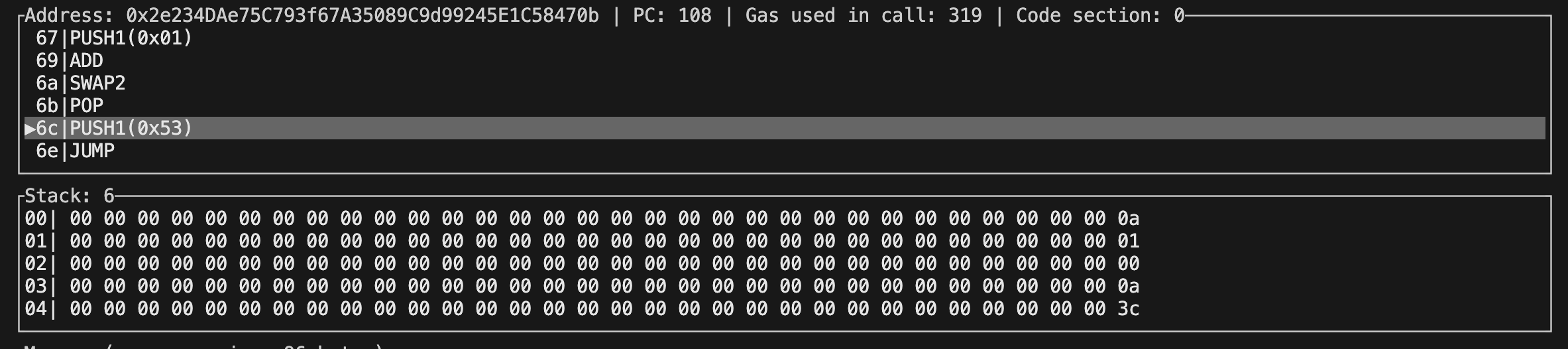
我们可以看到相比于 PlusplusBad ,PlusplusGood 在总 Gas 消耗上减少了 1 gas。原因在于 ++i 将 PUSH(0x01) 后置,这使得对 POP 使用增加,POP 相比于 SWAP 和 DUP 这些消耗 3 gas 的字节码而言,POP 只会消耗 2 gas。
但是,笔者不建议任何开发者在不了解 i++ 和 ++i 的语义的情况下使用。给出以下代码:
uint256 i = 0;
uint256 a = i++;
uint256 b = ++i;
请分析 a 和 b 的数值。我们可以直接使用 Foundry 组件下的 solidity REPL 工具 chisel 进行研究,如下:
Welcome to Chisel! Type `!help` to show available commands.
➜ uint256 i = 0;
➜ uint256 a = i++;
➜ uint256 b = ++i;
➜ a
Type: uint256
├ Hex: 0x0
├ Hex (full word): 0x0
└ Decimal: 0
➜ b
Type: uint256
├ Hex: 0x2
├ Hex (full word): 0x2
└ Decimal: 2
➜ !q
我们可以看到 a 的数值为 0 而 b 的数值为 1。上述命令行最后的 !q 是退出 chisel 命令的操作。出现上述结果的原因是 i++ 只会对 i 进行自增但不会对外给出赋值,而 ++i 除了自增外还会对外给出赋值。
一个有趣的知识,在 solidity v0.8.22 更新中,
PlusplusBad内的i++和PlusplusGood内的++i实际上都不会进行溢出检查,即都处于unchecked的状态,具体的更新日志可以参考 此公告。关于unchecked的具体分析,我们将在下一节介绍。
unchecked
危险等级: 中等。使用此技巧后,需要开发者自行保证业务代码不会溢出
易用程度: 简单,原理容易理解
总体评价: 在确保业务代码不会溢出的情况下可以使用,建议开发者使用前对业务进行深入思考,避免使用 unchecked 后出现溢出情况。
对于 unchecked 关键词,其减少 gas 的原理很简单,即使用 unchecked 包裹的代码不会进行溢出检查以减少 gas 消耗。本文首先介绍在 solidity 中的溢出检查代码:
DUP1
DUP3
ADD
DUP1
DUP3
GT
ISZERO
PUSH1(0xa0)
JUMPI
在上述字节码内,我们假设对 a + b 进行计算,DUP1 DUP3 实现了对 a 和 b 的复制,运行后,栈的结构如下:
b
a
a
b
然后使用 ADD 操作码进行加法计算,运行完成后栈结构如下:
a + b
a
b
之后的 DUP1 DUP3 GT 则是用于溢出检查,运行完成后栈结构如下:
a > a + b
a
b
此处我们需要补充一下加法的溢出检查方法。对加法的溢出检查,只需要检查 a + b 的运算结果是否小于任意一个操作数,比如判断 a + b 是否小于 a 。如果 a + b < a 则证明加法结果结果出现溢出。
最后的 ISZERO PUSH1(0xa0) JUMPI 则用于溢出跳转,假如发生溢出则进行跳转来进行 revert 报错处理。
solidity 对溢出的检测方法是与 OpenZeppelin 的方案是一致的,如果读者对四则运算的溢出测试感兴趣,可以直接参考 Math.sol 合约。
而在代码中使用 unchecked 关键词可以自动关闭上述描述的溢出测试以实现减少 gas 消耗的目的。以加法为例,假如使用 unchecked 关闭溢出检测,会比未关闭溢出检测的方案节省 100 gas。
比较优化
危险等级: 低。
易用程度: 简单,原理容易理解,但是适用场景较少
给出以下两段代码:
contract ComparisonBad {
function interact(uint256 input) external returns (uint256) {
uint256 a = 0;
uint256 i = 0;
for(i; i < input; i++) {
a += input;
}
return a;
}
}
contract ComparisonGood {
function interact(uint256 input) external returns (uint256) {
uint256 a = 0;
uint256 i = 0;
for(i; i != input; i++) {
a += input;
}
return a;
}
}
上述两段代码的功能是一致的,但是 ComparisonGood 相比于 ComparisonBad 会节省一部分(39 gas)。这是因为使用 > 或者 < 等比较符号时,编译产生的字节码会对栈内的元素进行 swap 操作来实现大于或者小于的比较,而 == 或者 != 比较符号则不会对栈进行 swap 操作,所以 == 或者 != 会比 < 或者 > 节省部分 gas。
总结
在本节内,我们介绍了几种常见的且较为简单的 gas 优化技巧。第一部分主要介绍了存储方面的优化,在介绍优化的技巧前,本文介绍了存储方面的 EVM gas 的计算,并介绍了存储打包、常量等优化存储的技术方案。在本文的第二部分,我们介绍了 EVM 的内存 gas 收费标准,内存的占用会伴随着写入偏移量的增加而增加,也介绍了 EVM 的 calldata 存储区域。最后我们介绍了一部分操作符的优化技巧。