概述
Huff 是 EVM 专用语言,与 Solidity 不同,Huff 是面向底层的语言,可以类比与汇编语言。这意味着开发者可以直接操作栈、内存和存储等内容,但另一方面,这些底层操作往往没有安全保证,这需要开发者更加仔细的审计和测试代码。本文章由于涉及大量 EVM 底层操作,希望读者阅读过以下文章:
这些文章都是关于代理合约话题的,这是因为代理合约往往需要使用 yul 汇编语言实现核心功能,所以大量涉及 EVM 底层内容。
当然,为了保证所编写的底层合约的安全性,也希望读者阅读过 Foundry 高级测试: Fuzz、Invariant与形式化证明 ,该篇博客主要介绍了一些高级测试技巧。
由于 Huff 使用了大量底层操作码,请读者阅读过程中一直开启 evm.codes ,本文不再给出每个操作码对应的链接。
本文主要准备使用 huff 实现一个高效率的数学模块,由于计算机底层数学操作大量使用位移等底层计算原语,使用 Solidity 会大量增加合约的 gas 消耗,本文的目标是构造一个在 gas 方面达到极致的合约。但需要注意极致的优化意味着可读性的大幅度降低。
笔者本人并不是算法领域的工程师,但笔者最近阅读了 《算法心得:高效算法的奥秘》 一书,此书包含大量依赖二进制数据操作的黑魔法,本文大部分实现都来自此书。
本文所有代码位于 Github 仓库 中,读者可以参考。
为什么不选择使用 huff 实现 ERC-20 等常见合约?原因在于 huff 本身的表达能力较差,官方实现的 ERC20 有近 500 行。
EVM 基础
对于 EVM 整体架构,我们可以通过下图表示:
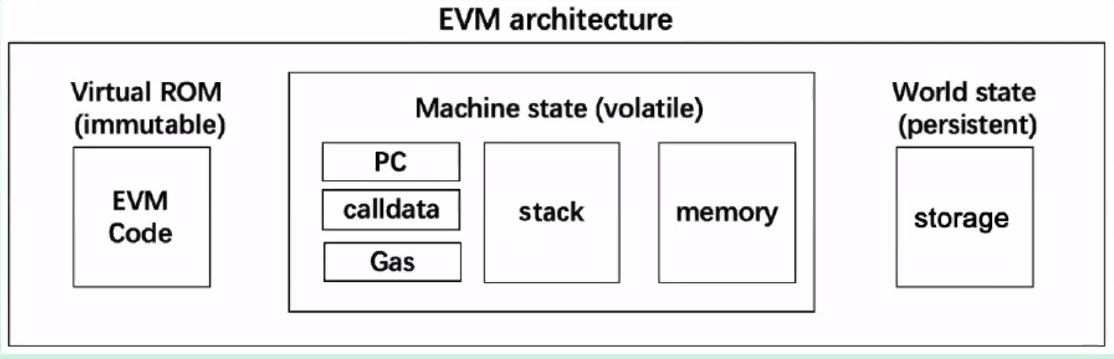
我们可以看到可变的数据只有:
- calldata 请求合约调用的数据
- Gas 交易的 gas 费用
- PC 程序计数器,记录当前运行的代码的位置
- stack 栈,用于存放计算所需要的参数和执行计算操作
- memory 内存
而实际上,我们主要操作 stack 栈和 memory 内存,而 calldata 区域在合约运行时是只读的。
当然,我们也可以修改 storage 存储。
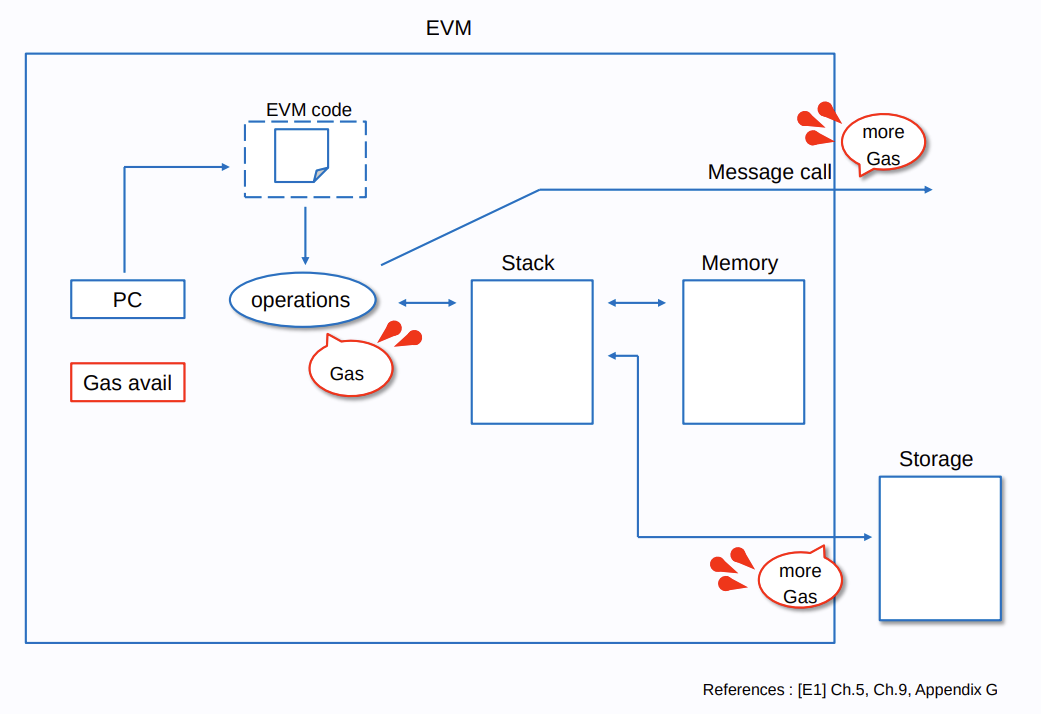
一笔交易触发的 EVM 运行流程如下:
下图展示了 stack 栈的作用:
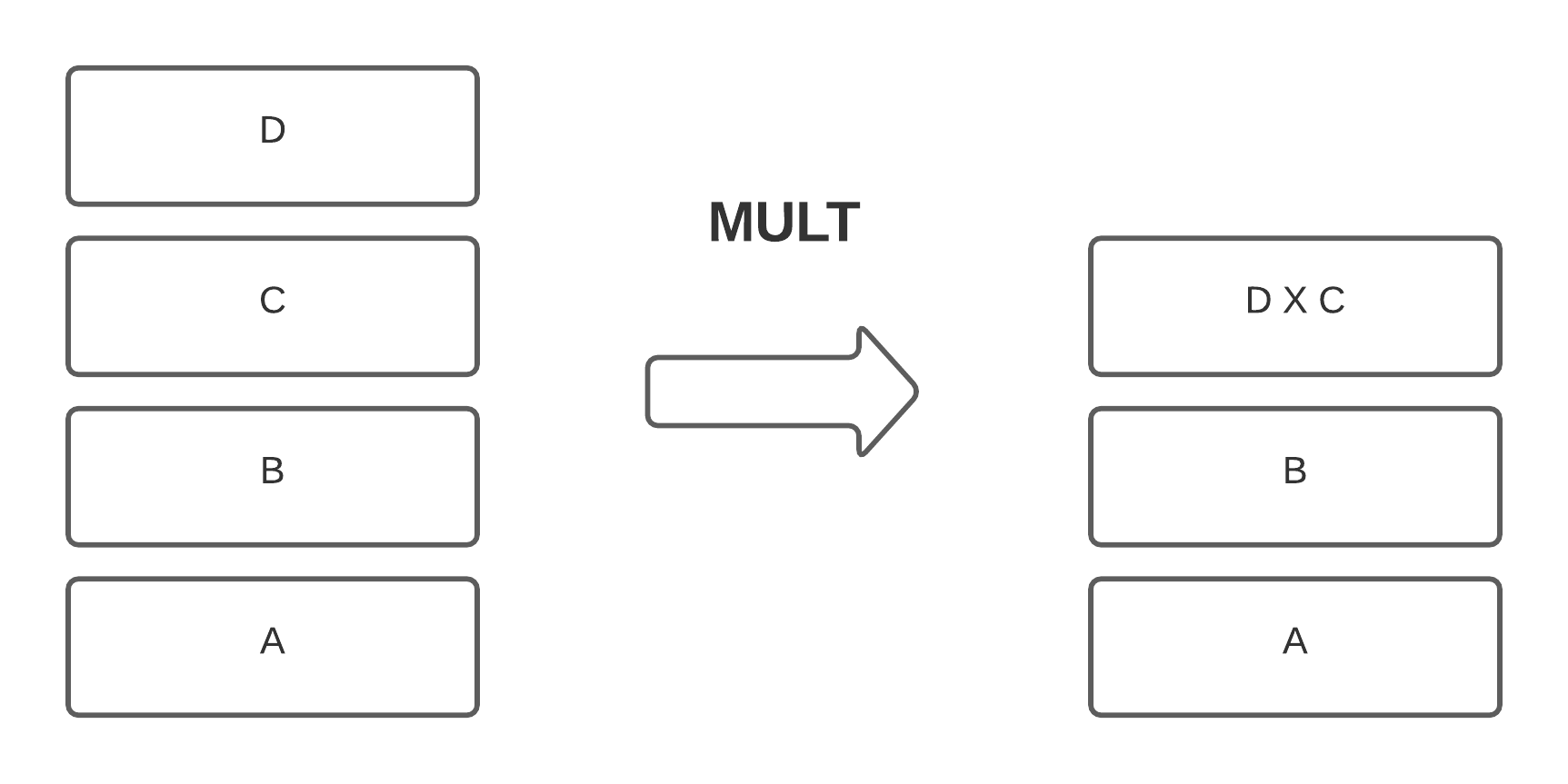
栈的最大深度为 1024 个元素,每个元素位长为 256 ,我们可以使用 PUSH 向栈内推入元素,也可以使用 POP 弹出元素,同时也可以对栈内元素进行操作,如通过 ADD 实现栈内元素的相加。上图即展示了栈内元素相加的情况。
几乎所有的 EVM 操作码都会对栈进行操作,evm.codes 中给出了每个操作码所需要的栈元素,即 Stack Input 一列。
下图展示了 memory 内存的基础情况:
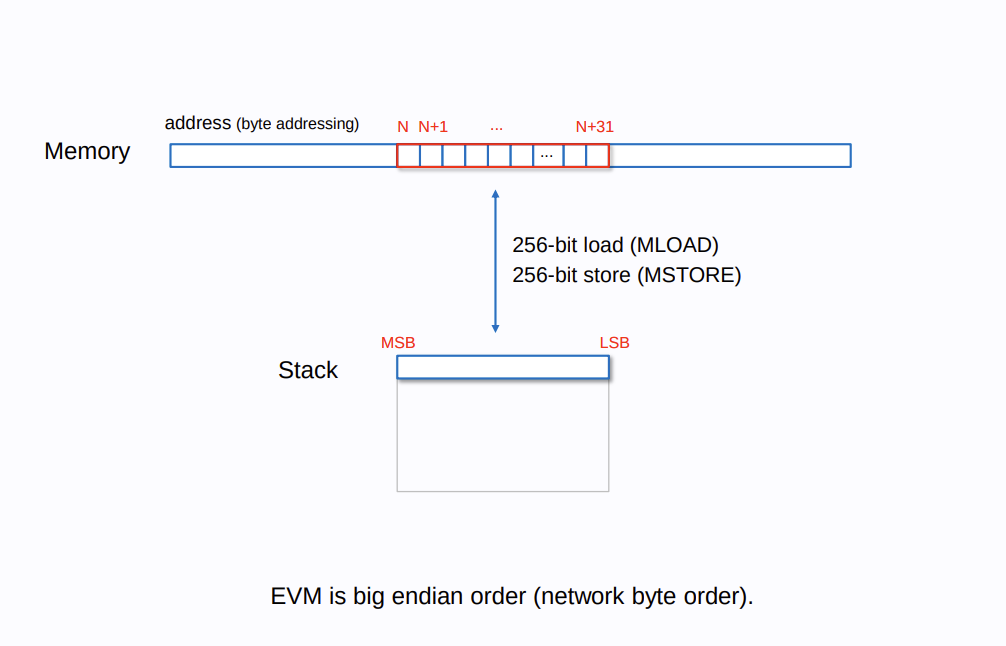
内存是一个可寻址的线性空间,一般情况下,我们使用 MSTORE 操作码向地址内写入数据,使用 MLOAD 操作码读取数据,值得注意的是,这两个操作码仅支持 256 bit 数据的整体写入和读取。上图展示了一种较常见的情况,即将栈内的结果写入内存中。
在 EVM 中,虽然不存在内存溢出情况,但这不意味着我们不需要进行垃圾回收,因为随着写入的偏移增加,gas 消耗也随之增长。
下图展示了 storage 存储的一般情况:
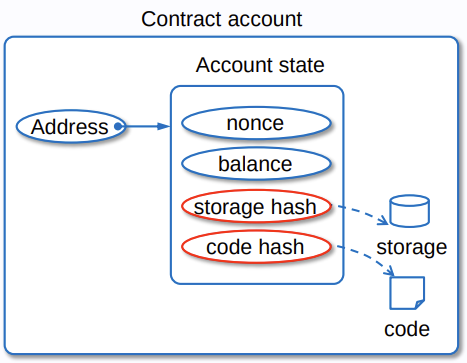
在 EVM 内,存储是一个 KV 数据库(或理解为词典数据类型),每个数据由 256 bit 长度的键与 256 bit 长度的值构成。一般使用 SSTORE 进行存储,使用 SLOAD 进行读取。值得注意的是,操作存储是一项开销极大的操作。
最后,我们介绍没有在图中展示的 return data ,该内容用于对合约调用者返回信息,一般使用 RETURN 操作码返回操作成功后的数据,使用 REVERT 操作码返回报错信息。接受方可以使用 RETURNDATACOPY 等操作码进行 return data 的数据读取。
上述内容仅是对 EVM 进行了初步介绍,可以保证读者基本可以完成本文内容的阅读,如果读者有时间,请阅读 About the EVM。
更多参考资料可以使用 EVM tag 在我的 阅读数据库 里搜索,也欢迎大家订阅 我的频道 以获取最新的资料。
环境配置
huffc 安装
由于 foundry 并没有原生支持 huff 语言,所以我们需要单独安装 huff 的编译器 huffc ,由于 huffc 也是使用 Rust 编写的程序,所以安装较为简单。命令如下:
curl -L get.huff.sh | bash
source .bashrc
huffup --version nightly
最后,我们运行 huffc --version 可以获得版本输出。
在安装过程中,会显示
/root/.huff/bin/huffup: line 25: yarn: command not found输出,该输出不是要求安装yarn,而是表示该用户环境内没有yarn版本的huffc(早期的huffc是使用javascript编写的,该版本已被废弃)。
项目初始化
运行以下命令使用 huff-project-template 模板建立项目:
forge init --template https://github.com/huff-language/huff-project-template huffLearn
接下来就进入了正式的合约编程环节了,读者可以选择使用自己喜欢的编辑器,如 vscode 或 sublime ,前者需要搭配 vscode-huff 插件,实现了很多有用的功能,而后者需要搭配 hufflime 插件,仅有语法高亮的功能。
