概述
在Python中存在GIL机制,该机制保证了在Python中同时间内仅能运行一行代码,这导致了Python无法真正实现多线程。但Python中存在另一种神奇的机制,即异步机制。在计算机领域,我们经常提到异步、并行、多线程等名词,但本文不想讨论这些名词具体的含义,这些对于概念的讨论在很多情况下是无意义的。本文将专注于介绍异步机制,在本文的最后,我们会引入多线程等内容以进一步提高Python性能。
本文主要讨论以下内容:
- 异步的概念与
Hello World - 异步编程的基本模型和关键词
- 异步的实现机制
- 完整的异步爬虫示例
- 增加多线程支持的性能更强的异步爬虫
由于异步属于Python中较为先进且不断变化的机制,笔者使用了3.11作为基准版本,本文中的大部分代码可能无法在3.11以下版本运行,笔者会尽可能将低版本兼容方案列出。本文也将使用以下库:
- aiohttp
- aiofiles
请读者自行使用pip进行安装。如果您遇到error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/报错,请参考我在CSDN写的如何在Python中简单地解决Microsoft Visual C++ 14.0报错一文。
异步的概念与Hello World
异步是指在程序运行过程中,一些等待操作(如IO操作)不会阻塞代码的运行。该概念较为抽象,我们给出一个非异步的代码示例:
import time
def count():
print("One")
time.sleep(1)
print("Two")
def main():
for _ in range(3):
count()
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"Code runtime: {elapsed:.2f}")
上述代码较为简单,运行结果如下:
One
Two
One
Two
One
Two
Code runtime: 3.01
当主函数运行到count()时,函数首先输出One,然后因为time.sleep会暂停 1 秒,然后继续输出Two。我们可以看到time.sleep使整个代码进入的停顿情况,在这sleep的 1 秒内,所有的运行都被停止。接下来,我们给出一个异步版本:
import asyncio
async def count():
print("One")
await asyncio.sleep(1)
print("Two")
async def main():
await asyncio.gather(count(), count(), count())
if __name__ == "__main__":
import time
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Code runtime: {elapsed:.2f}")
在此处,我们引入了一些不太常见的函数:
asyncio.sleep异步计时器asyncio.gather此函数用于并发执行一系列函数,这里的并发并不意味着后续三个count()函数一起运行,具体原理会在下文讨论asyncio.run此函数用于启动异步任务main()await等待调用
根据文档相关表述,一个更加现代但仅适用
3.11的代码如下:async def main(): async with asyncio.TaskGroup() as tg: for i in range(3): tg.create_task(count())
上述代码运行结果如下:
One
One
One
Two
Two
Two
Code runtime: 1.01
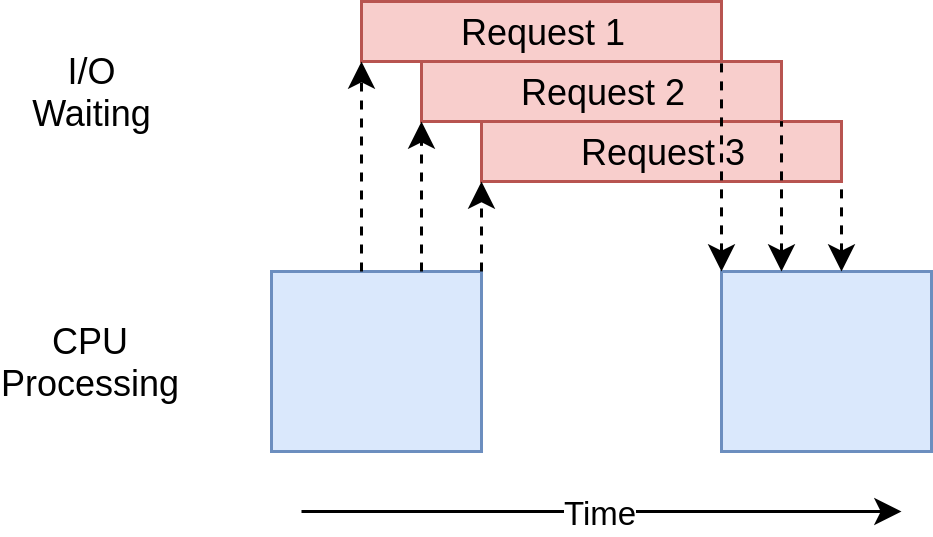
显然,此代码运行速度更快,且输出结果也与同步版本不符,其运行流程图如下:

在asynio.gather函数运行后,第一个count()函数启动,运行并输出One,但其运行到await asyncio.sleep(1)会运行asyncio.sleep暂停运行,将控制权交还给主函数,主函数继续运行下一个count()函数,重复上一流程。当第一个count()函数暂停满 1 秒后,它会取得运行权限,将Two进行输出,其他count()函数类似。
我们可以发现await事实上的含义为运行函数等待返回,并等待返回数据过程中交出控制权使其他函数运行。