常数表
为方便读者阅读,此处我们给出一些转换数据:
- 1 byte = 8 bits
- 1 byte = 2 hex
- 1 hex = 4 bits
其中,hex 表示一个 16 进制字符。
接下来,读者可以进行一些简单的训练:
- 已知 EVM 内存位长为 256 bits,请计算对应的
byte - 已知某函数选择器为
0x8cc5ce99,请计算对应的bits
答案为:
32 bytes(此处使用的bytes仅表示其为byte的复数形式)- 32 bits
基础运算
在本节中,我们主要介绍以下内容:
- 可溢出加法
- 不可溢出加法
- 不可溢出乘法
- 前导 0 计数算法
- log2 算法
- 开方算法
正如前文所言,在本文中,我们将大量使用二进制操作黑魔法,以追求极致的 gas 效率。在本文中,我们不会分析算法的安全性问题,原因如下:
- 本文介绍的算法均来自传统计算机领域,属于底层算法,出现安全问题的概率较小
- 严格证明算法的正确性需要使用
z3等求解器形式化证明,为保证文章的专题性,我们不会进行讨论,但可能会在下一篇文章内对其进行分析。
可溢出加法
可溢出加法并没有什么值得讨论的算法问题,本节主要是为了读者可以更快适应 huff 编程。
本节正式进入 huff 编程,我们将展示一些简单的基础的 huff 代码,请读者在 src 文件夹内创建 HuffMath.huff 文件,写入以下内容:
#define function addNumbers(uint256,uint256) nonpayable returns (uint256)
#define macro NON_SAFE_ADD() = takes (0) returns (0) {
0x04 calldataload // [num1]
0x24 calldataload // [num2, num1]
add // [result]
0x00 mstore
0x20 0x00 return
}
#define macro MAIN() = takes (0) returns (0) {
0x00 calldataload 0xE0 shr
dup1 __FUNC_SIG(addNumbers) eq addNumbers jumpi
addNumbers:
NON_SAFE_ADD()
}
上述 huff 代码构造了一个用于加法的函数。在文件开始,我们需要定义该合约所拥有的函数的 ABI 接口,基本与 solidity 的接口写法一致,但此处增加了 nonpayable 标识符表示该函数不操作 ETH 原生资产,且此处无需表明函数的 public 等属性。
然后,我们定义具体的函数 NON_SAFE_ADD ,此处使用了 macro 标识,在 huff 中,macro 可以理解为函数的意思。然后,我们使用 takes 规定该函数从栈内消耗的元素数量。此处,我们设计的 NON_SAFE_ADD 函数并不需要消耗栈内元素,所以此处使用了 takes (0) 作为定义。
returns 表示函数运行结束后,栈内剩余的元素数量,由于此处 NON_SAFE_ADD 运行结束后直接将运行结果返回,所以使用 returns (0) 表示函数运行结束后栈内无剩余元素。
接下来,我们进入函数体的定义。我们可以看到每行末尾都有一个形如 // [num1] 的注释,这些注释只是方便开发者了解当前栈内的元素情况,在编译时没有实际意义。
NON_SAFE_ADD 可以分为三部分:
- 将参数写入栈内,使用
calldataload操作符 - 具体计算环节,使用
add操作符 - 返回环节,使用
mstore和return操作符
关于 calldata 的具体构成,我们在此处不进行详细讨论,读者可以参考 Solidity 文档的 Contract ABI Specification 一节,或者参考 Reversing The EVM: Raw Calldata 、ABI Encoding Deep Dive 等文章。
可能有读者好奇作为 huff 语言开发,为什么要看 solidity 文档的解释?这是因为 solidity 的合约 ABI 规范已经成为了业内标准,包括 vyper 在内的智能合约语言都符合 solidity 规范。
在 calldata 导入后,我们获得了形如 [num2, num1] 的栈结构,我们使用 add 操作栈元素,操作后获得 [num1+num2] 的栈结构。接下来我们使用 0x00 mstore 语句,此语句可以分解为将 0x00 推入栈内,运行 mstore 操作码。mstore 的具体功能是将栈内元素放置到内存中,具体功能请参考 evm codes
在 huff 中,所有写出的数字都会被推入栈内,无需手动调用
PUSH操作码
完成 mstore 操作后,栈内元素均被清空,接下来,我们需要进行数据返回操作,使用 0x20 0x00 向栈内推入 0x20 和 0x00 元素,调用 return 从内存中返回值。其中,0x00 指明 offset ,即返回内容在内存中的起始位置,而 0x20 指明 size,即返回内容的长度。
以上,我们就完成了一个简单的函数编写。
仅有函数是不够的,我们需要定义一个主函数进行代码调用分发,该函数是字节码的开始,主要功能是根据 calldata 的函数选择器部分选择对应的函数运行。为方便读者阅读,我们再次展示此代码:
#define macro MAIN() = takes (0) returns (0) {
0x00 calldataload 0xE0 shr
dup1 __FUNC_SIG(addNumbers) eq addNumbers jumpi
addNumbers:
NON_SAFE_ADD()
}
此处我们将使用 0x00 calldataload 将数据导入到栈内,该过程可被分解为 0x00 推入栈内,然后运行 calldataload 操作码。然后,我们使用 0xE0 shr 对栈内数据进行右移 0xe0 位(即右移224位)操作,此处栈内仅剩余长度为 32 位的选择器字段。然后,我们使用 dup1 复制该元素,此时栈结构 [selector, selector] (此处的 selector 指处理好的待匹配的函数选择器)。然后,我们将代码中提前计算好的函数选择器推入栈内,获得 [0x0f3d0204, selector, selector] (此处使用 0x0f3d0204 即 addNumber 的函数选择器),进行 eq 相等判断。如果相等,我们获得 [1, selector] 栈结构。然后,我们看到了 addNumber jumpi 两个操作码,我们可以视两者为一个整体,等同于 C 语言或者 golang 中的 goto label 结构,但 jumpi 是带条件跳转,如果栈内第一个元素不是 true 则不会跳转。
上述流程听上去较为复杂,原因在于使用了纯汇编,使用高等语言表示如下:
function_selector = calldata >> 224
if (function_selector == sig(addNumbers)) {
goto label
} else {
...
}
上述代码中 sig 表示选择器生成函数,即使用 addNumbers 定义生成对应的 4 bytes 无符号整数。读者可以看到,我们使用了 jumpi 实现了 if 跳转。
此过程使用
switch结构表达更为合适,但此处仅有一个函数选择器,使用if语句也可。
最后,我们定义了:
addNumbers:
NON_SAFE_ADD()
为上文的跳转提供目的地。
如果读者了解过编程语言的历史就知道,goto 语句是早期语言的一大争议点,如今,大部分高级语言都删除了此语句。但在 huff 中,为了实现 if 逻辑,我们不得不使用 jumpi 语句。
读者有可能发现了使用上述方法进行函数选择器匹配的时间复杂度为 O(n) ,对于某些大型项目而言,此时间复杂度是无法容忍的,所以还有一种更加强大的基于二分搜索的方法,如果感兴趣,读者可以阅读 Constant Gas Function Dispatchers in the EVM 文章。
编写完上述函数后,我们需要对其进行测试,请读者建立 test\HuffMath.t.sol 合约,键入以下内容:
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.15;
import "foundry-huff/HuffDeployer.sol";
import "forge-std/Test.sol";
contract mathTest is Test {
HuffMath public huffmath;
function setUp() public {
huffmath = HuffMath(HuffDeployer.deploy("HuffMath"));
}
function test_add() public {
uint256 result = huffmath.addNumbers(1, 2);
assertEq(result, 3);
}
}
interface HuffMath {
function addNumbers(uint256, uint256) external pure returns (uint256);;
}
总体来说,测试 huff 合约比较简单,只是改变了合约部署方法,使用 HuffDeployer.deploy 部署,而不是简单的 new ,以及需要手动编写接口。
需要注意的是,huff 合约的测试是慢于 foundry 对 solidity 合约的测试的,后者有着 foundry 开发者提供的各种优化,而前者并没有这些优化,导致 huff 合约测试速度较慢。
可能有读者好奇,
huff如何兼容foundry的?关键在于HuffDeployer合约,该合约使用foundry的知名高级特性ffi。简单来说,foundry允许用户通过ffi直接调用命令行工具。
不可溢出加法
本节主要讨论安全加法,即不可溢出加法。一旦加法结果溢出,则触发错误,进行 revert 回滚操作。
在具体实现前,我们首先需要知道如何判断加法是否溢出。对于无符号数的加法,我们可以通过简单的判断加法结果是否小于其中任何一个操作数即可。
对于带符号加法,我们很难判断是否溢出,且带符号加法在智能合约领域较为少见,故本文不予讨论。
接下来,我们开始构造该函数。
首先在 HuffMath.huff 的头部定义函数:
#define function safeAdd(uint256,uint256) nonpayable returns (uint256)
首先,我们使用常规步骤导入两个加数,代码如下:
0x04 calldataload // [num1]
0x24 calldataload // [num2, num1]
可能有读者希望在此处使用 add 操作符,但我们发现直接使用 add 后,获得 [result] 结构的栈。(此处的 result 即 num1 + num2,为方便而记为 result)。然后,我们发现无法进行后续步骤,因为我们还需要进行加法结果与加数的比较。
所以,在此处,我们使用 dup2 将 num1 复制一份到栈顶,获得 [num1, num2, num1] 的栈结构。然后运行 add 操作码,获得 [result, num1] 栈结构。可能又有读者准备直接使用 lt 操作符,以判断 result < num1 是否成立,但需要注意一旦运行 lt 操作码,则会直接消耗 result 和 num1 两个栈元素,使得加法运算结果 result 丢失。