在现实的编码实例中,我们可以考虑asyncio.sleep(1)为一耗时的系统操作,这一操作不需要Python代码运行而仅需要Python等待运行结果返回,比如网络请求。在网络请求过程中,发送数据包和接收数据包都较为快速,对于爬虫而言,大部分时间浪费在等待数据返回的过程中,这一等待过程中Python不需要操作。所以我们可以引入异步机制让Python在此等待时间内进行其他工作。另一个比较常见的案例即读取文件,读取文件的过程并不是Python完成的,Python只是在读取文件时向操作系统发出请求,等待操作系统返回文件内容,这一过程也是浪费的时间,可以通过异步方法使Python进行其他工作。
值得注意的是,Python的原生实现,包括requests等网络请求库均没有实现上述异步特性,为实现异步,我们需要引入概述中给出的两个库,其中:
aiohttp实现网络请求异步aiofiles实现文件读取异步
基本模型
本节主要介绍一些在异步编程中常用的编程模型。
第一种就是最简单的链式异步调用,我们以一个简单的例子进行介绍。目前存在一个简单的API进行GET请求后会返回用户信息列表,我们需要请求此API并print结果。首先,我们给出基于requests的同步版本:
import requests
import time
from requests import session
def get_api(s: session):
url = "https://mocki.io/v1/d4867d8b-b5d5-4a48-a4ab-79131b5809b8"
req = s.get(url).json()
print(req)
def main():
s = session()
for i in range(3):
get_api(s)
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"Code runtime: {elapsed}")
对于读者而言,此类型代码都是可以快速写出的,运行后发现运行时长为 2.70 秒左右。
考虑使用满足异步方法的aiohttp修改此版本:
import time
import asyncio
import aiohttp
from aiohttp import ClientSession
async def aio_get_api(s: ClientSession):
url = "https://mocki.io/v1/d4867d8b-b5d5-4a48-a4ab-79131b5809b8"
req = await s.get(url)
print(await req.json())
async def aio_main():
async with ClientSession() as session:
task = [aio_get_api(session) for _ in range(3)]
await asyncio.gather(*task)
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(aio_main())
elapsed = time.perf_counter() - s
print(f"Code runtime: {elapsed}")
相较于同步版本,异步版本并没有更加复杂。首先,我们需要注意异步函数(即函数体内包含await的函数)均需要使用async def进行定义。对于aiohttp而言,get和json等方法都是异步的。对于我们而言,可以无脑的在所有异步操作前增加await关键词。正如上文所述,每当代码运行到await后,就会进行函数操作后将控制权交换给主函数。至于主函数如何调度这些请求,我们在此处并不需要进行研究。
此处我们使用了ClientSession类型,此类型的重要作用是维护请求参数等,在aiohttp文档内,建议仅维护一个ClientSession作为所有请求的发送者。此处也需要注意ClientSession类似文件类型,其需要在代码运行完成后执行退出操作。此处,我们为了简化此过程使用了with关键词。当然,由于with内部包含await关键词,所以with需要使用async with替代。另一个需要替代的是async for,但在此处我们没有使用。
上述异步代码的运行时间为 1.43 秒左右,显然快于同步版本。
第二种比较常用的使用异步+队列。
假设我们需要编写一个爬虫,此爬虫从我们给定的URL开始爬取内容,并提取该URL中的链接,然后依次爬取链接中的页面,再提取链接,重复上述流程。在此流程内,使用列表并不是一个好主意,当我们读取完某个链接后需要删除,但列表对此操作并不友好。在此处,我们使用了一个特殊的数据类型队列(queue)。
此处我们通过以下案例介绍此模式,访问豆瓣图书详情页,我们可以看到如下图书推荐部分:

查询源代码,如下图:
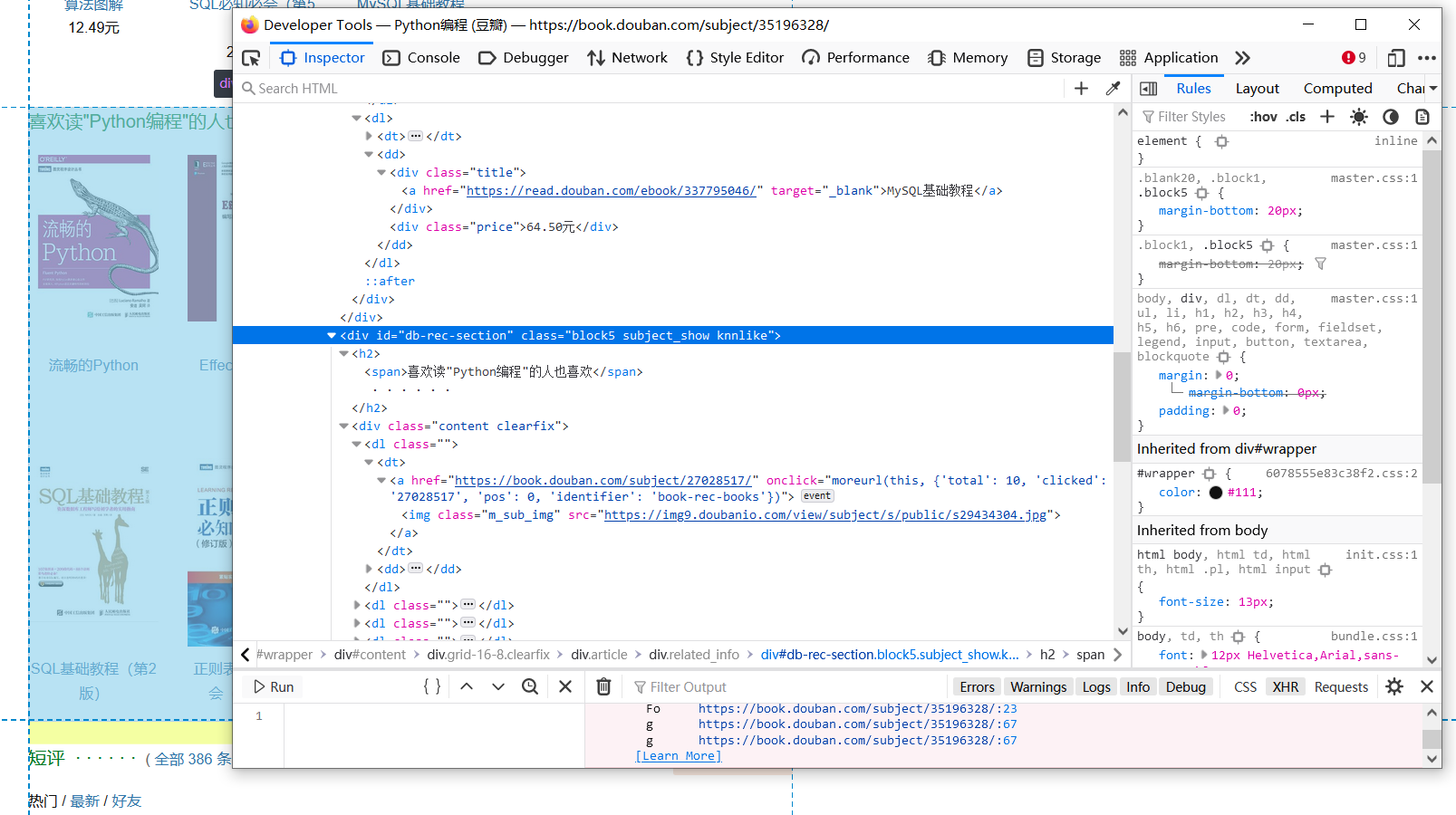
我们很容易写出抽取相关内容的代码,使用bs4库进行抽取,代码如下:
soup = BeautifulSoup(raw_html, 'lxml')
rec_div = soup.find(id="db-rec-section")
for dt in rec_div.find_all("dt"):
url = dt.find("a").get("href")
print(url)
通过此方法,我们可以抽取图书推荐栏内其他推荐图书的链接。我们希望构建一个爬虫,该爬虫可以进一步抓取每一个推荐图书的推荐图书,依次递推。
这意味着我们需要向爬虫提供之前爬取过的相关链接。显然,我们需要使用队列,维护一个由推荐图书URL构成的队列,爬虫从此队列内获得爬取的链接,在爬取结束后,将爬取的链接再推入队列。此流程可以很好的实现我们需要的功能。
具体代码如下:
import aiohttp
import asyncio
import time
from aiohttp import ClientSession
from bs4 import BeautifulSoup
async def exact_rec_book(raw_html: str, q: asyncio.Queue) -> str:
soup = BeautifulSoup(raw_html, 'lxml')
rec_div = soup.find(id="db-rec-section")
for dt in rec_div.find_all("dt"):
url = dt.find("a").get("href")
print(url)
if url:
await q.put(url)
else:
pass
async def crawler(name: int, s: ClientSession, q: asyncio.Queue) -> None:
url = await q.get()
req = await s.get(url)
html = await req.text()
await exact_rec_book(html, q)
async def main():
q = asyncio.Queue()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Language': 'en,en-US;q=0.8,zh-CN;q=0.7,zh;q=0.5,zh-TW;q=0.3,zh-HK;q=0.2',
}
await q.put("https://book.douban.com/subject/35196328/")
async with ClientSession(headers=headers) as session:
task = [crawler(name, session, q) for name in range(5)]
await asyncio.gather(*task)
if __name__ == "__main__":
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Code runtime: {elapsed}")
其中,exact_rec_book用于提取链接并将其推入URL队列,crawler是爬虫的主体函数,main用于启动此异步爬虫。
此处需要注意,我们在task中设置了 5 个爬虫函数,查询上述豆瓣页面,每个页面内包含 10 个页面,所以我们的爬虫应该返回 50 个页面链接。
如果您希望每个函数多运行几次,可以在
crawler进行如下修改:async def crawler(name: int, s: ClientSession, q: asyncio.Queue) -> None: for _ in range(3): url = await q.get() req = await s.get(url) html = await req.text() await exact_rec_book(html, q)上述修改可以是爬取过程重复三次,即意味着爬取 150 个链接 我们不建议大量调高上述设置,这可能导致您被豆瓣网站拉黑
由于豆瓣网站对UA进行了限制,此处我们使用了自己设置的headers以应对反爬。此处我们也在主函数最开始向队列推入了启动变量。
上述代码运行结果如下:
https://book.douban.com/subject/27028517/
...