为了保证加法结果 result 不丢失,我们仍需要运行 dup1 以复制栈元素,获得 [result, result, num1]。接下来进行大小判断,判断仅能使用栈顶元素为参数进行,所以此处使用 swap2 进行栈内元素交换,获得 [num1, result, result] 栈。然后,我们可以运行 gt 操作码以判断 num1 > result 是否成立。
如果成立,则返回 true 值,否则返回 false 。故运行 gt 后我们获得 [is_overflow, result] 栈结构。(此处的 is_overflow 即是是否溢出的标识符,命名为 is_overflow 仅为方便阅读)。如果 is_overflow 成立,我们需要跳转到错误处理阶段,使用 over_flow jumpi 可以实现此逻辑。其中 over_flow 为跳转后代码块的名称,我们随后定义此代码块。
如果运算结构未溢出, jumpi 不会进行跳转,但会消耗栈元素,最终获得 [result] 栈结构。我们使用以下代码将其存储到内存中并返回:
0x00 mstore
0x20 0x00 return
最后,我们处理错误,代码如下:
over_flow:
0x00 0x00 revert
我们在此处再次讨论一次关于 jumpi 的相关内容。读者可能感觉 huff 在编译过程中为了实现 over_flow jumpi 语句进行了大量工作,事实上,是没有的。over_flow 作为代码块的标签名,huff 在编译过程中会计算出该 over_flow 标签对应的代码块在字节码中的偏移,然后将其直接代换到 over_flow 标签的位置。而 over_flow 代码块的实际部分则会在代码编译过程中插入 JUMPDEST 标识符,表示跳转目的地。
有读者可能读不懂上述表述,读者可参考 此处 ,这是一个最简单的
jumpi示例,但也展示了jumpi背后的工作原理,请读者选择Step into步进执行,并随时观察Stack栈结构
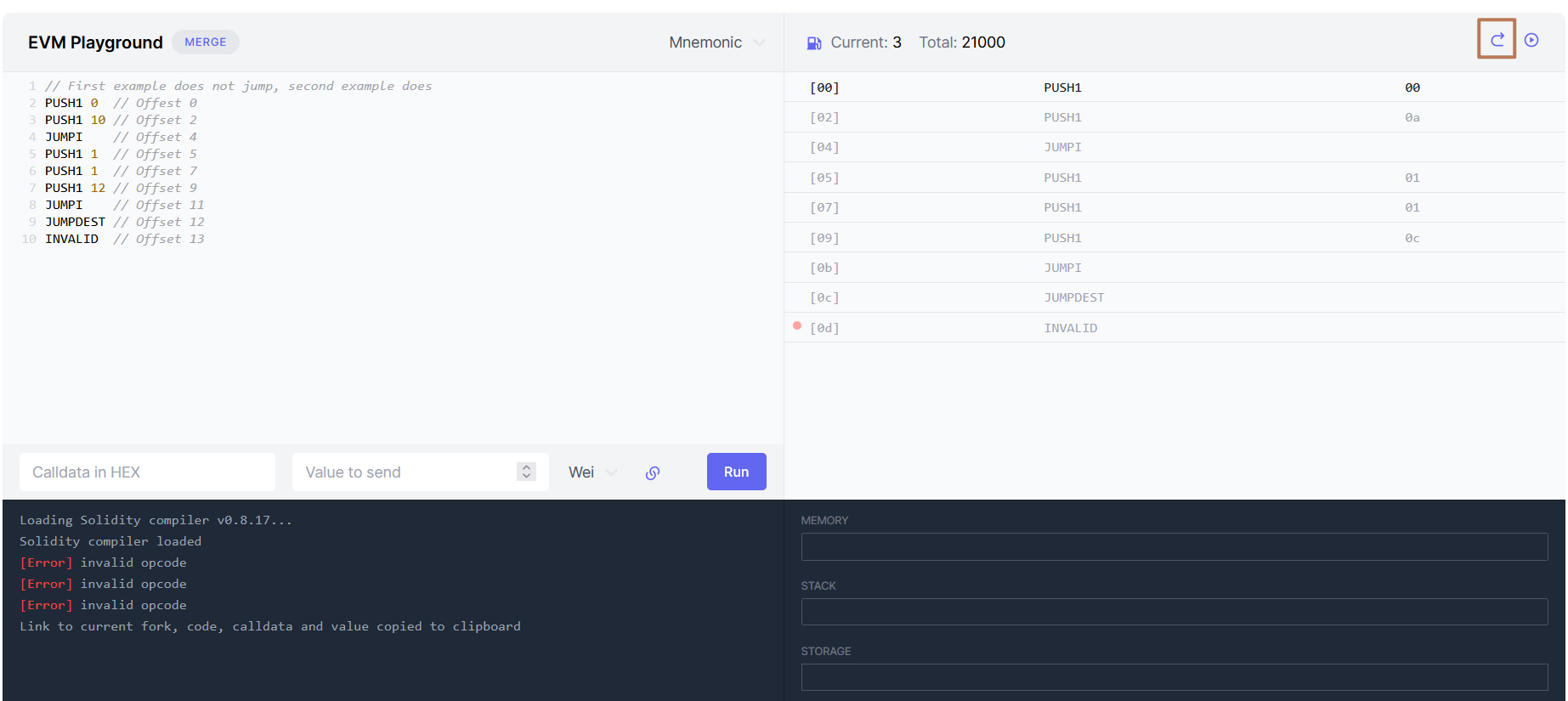
最后,整体代码如下:
#define macro SAFE_ADD() = takes (0) returns (0) {
0x04 calldataload // [num1]
0x24 calldataload // [num2, num1]
dup2 // [num1, num2, num1]
add // [result, num1]
dup1 // [result, result, num1]
swap2 // [num1, result, result]
gt // [is_overflow, result]
over_flow jumpi
0x00 mstore
0x20 0x00 return
over_flow:
0x00 0x00 revert
}
当然,与 solidity 不同,我们可以简单计算出上述代码的 gas 消耗。上述代码中,jumpi 之前的部分每个操作码的 gas 均为 3 。注意,0x04 和 0x24 也会消耗 3 gas ,因为事实上,0x04 是 PUSH1 0x04 的语法糖。简单计算就可以获得 gt 及其之前的代码总计消耗 27 gas 。
剩余部分代码的 gas 分析关键在于获得 over_flow jumpi 的代码消耗。如上所述,over_flow 会在编译期间转换为 over_flow 实际代码块在字节码中的位置,所以此处 over_flow jumpi 可以认为是 PUSH over_flow jumpi 的语法糖。其中 PUSH over_flow 消耗 3 gas 而 jumpi 消耗 10 gas 。
假如溢出,我们需要计算以下代码块的 gas 消耗:
over_flow:
0x00 0x00 revert
overflow: 作为表示跳转终点的标识,也会消耗 1 gas ,剩余部分 0x00 0x00 revert 消耗 6 gas 。
此处使用的
revert是一个动态 gas 消耗函数,读者可使用 evm.codes 中的Estimate your gas cost进行评估。该结果主要与内存消耗挂钩。
如果未溢出,则会运行 0x00 mstore 和 0x20 0x00 return 代码,前者 0x00 mstore 中的 mstore 也是一个更具内存占用动态调整的操作符,此处消耗 6 gas ,而 return 也是一个根据内存消耗给出 gas 消耗的操作符。
总结一下,此代码的 gas 消耗如下:
- 溢出情况下消耗 46 gas
- 非溢出情况消耗 46 gas
非常巧合,两者相等。
由于函数需要入口以方便访问,我们给出 MAIN 函数:
#define macro MAIN() = takes (0) returns (0) {
0x00 calldataload 0xE0 shr
dup1 __FUNC_SIG(addNumbers) eq addNumbers jumpi
dup1 __FUNC_SIG(safeAdd) eq safeAdd jumpi
addNumbers:
NON_SAFE_ADD()
safeAdd:
SAFE_ADD()
}
在后文中,我们不再给出 MAIN 函数,因为该函数即使读者无法理解仍可以照葫芦画瓢的写出对应的代码。
最后,我们给出测试代码。在测试前,请在 interface HuffMath 内增加以下接口:
function safeAdd(uint256, uint256) external pure returns (uint256);
具体的测试代码如下:
function test_safeAdd() public {
vm.expectRevert();
huffmath.safeAdd(type(uint256).max, 5);
}
function test_noramlsafeAdd() public {
uint256 result = huffmath.safeAdd(420, 5);
assertEq(result, 425);
}
test_safeAdd 检测溢出加法是否被 revert ,而 test_noramlsafeAdd 检测正常加法是否可以运行。
不可溢出乘法
依惯例,我们首先讨论如何判断乘法是否溢出?最简单的方法如下:
z = x * y
y != 0 && z / y != x
y != 0 && z / y != x 返回当前乘法是否溢出的布尔值。该算法的实质是如果溢出,那么就破坏了乘法和除法的对称性。
如何设计此算法,我建议读者使用自底向上的思考方法。不考虑 jumpi 跳转,我们需要如 [y != 0, z / y != x, z] 的栈结构。
逆推过程如下:
[y != 0, z / y != x, z] <-(iszero)-
[y == 0, z / y != x, z] <-(iszero)-
[y, z / y != x, z] <-(swap1)-
[z / y != x, y, z] <-(is_zero)-
[z / y == x, y, z] <-(eq)-
[z / y, x, y, z] <-(div)-
[z, y, x, y, z]
此处需要注意对逻辑运算取反需要使用 iszero 操作码而不是 not ,后者按位取反。此处没有继续向后推导,因为 [z, y, x, y, z] 显然是一个较好建立的栈结构,读者可以尝试自己构造后在于我的代码比较 gas 消耗,如果您的代码更加高效,可以在评论区给出。
将上述逆推过程改为前向推导:
#define macro SAFE_MULTI() = takes(0) returns (0) {
0x04 calldataload // [x]
0x24 calldataload // [y, x]
mul // [z]
0x24 calldataload // [y, z]
0x04 calldataload // [x, y, z]
dup2 // [y, x, y, z]
dup4 // [z, y, x, y, z]
div // [z / y, x, y, z]
eq iszero // [z / y != x, y, z]
swap1 // [y, z / y != x, z]
iszero iszero // [y != 0, z / y != x, z]
and // [is_overflow, z]
over_flow jumpi
0x00 mstore
0x20 0x00 return
over_flow:
0x00 0x00 revert
}
上述流程中的 over_flow 处理部分与 SAFE_ADD 是一致的。
接下来,我们给出一些测试:
function test_normalMulti() public {
uint256 result = huffmath.safeMulti(100, 5);
assertEq(result, 500);
}
function test_safeMulti() public {
vm.expectRevert();
huffmath.safeMulti(type(uint256).max, 50);
}
function test_zeroMulti() public {
uint256 result = huffmath.safeMulti(100, 0);
assertEq(result, 0);
}
进行这些测试前,请读者自行修改 interface HuffMath 接口。
最后,我们讨论一个简单的问题,如何对 huff 合约进行 debug 操作?随着 huff 合约的长度增加,我们需要进行一些 debug 操作以解决开发过程中的问题。
我们可以使用 forge test --debug $FUNC 命令实现,以上文给出的 test_normalMulti 为例,我们需要运行以下命令:
forge test --debug "test_normalMulti()"
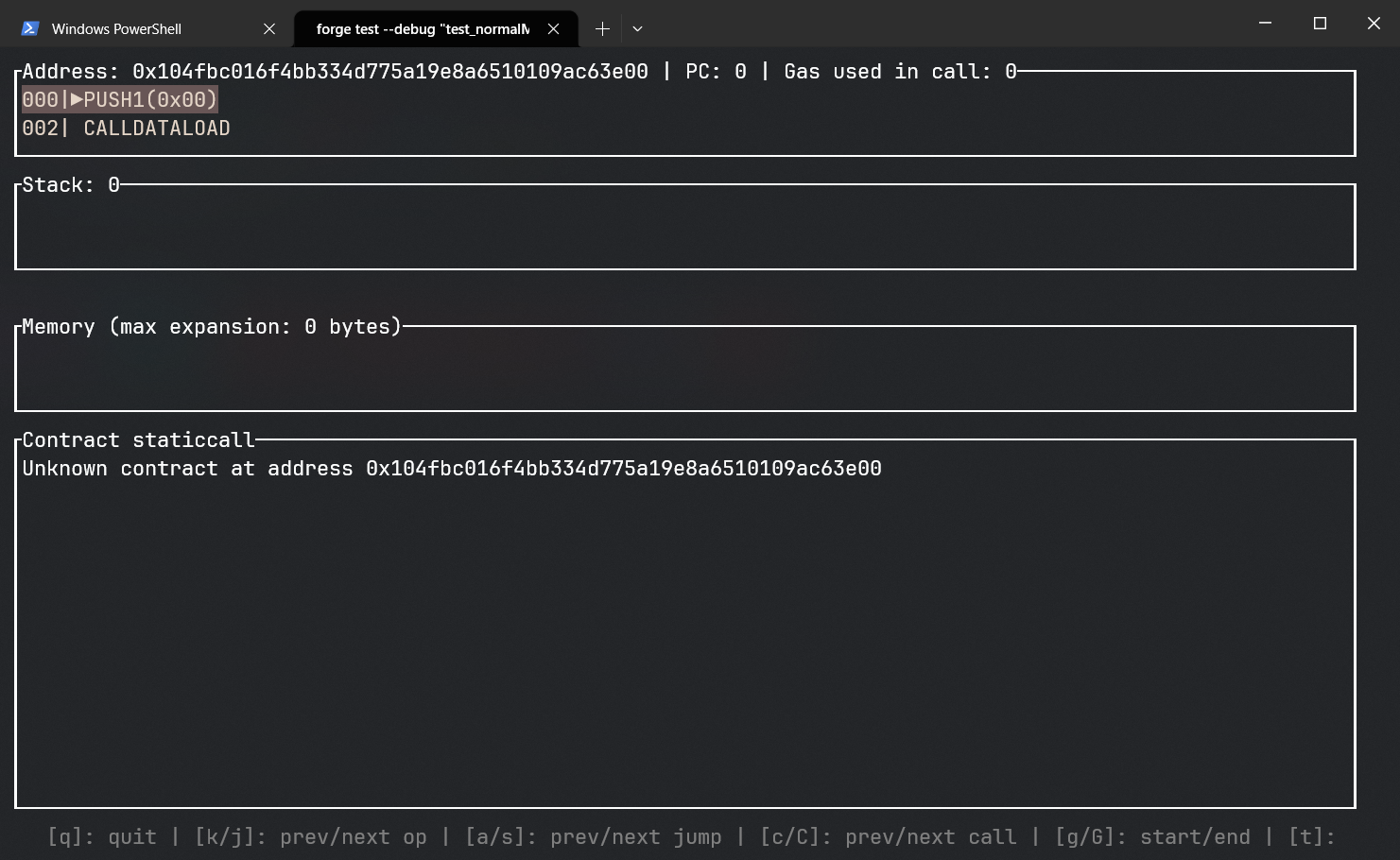
我们可以观察到以下界面:
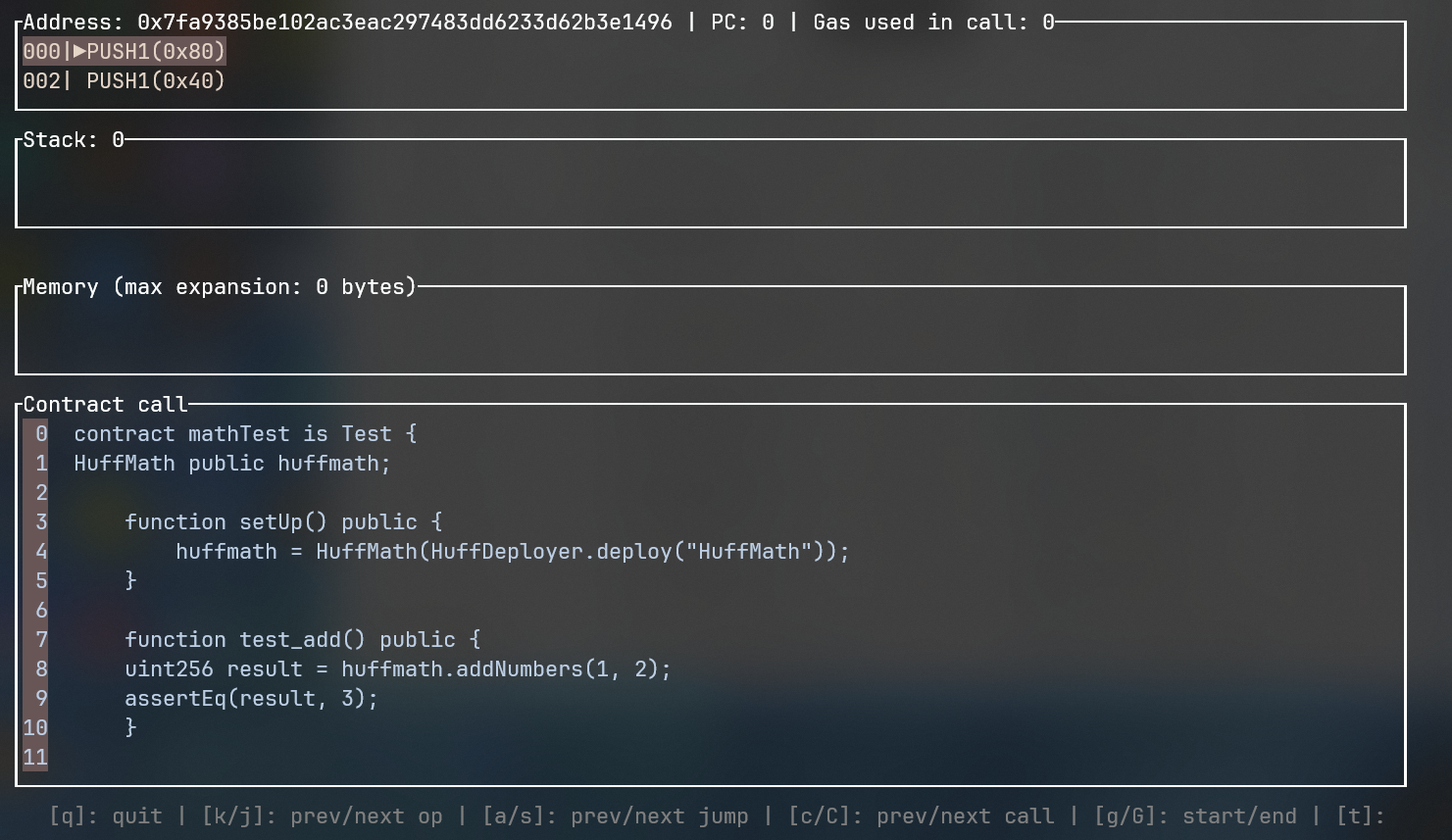
按下 C 键跳转到下个 call 请求,我们就进入了 HuffMath.huff 合约,如下:
点击 s 键,我们就可以进入 SAFE_MULTI 函数体,在最上框内我们可以看到与 huff 合约对应的操作码,如下图:
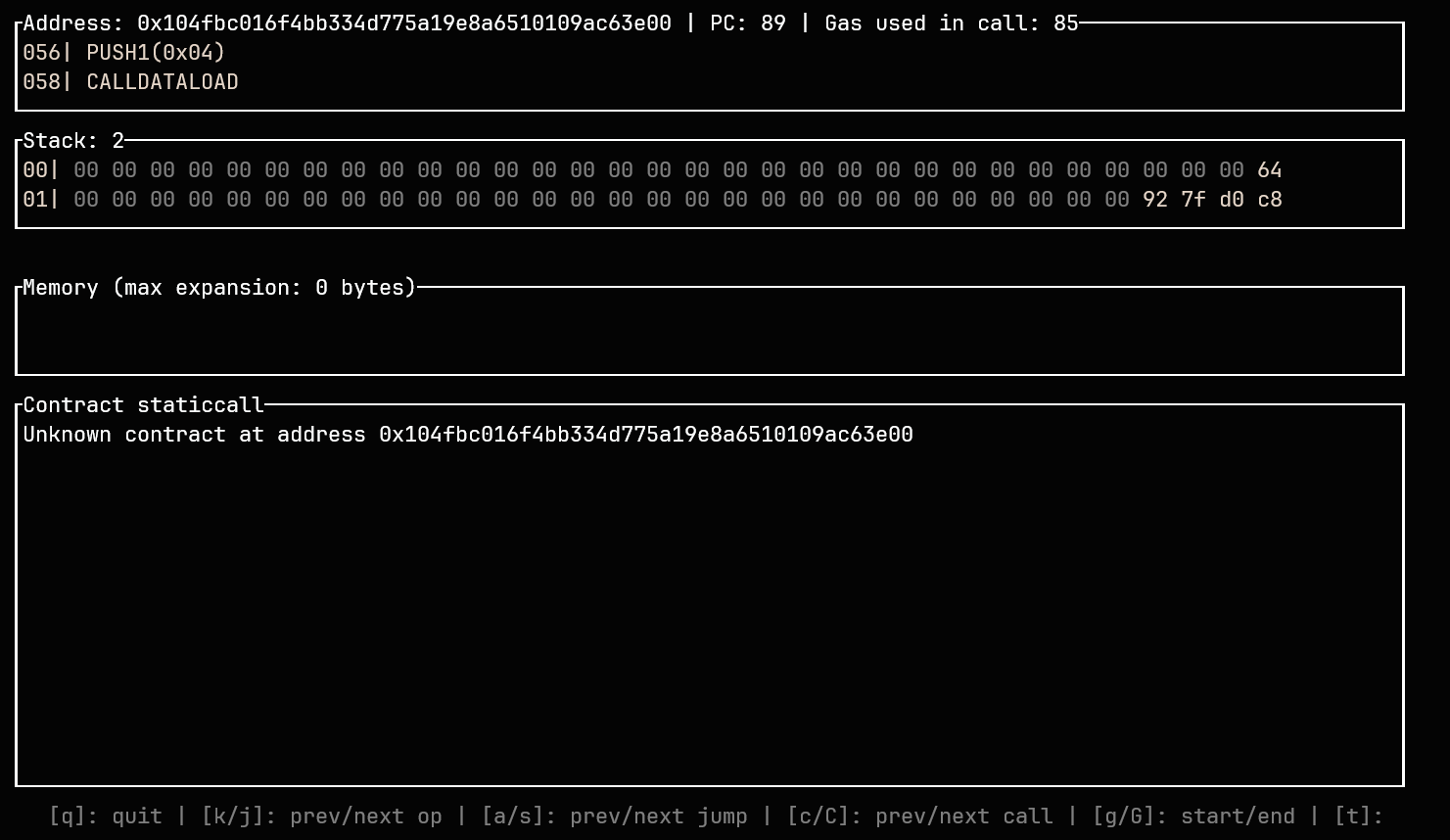
接下来,我们就可以根据 Stack 栏中的内容和 Memory 中的内容判断合约运行是否正常,在此处,我们也给出一些操作键:
q退出 Debug 模式J下滚 Stack 视图(如上图所示Stack视图仅能显示 2 行 Stack ,我们需要一些键来滚动)K上滚 Stack 视图Ctrl + j下滚内存视图Ctrl + k上滚内存视图
读者可以通过 Foundry Debugger 文档 获得更多键位信息。
事实上,我们可以使用另一种方法实现判断乘法是否溢出,该方法需要一个后文介绍的函数——前导零计数,该函数被简写为 nlz。该方法较为复杂,我们不给出具体的实现,但 nlz 函数的实现会在后文给出,因为该函数对于 log2 对数的实现有极其重要的作用。
前导 0 计数算法
我们首先给出前导 0 算法的 C 语言版本:
int nlz(unsigned x) {
int n;
if (x == 0) return(256);
n = 1;
if ((x >> 128) == 0) {n = n + 128; x = x << 128;}