Code runtime: 7.696796900010668
上述基本涵盖了异步过程中的主要模型,我们接下来介绍一些神奇的小组件以实现一些特殊功能。
Semaphore信号量机制。此机制用于控制一次可异步运行的函数数量。
首先给出未受信号量控制的代码,如下:
import asyncio
import time
async def hello(name: int):
await asyncio.sleep(1)
print(f"{name} Finish...")
async def main():
task = [hello(i) for i in range(6)]
await asyncio.gather(*task)
s = time.perf_counter()
asyncio.run(main())
elapsed = time.perf_counter() - s
print(f"Code runtime: {elapsed}")
运行结果显而易见如下:
0 Finish...
2 Finish...
5 Finish...
4 Finish...
1 Finish...
3 Finish...
Code runtime: 1.0051071000052616
上述输出说明 6 个协程一同运行,接下来,我们使用信号量进行修改,要求每次最多允许运行 2 个协程,修改hello()函数,如下:
limit = asyncio.Semaphore(2)
async def hello(name: int):
async with limit:
await asyncio.sleep(1)
print(f"{name} Finish...")
其他代码与之前相同,运行输出如下:
0 Finish...
1 Finish...
2 Finish...
3 Finish...
4 Finish...
5 Finish...
Code runtime: 3.0241502999851946