if ((x >> 192) == 0) {n = n + 64; x = x << 64;}
if ((x >> 224) == 0) {n = n + 32; x = x << 32;}
if ((x >> 240) == 0) {n = n + 16; x = x << 16;}
if ((x >> 248) == 0) {n = n + 8; x = x << 8;}
if ((x >> 252) == 0) {n = n + 4; x = x << 4;}
if ((x >> 254) == 0) {n = n + 2; x = x << 2;}
n = n - (x >> 255);
return n;
}
此算法的原理是二分搜索,此算法来自 《算法心得》 第 91 页。
对应的 huff 代码为:
#define macro NLZ_COUNT() = takes(1) returns (1) {
0x1 // [n, x]
swap1 // [x, n]
dup1 // [x, x, n]
0x80 shr // [x >> 128, x, n]
iszero iszero // [x >> 128 != 0, x, n]
not_zero_128 jumpi // [x, n]
0x80 shl // [x << 128, n]
swap1 0x80 add // [n + 128, x << 128]
swap1 // [x, n]
not_zero_128:
dup1 // [x, x, n]
0xc0 shr // [x >> 192, x, n]
iszero iszero // [x >> 192 != 0, x, n]
not_zero_192 jumpi // [x, n]
0x40 shl // [x << 64, n]
swap1 0x40 add // [n + 64, x << 64]
swap1 // [x, n]
not_zero_192:
dup1 // [x, x, n]
0xe0 shr // [x >> 224, x, n]
iszero iszero // [x >> 224 != 0, x, n]
not_zero_224 jumpi // [x, n]
0x20 shl // [x << 32, n]
swap1 0x20 add // [n + 32, x << 32]
swap1 // [x, n]
not_zero_224:
dup1 // [x, x, n]
0xf0 shr // [x >> 240, x, n]
iszero iszero // [x >> 240 != 0, x, n]
not_zero_240 jumpi // [x, n]
0x10 shl // [x << 16, n]
swap1 0x10 add // [n + 16, x << 16]
swap1 // [x, n]
not_zero_240:
dup1 // [x, x, n]
0xf8 shr // [x >> 248, x, n]
iszero iszero // [x >> 248 != 0, x, n]
not_zero_248 jumpi // [x, n]
0x08 shl // [x << 8, n]
swap1 0x08 add // [n + 8, x << 8]
swap1 // [x, n]
not_zero_248:
dup1 // [x, x, n]
0xfc shr // [x >> 252, x, n]
iszero iszero // [x >> 252 != 0, x, n]
not_zero_252 jumpi // [x, n]
0x04 shl // [x << 4, n]
swap1 0x04 add // [n + 4, x << 4]
swap1 // [x, n]
not_zero_252:
dup1 // [x, x, n]
0xfe shr // [x >> 254, x, n]
iszero iszero // [x >> 254 != 0, x, n]
not_zero_254 jumpi // [x, n]
0x02 shl // [x << 2, n]
swap1 0x02 add // [n + 2, x << 2]
swap1 // [x, n]
not_zero_254:
0xff shr // [x >> 255, n]
swap1 sub
}
由于后文我们还会调用此算法,所以我们使用了 takes(1) returns (1) 标识。
在此代码中,我们尤其需要注意 jumpi 系列方法。此处使用 jumpi 实现了大量的跳转逻辑,充分显示 jumpi 在逻辑分支上的巨大作用。在使用 huff 时,我们需要转变一定的思路,比如在正常代码编写过程中,我们往往思考满足条件后运行某部分代码,但在 huff 中,我们需要考虑满足某些条件后跳过部分代码的运行。
在此处,我们在 C 语言版本中都使用了满足条件运行的逻辑,如满足 x >> 128) == 0 则运行 n = n + 128; x = x << 128; ,而在 huff 中,我们需要将其改写为当满足 x >> 128) != 0 条件时,我们跳过 n = n + 128; x = x << 128; 的运行。
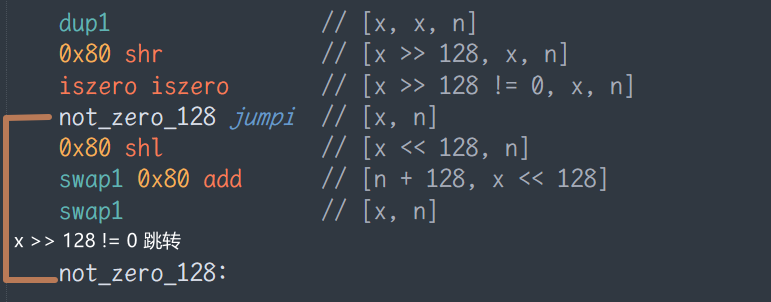
这就是为什么我们将跳转目的地 not_zero_128 放在了 0x80 shl 等代码的后面。
值得注意的是,我们在此处没有考虑输入值为 0 的情况,一旦考虑此情况,我们不能很好的安排 jumpi 。假如考虑输入值为 0 ,我们可以写出如下代码:
dup1 // [x, x]
iszero // [is_zero, x]
zero_return jumpi
...