此处我们将信号量使用async with limit:的形式将需要限制的代码包裹起来就可以实现限制其异步运行的效果。如果需要限制上文给出的豆瓣爬虫函数,可以进行如下修改:
async def crawler(name: int, s: ClientSession, q: asyncio.Queue) -> None:
url = await q.get()
async with limit:
req = await s.get(url)
html = await req.text()
await exact_rec_book(html, q)
信号量本质上是一个计数器,当协程需要运行时则向计数器发起acquire请求,计数器减少 1 2; 当协程运行结束后,则向计数器请求release请求,计数器增加 1 。本质上流程如下:
sem = asyncio.Semaphore(10)
# ... later
await sem.acquire()
try:
# work with shared resource
finally:
sem.release()
我们可以使用with语句简化,如下:
sem = asyncio.Semaphore(10)
# ... later
async with sem:
# work with shared resource
异步原理
本节主要介绍异步在Python中实现的一些基本原理,如果您对此不感兴趣,可以跳过。
在介绍异步运行前,我们需要首先给出一个概念,即生成器(generator iterators),以下代码给出了一个简单的生成器:
def easy_range(n):
i = 0
while i < n:
t = yield i
if t is None:
pass
else:
i = t
i += 1
我们可以使用如下代码对其进行调用:
my_range = easy_range(10)