0xff shr // [x >> 255, n]
swap1 sub
zero_return:
0x100
如果输入的值为 0 ,直接跳转到代码最后,返回 255 ,看似一切正常。如果输入的值不为 0 ,那么代码正常运行到 swap1 sub 部分,此时代码应该退出运行,但实际上不会,会继续运行,导致 0x100 被推入栈内。这种情况是很难处理的。所以此处我们直接省略了对输入值为 0 的处理。
为了方便测试,此处我们可以对其进行简单封装:
#define macro NLZ_COUNT_WRAPPER() = takes (0) returns (0) {
0x04 calldataload // [x]
NLZ_COUNT()
0x00 mstore
0x20 0x00 return
}
此处省略对 MAIN 函数的修改。
我们可以使用以下代码进行测试:
function test_nlzCount() public {
uint256 maxResult = huffmath.nlzCount(type(uint256).max);
assertEq(maxResult, 0);
uint256 normalResult = huffmath.nlzCount(0x18160ddd);
assertEq(normalResult, 227);
}
在此处提醒读者,《算法心得》内存在一系列可以使用查表法优化的函数,请读者务必不要使用 storage 存储这些表格,单次 sload 操作就会消耗 100 gas ,已经多于了上文给出的各种算法。一种可行的方法是将表格内容插入到部署字节码的尾部,使用 codecopy 提取这些表格内容。huff 提供了 constant 关键词实现了此功能,详细内容请参考 文档 。
log2 算法
可能已经有读者发现了 nlz 前导 0 计数本质上就是 log2 算法,当然,此处的 log2 算法指整数对数算法,记为 ilog2 ,其实质为 log2(x) 的向下取整。ilog2 算法的 C 语言实现如下:
int ilog2 (unsigned x) {
return 255 - nlz(x);
}
翻译为以下 huff 代码:
#define macro ILOG2() = takes (1) returns (1) {
NLZ_COUNT() // [nlz(x)]
0xff sub
}
为方便测试,我们对其进行简单封装:
#define macro ILOG2_WRAPPER() = takes (0) returns (0) {
0x04 calldataload // [x]
ILOG2()
0x00 mstore
0x20 0x00 return
}
测试代码如下:
function test_ilog2() public {
uint256 maxResult = huffmath.ilog2(type(uint256).max);
assertEq(maxResult, 255);
uint256 normalResult = huffmath.ilog2(0x18160ddd);
assertEq(normalResult, 28);
uint256 halfResult = huffmath.ilog2(0x10000000000000000);
assertEq(halfResult, 64);
}
开方算法
开方算法需要基于 ilog2 算法,我们会使用一种被称为牛顿法的迭代方法。我们需要首先估计得到 $\sqrt{\mathstrut a}$ 的初始值 $g_0$ ,然后使用如下公式迭代:
$$ g_{n+1} = (g_n + \frac{a}{g_n}) / 2 $$
该迭代式呈平方级收敛,即如果某个 $g_n$ 值精确到了 n 位,那么下一次迭代就会精确的 2n 位。也就是说,即使对 uint256 中最大的数字进行开方计算,我们也仅需要迭代 7 次。
$$ \log_2 \sqrt{a} = \log_2 g_0 \\ \frac{1}{2} \log_2{a} = \log_2 g_0 \\ g_0 = 2^{\frac{1}{2} \log_2{a}} $$
由此,我们得到了 $g_0$ 的计算方法。
依惯例,我们首先给出 C 语言实现:
int sqrt(unsigned x) {
unsigned result;
result = 1 << (log2(x) >> 1);
result = (result + x / result) >> 1;
result = (result + x / result) >> 1;
result = (result + x / result) >> 1;
result = (result + x / result) >> 1;
result = (result + x / result) >> 1;
result = (result + x / result) >> 1;
result = (result + x / result) >> 1;
return (result < x) / result ? result : (a / result);
}
在实现中,我们没有考虑具体的迭代轮数,而是选择了直接迭代 7 次,在物理机上,这种迭代方法是效率较低的,原因在于除法会消耗大量计算资源。但在 EVM 虚拟机中,单次除法仅需要 5 gas,而一次跳转则需要 10 gas,同时还要考虑跳转前后的处理。故而使用分支结构不如直接强行迭代 7 次。
这也说明了 EVM 的定价仍需要改进,消耗大量计算资源的除法定价太低,而分支跳转定价过高。当然,EVM 的 gas 不合理似乎也正常,但是很难给出一种改进方案。读者可以考虑引入定量模型以评估。
接下来,我们进入实操阶段:
#define macro SQRT() = takes (0) returns (0) {
0x04 calldataload // [x]
dup1 // [x, x]
iszero // [x == 0, x]
is_zero jumpi
dup1 // [x, x]
0x01 // [1, x, x]
dup2 // [x, 1, x, x]
ILOG2() // [log2(x), 1, x, x]
0x01 shr // [log2(x) / 2, 1, x, x]
shl // [result, x, x]
dup1 // [result, result, x, x]
swap2 div // [x / result, result, x]
add // [x / result + result, x]
0x01 shr // [result, x]
dup1 // [result, result, x]
dup3 // [x, result, result, x]
div add 0x01 shr // [result, x]
dup1 // [result, result, x]
dup3 // [x, result, result, x]
div add 0x01 shr // [result, x]
dup1 // [result, result, x]
dup3 // [x, result, result, x]
div add 0x01 shr // [result, x]
dup1 // [result, result, x]
dup3 // [x, result, result, x]
div add 0x01 shr // [result, x]
dup1 // [result, result, x]
dup3 // [x, result, result, x]
div add 0x01 shr // [result, x]
dup1 // [result, result, x]
dup3 // [x, result, result, x]
div add 0x01 shr // [result, x]
dup2 dup2 // [result, x, result, x]
gt // [result > x, result, x]
min_pop jumpi // [result, x]
swap1 // [x, result]
min_pop:
pop
is_zero:
0x00 mstore
0x20 0x00 return
}
在此处,我们处理输出值为 0 的情况。
测试代码如下:
function test_sqrt() public {
uint256 zeroResult = huffmath.sqrt(0);
assertEq(zeroResult, 0);
uint256 maxResult = huffmath.sqrt(2 << 253);
assertEq(maxResult, 2 << 126);
uint256 normalResult = huffmath.sqrt(100);
assertEq(normalResult, 10);
}
可能有读者想这样测试涵盖范围太少,我们能否对其进行 fuzz testing ,答案是可以,但我们需要引入一个新的测试技术,被称为 differential fuzzing 差分模糊测试,即将 huffmath.sqrt 的输出与可信输出对比。该测试依赖于一个重要的 foundry 函数 ffi ,该函数的作用是使用命令行命令调用一些其他程序以提供可信输入。值得注意的是,调用程序应该以 16 进制 abi 编码形式返回数据。
我们首先给出测试代码:
function test_sqrt(uint256 n) public {
uint256 huffResult = huffmath.sqrt(n);
string[] memory inputs = new string[](3);
inputs[0] = "python3";
inputs[1] = "sqrtTest.py";
inputs[2] = vm.toString(n);
bytes memory sqrtBytes = vm.ffi(inputs);
uint256 sqrtResult = uint256(bytes32(sqrtBytes));
assertEq(huffResult, sqrtResult);
}
我们首先调用 huffmath.sqrt 获得函数输出,然后我们使用 inputs 构造 ffi 调用程序所需要的命令。此处我们使用 uint256(bytes32(sqrtBytes)) 将 sqrtTest.py 返回的 16 进制 abi 编码的输出转化为 uint256 类型。我们认为 ffi 给出的输出是可信的,我们将两者使用 assertEq 进行比较。
ffi函数最不友好的就是处理输入输出数据,由于 solidity 有其自身的与其他编程语言不同的规范,导致 solidity 在调用外部程序时,转化数据类型是最复杂的工作
我们应当 ffi 调用外部程序是通过命令行完成的,ffi 会将 inputs 输入的项以空格隔开然后丢到命令行中运行,此处 ffi 构造的命令为 python3 sqrtTest.py n ,读者可根据自身系统更改此命令。
请读者在项目根目录下创建 sqrtTest.py 程序,写入以下内容:
import sys
import math
def main():
input = eval(sys.argv[1])
sqrt_result = math.floor((math.sqrt(input)))
print("{:0>64x}".format(sqrt_result), end="")
if __name__ == '__main__':
main()
需要注意以下几点:
- 程序应在命令行内获得输入,因为
ffi是通过调用命令行间接调用程序的 - 返回值应使用 16 进制 abi 编码,此处我们返回的整数型数据,编码较为简单,就是 16 进制编码后在其右侧填充 0 使其位数达到 64 位。更加复杂的数据类型编码可以考虑使用
web3.py等库 print的end务必是""空字符串,否则会出现问题
使用上述代码进行测试,发现测试失败,如下:
├─ emit log(: Error: a == b not satisfied [uint])
├─ emit log_named_uint(key: Expected, val: 7294724426814610)
├─ emit log_named_uint(key: Actual, val: 7294724426814609)
可见,我们编写的 huffmath.sqrt 似乎存在一点点问题。我们尝试修改 assertEq(huffResult, sqrtResult); 相等测试为 assertApproxEqAbs(sqrtResult, huffResult, 1) ,在小数量时,我们给出的代码会出现与测试结果差 1 的情况。然后,我们再次运行测试,发现再次失败:
├─ emit log(: Error: a ~= b not satisfied [uint])
├─ emit log_named_uint(key: Expected, val: 70009045392513186)
├─ emit log_named_uint(key: Actual, val: 70009045392513184)
├─ emit log_named_uint(key: Max Delta, val: 1)
├─ emit log_named_uint(key: Delta, val: 2)
该错误是诡异的,因为无法复现,读者可以使用以下合约进行测试:
function test_sqrt() public {
uint256 huffResult = huffmath.sqrt(4901266436770971757601341183870596);
assertEq(70009045392513186, huffResult);
}
会发现测试通过,如下:
[PASS] test_sqrt() (gas: 5861)
这就比较诡异了,怀疑是 fuzz testing 与 ffi 混合造成的错误。我们不再深究。
笔者在幕后也测试了我们编写的函数与
OpenZeppelin的sqrt函数的区别,两者的差最大为 1 ,证明我们编写 huff 版本是正确的。
数组数据解析
在 solidity 中较难处理且常见的数据结构是 Arrays 数组,我们准备通过一个简单的 sum 函数展示如何处理此数据类型。
在介绍具体的代码逻辑前,我们需要知道如何对数组类型进行编码,数组类型的编码是有一定复杂性的。我们以一个实例分析,如下:
[0]: 0000000000000000000000000000000000000000000000000000000000000020
[1]: 0000000000000000000000000000000000000000000000000000000000000005
[2]: 0000000000000000000000007c3b6affa750b73c1014f4c996e94bdb66c7ac6d
[3]: 0000000000000000000000008199809ff47feed049e7c93d005f571be10b6630
[4]: 000000000000000000000000bc24e980413edfb8b61c8ef6b860819b9105c9f9
[5]: 000000000000000000000000074c3330e9b1ffcf007f5189fc49583e42dbe0d4
[6]: 00000000000000000000000077cc211302ce7c4380dd4e00ac8144a72c2f22ff
上述是一个 address[] 类型的数组并按 256 bit 为一组进行了分割。其中第一组 [0] 表示动态数组在 calldata 的起始位置(以 bytes 为单位),由于有时候 calldata 中会出现静态类型与动态数组的混排,使用此变量可以帮助程序找到动态数组并处理。[1] 中包含该动态数组的长度,[2] 至 [6] 均为动态数组包含的数据。
我们可以使用
cast abi-encode "test(uint256[] memory)" "[1,2]"的命令生成类似上述编码的数组
我们准备编写一个 sum 函数,该函数签名如下:
#define function sum(uint256[]) nonpayable returns (uint256)
作用是将输入的 uint256[] 进行求和。
分析数组类型编码,显然,我们需要以下数据:
- 数组长度
length - 已读数组长度
readed - 当前元素的位置
now - 下一元素的位置
next - 求和数据
sum
由于此处没有出现数组参数和常规参数的混用,我们可以直接计算得到上述数据:
0x24 calldataload // [length]
0x01 // [readed, length] fix readed
0x00 // [sum, readed, length]
0x64 swap1 // [sum, next, readed, length] fix next
0x44 // [now, sum, next, readed, length]
calldataload // [element, sum, next, readed, length]
add // [sum, next, readed, length] add sum
在此处,我们使用 fix readed 表示对 readed 的更新,使用 fix next 表示对下一元素的位置的更新,使用 add sum 表示对 sum 的求和。
请勿属于汉语注释,
huffc编译器无法处理汉语注释
在我们读取了上述数据后,我们需要进行 readed 与 length 的大小比较,避免越界访问。
dup4 dup4 // [readed, length, sum, next, readed, length]
lt // [readed < length, sum, next, readed, length]
iszero
array_end jumpi // [sum, now, readed, length]
当 readed >= array_end 时,我们直接跳转到最后返回数据。可能有读者感觉 readed >= array_end 会导致少读取一个元素。我们可以假想进行 3 个元素的 array 的循环。
length = 3
readed = 0
第一轮循环:
读取第 1 个元素
readed = 1
readed >= length 不成立
第二轮循环:
读取第 2 个元素
readed = 2
readed >= length 不成立
第三轮循环:
读取第 3 个元素
readed = 3
readed >= length 成立,跳出循环
可见,我们准备的循环跳出条件是可以遍历所有元素的。
此处再次提醒读者,在
huff中,我们考虑if条件满足跳过某部分代码,而不是常规编程语言中if条件满足进入某部分代码
此处,我们还没有实现具体的循环逻辑,仅手动读取了第 1 个元素。在 huff 中,循环逻辑的实现需要 jump 操作码,该操作码意味着无条件跳转。我们可以通过此操作码定义无限循环,使用 jumpi 跳出循环。上述论述是抽象的,我们直接给出 sum 函数的循环部分,如下:
array_for: // [sum, now, readed, length]
dup2 calldataload // [element, sum, now, readed, length]
add // [sum, now, readed, length] add sum
swap1 0x20 add // [next, sum, readed, length] fix next
swap2 0x01 add // [readed, sum, next, length] fix readed
swap1 // [sum, readed, next, length]
dup4 dup3 lt // [readed < length, sum, readed, next, length]
iszero
array_end jumpi // [sum, readed, now, length]
dup3 calldataload // [element, sum, readed, now, length]
add // [sum, readed, now, length] add sum
swap2 0x20 add // [next, readed, sum, length] fix next
swap1 0x01 add // [readed, next, sum, length] fix readed
swap2 // [sum, next, readed, length]
dup4 dup4 // [readed, length, sum, next, readed, length]
lt // [readed < length, sum, next, readed, length]
iszero
array_end jumpi // [sum, now, readed, length]
array_for jump
array_end:
0x00 mstore
0x20 0x00 return
我们使用 array_for 和 array_for jump 语句构成了一个无限循环,另一方面使用 jumpi 进行循环跳出。为达成循环的目的,我们必须保证 array_for 和 array_for jump 两处的栈相同,读者可以发现在循环语句块内,我没有仅读取 1 个元素而是读取了 2 个元素。该方法是以部署时的高空间换运行时的低 gas。当然,读者也可以考虑每次循环仅读取一个元素,但这样意味着读者要花费大量的操作码进行栈重排。
我们可以使用以下代码进行测试:
function test_sum() public {
uint256[] memory oneArrary = new uint256[](5);
oneArrary[0] = 42;
oneArrary[1] = 22;
oneArrary[2] = 16;
oneArrary[3] = 20;
oneArrary[4] = 120;
uint256 huffResult = huffmath.sum(oneArrary);
assertEq(huffResult, 220);
}
总结
本文所有代码位于 Github 仓库 中,读者可以参考。如果读者发现任何值得优化的地方,可以随时 PR
本文主要介绍了终极 gas 效率开发语言 huff ,读者应该可以感受到 huff 仅比纯以太坊汇编甜一点点,主要增加了 jumpi 和 jump 的语法糖,这些语法糖使我们可以直接使用 label: 和 label 配对进行跳转。另一方面,huff 也帮我们省略了 PUSH 系列操作符,给出 0x24 等纯 16 进制编码数组,huff 编译器会自动匹配对应的 PUSH 操作码将其推入栈内。
本文基本介绍了常见的所有语言开发模式,如 if 分支和 for 循环等基础操作,可以感受到 huff 相比 solidity 其实更加易学,因为没有数据类型的划分。huff 另一个优点是极强的 gas 感知度,相比与 solidity 开发者,huff 开发者对函数的 gas 消耗是高度敏感的。
事实上, solidity 合约的 IR 编译模式可以弥补其缺陷,但在国内则少见讨论,未来可能推出一篇关于 IR 的文章。
本文给出的所有代码有都没有使用除栈以外的 EVM 结构,原因在于内存和存储操作都是较为昂贵的,尤其是存储操作。内存操作单次读操作消耗 6 gas 是正常的,而写操作也会消耗一定 gas 。权衡下,我仅使用了栈数据结构。
本文部分代码参考了 huff 官方推出的 HuffMate ,读者感兴趣可以去阅读。