print(next(my_range))
print(next(my_range))
print(my_range.send(4))
当我们第一次调用next(my_range)时,代码Debug如下:
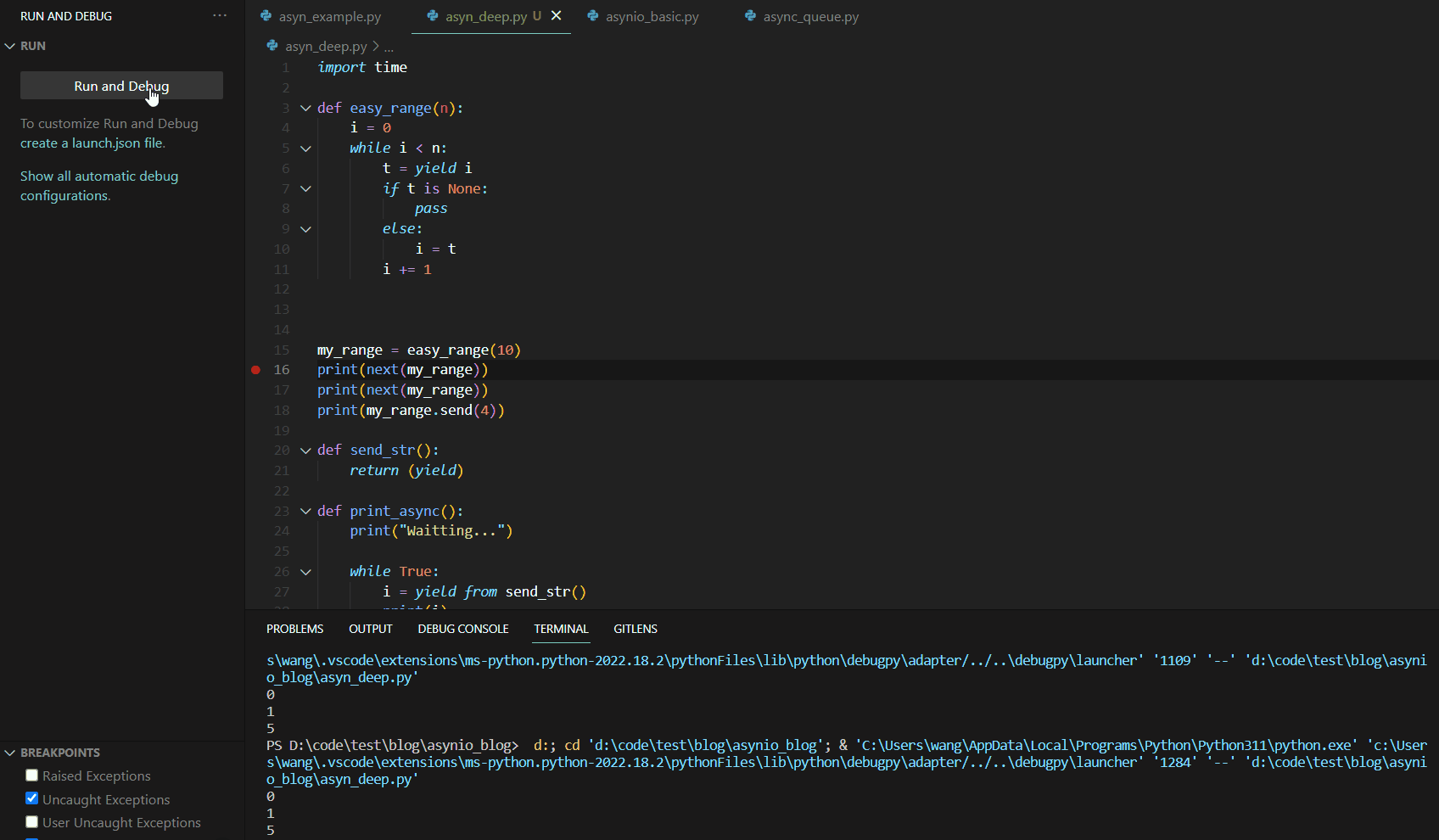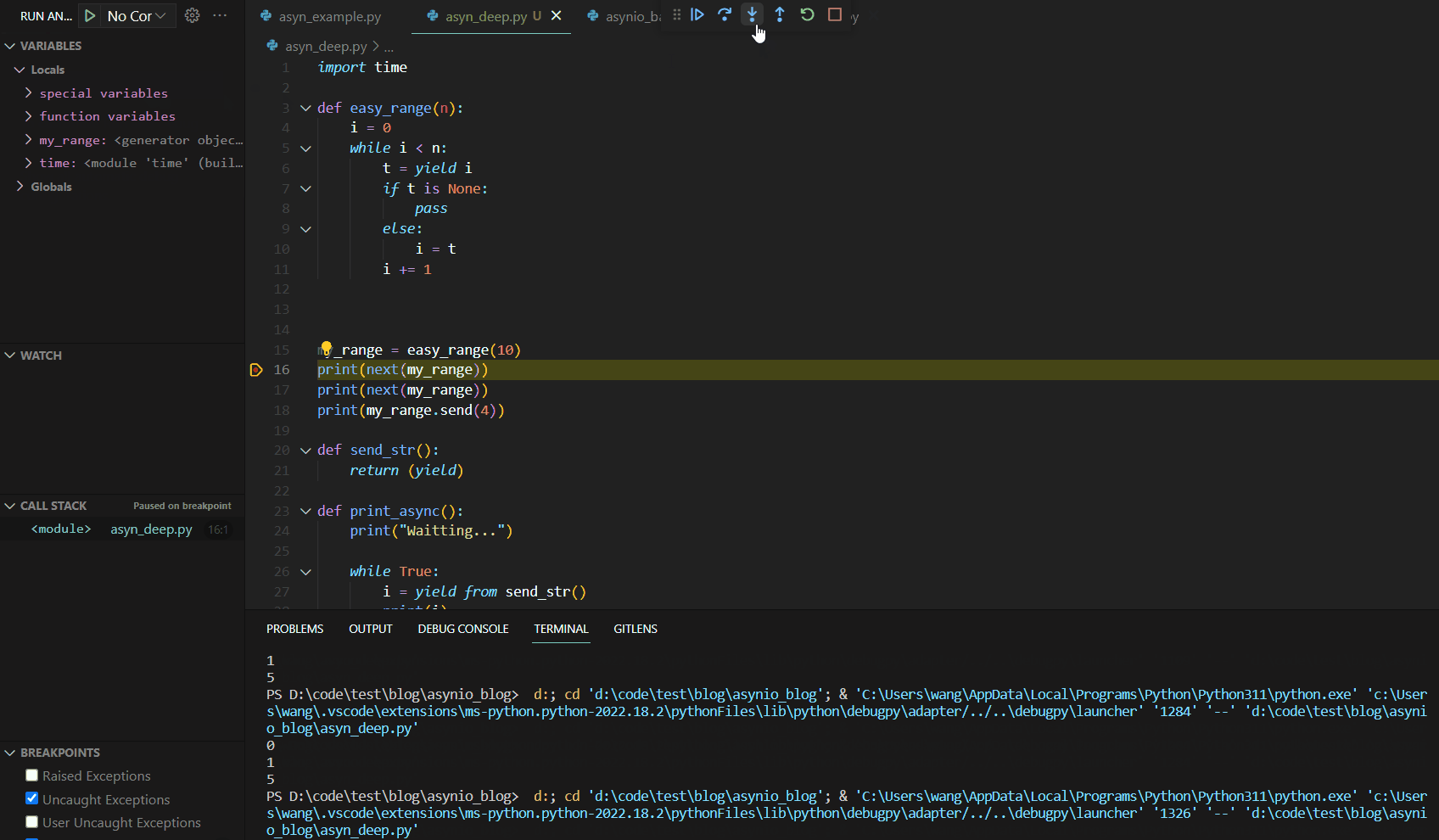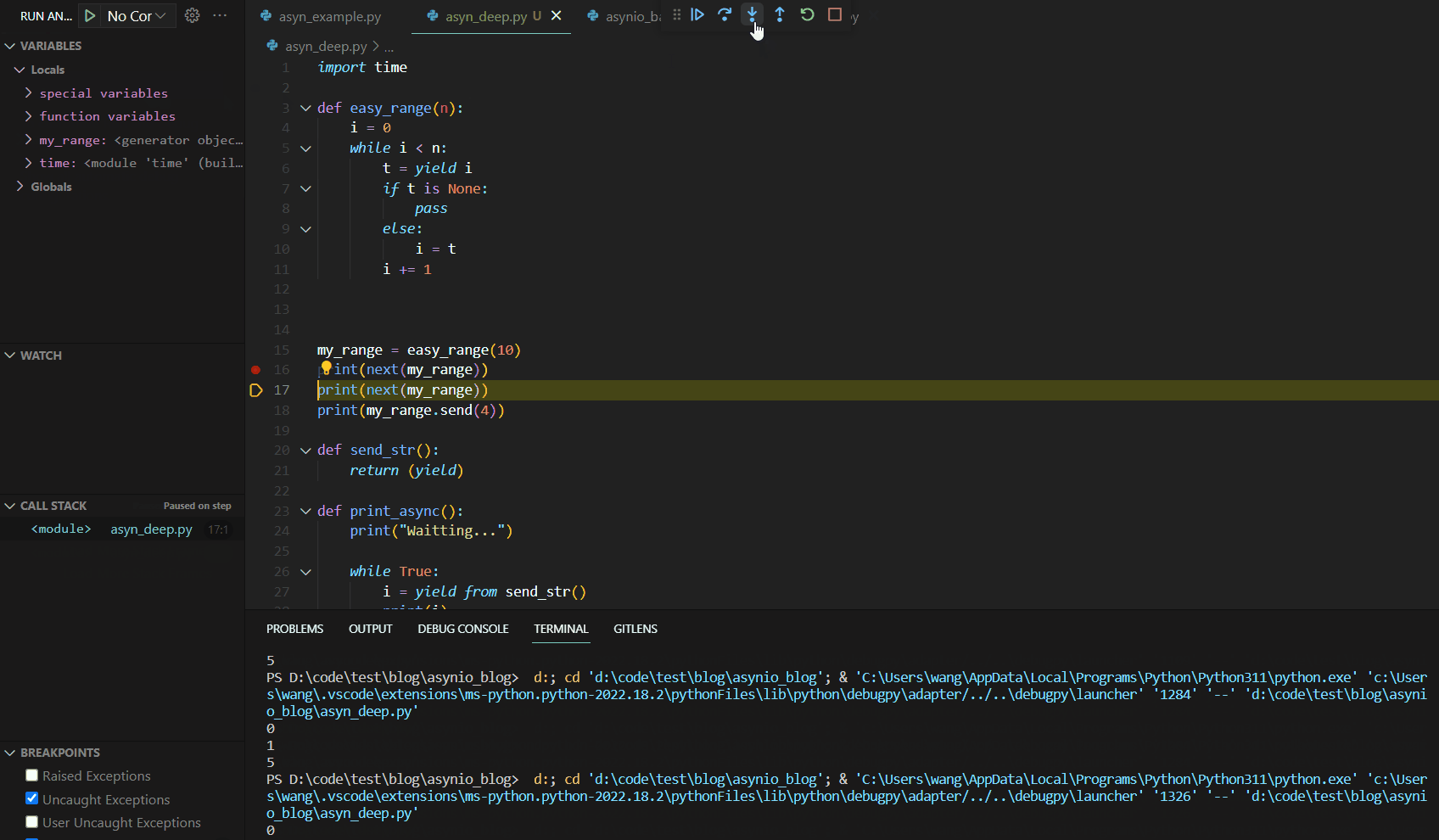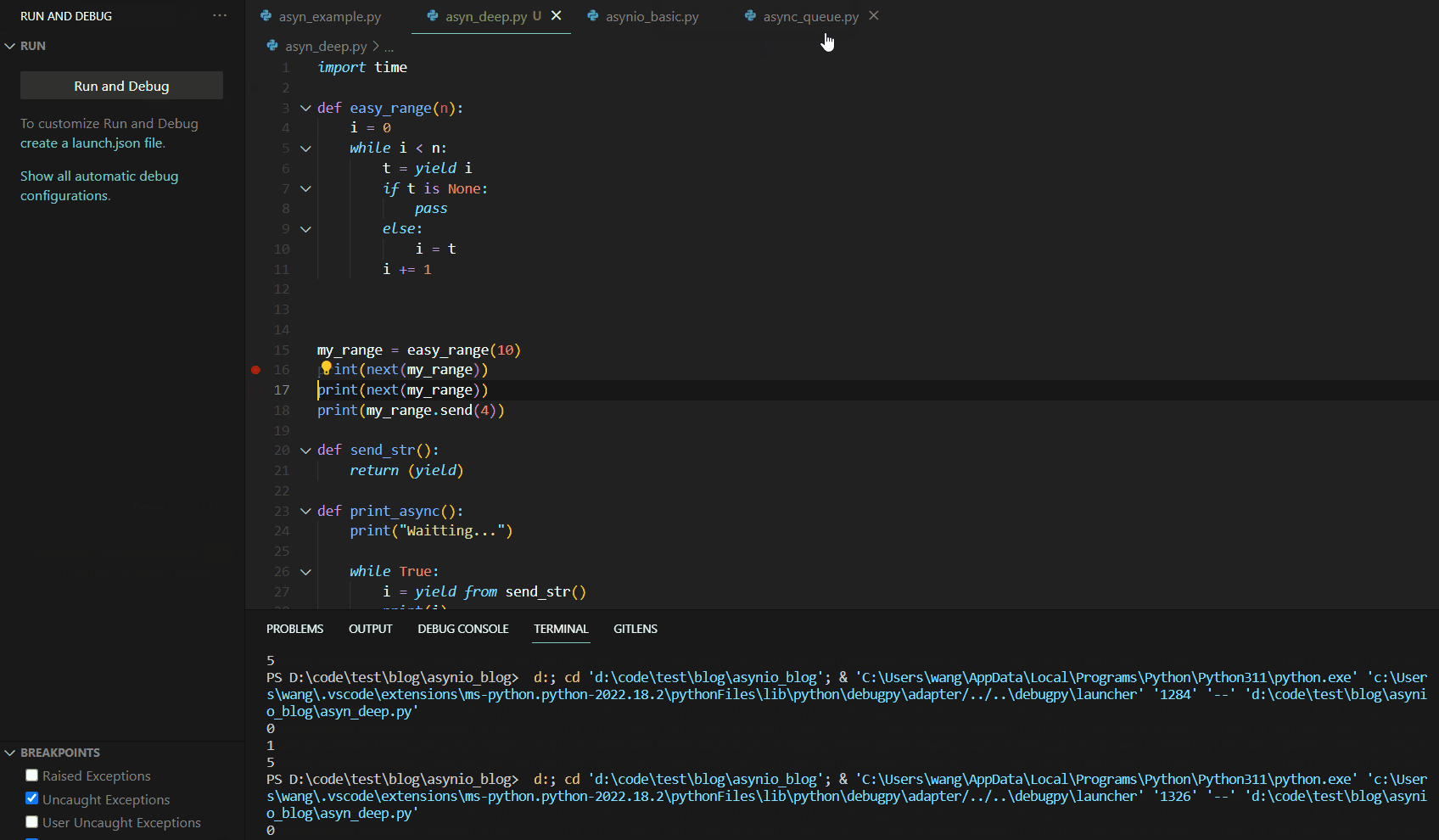
可见第一次调用next()函数时,函数运行到yield语句就停止了。这与我们的异步编程中的暂停机制有异曲同工之妙。接下来,我们分析第二个next,其Debug如下:
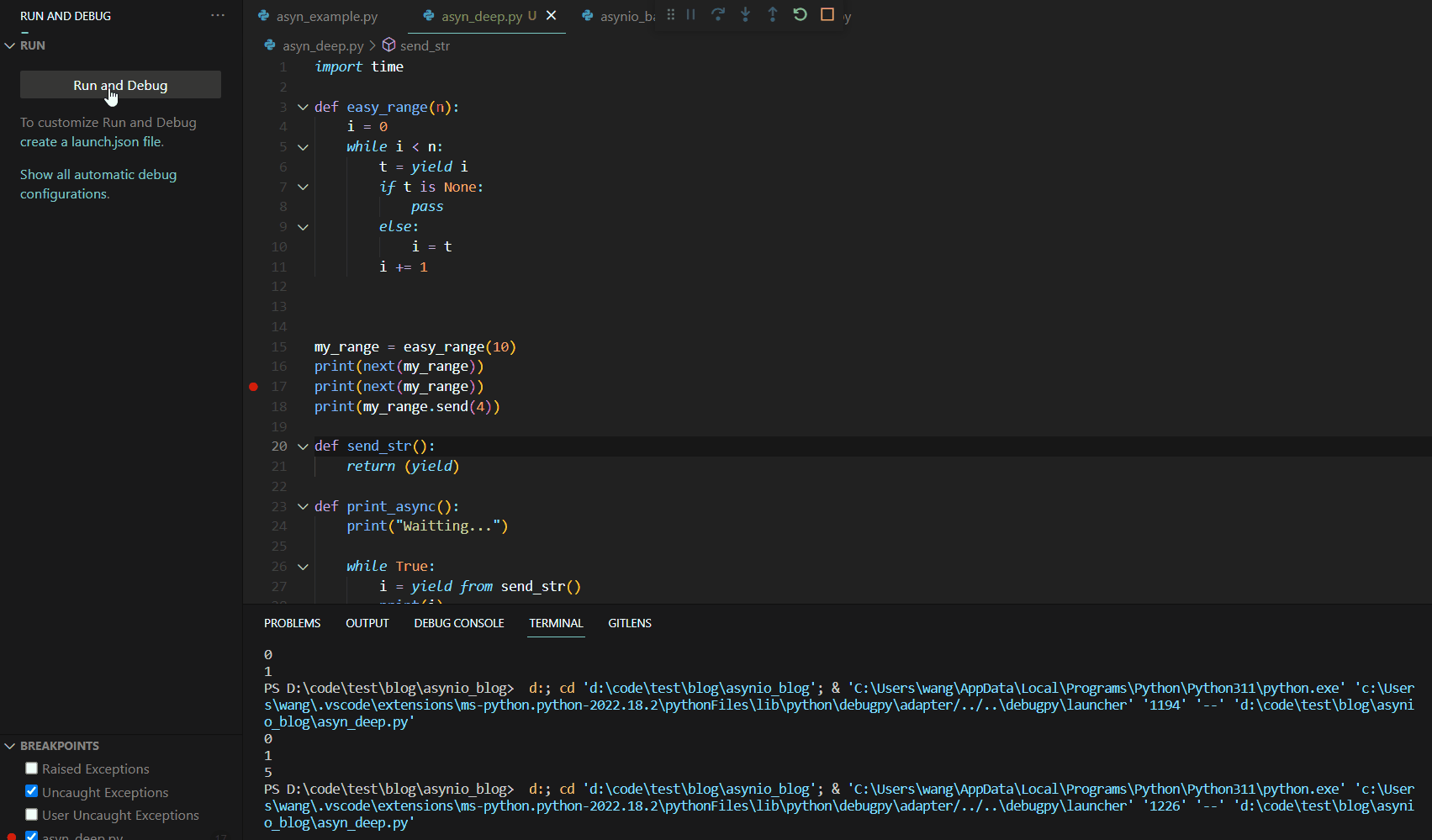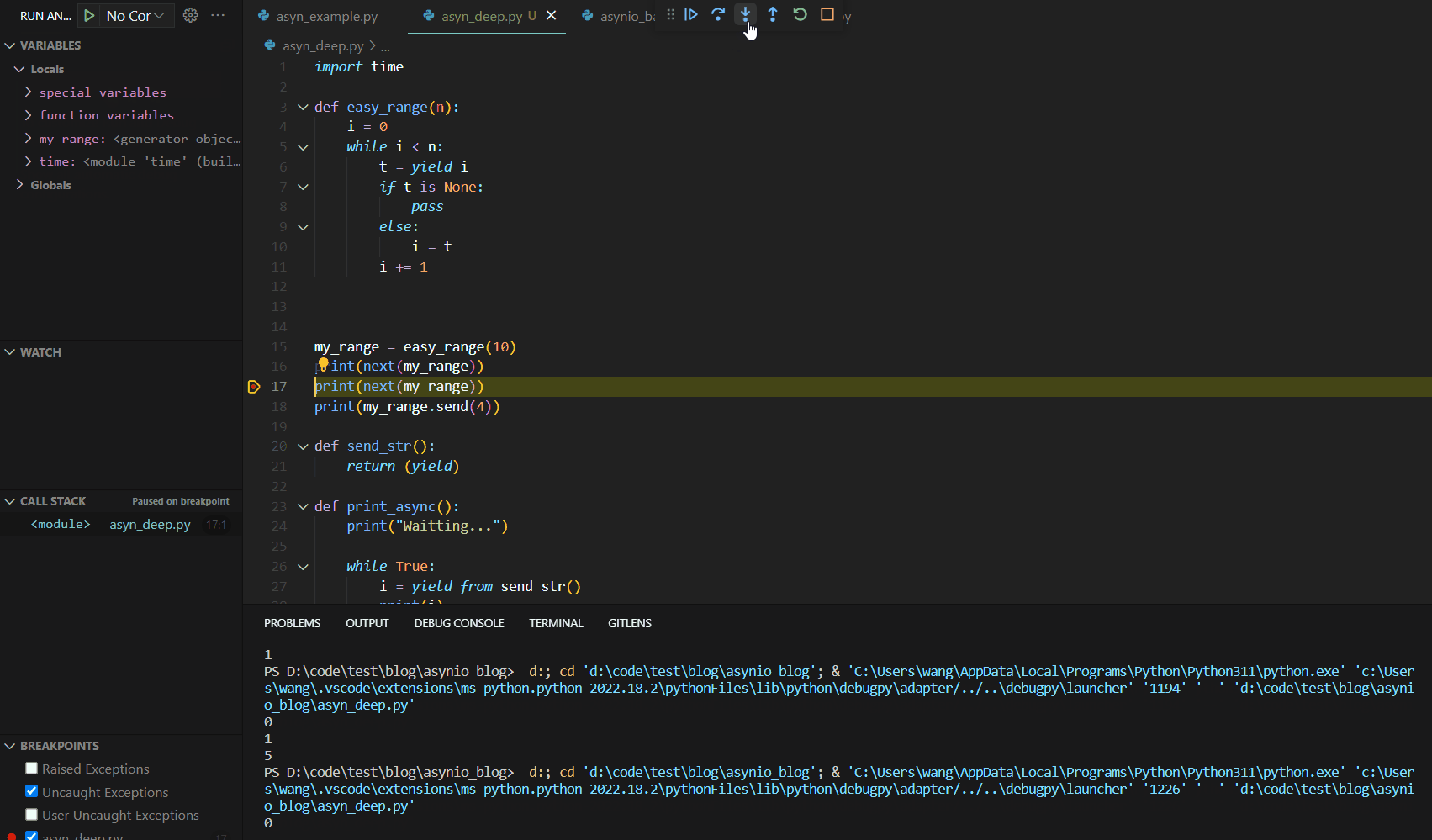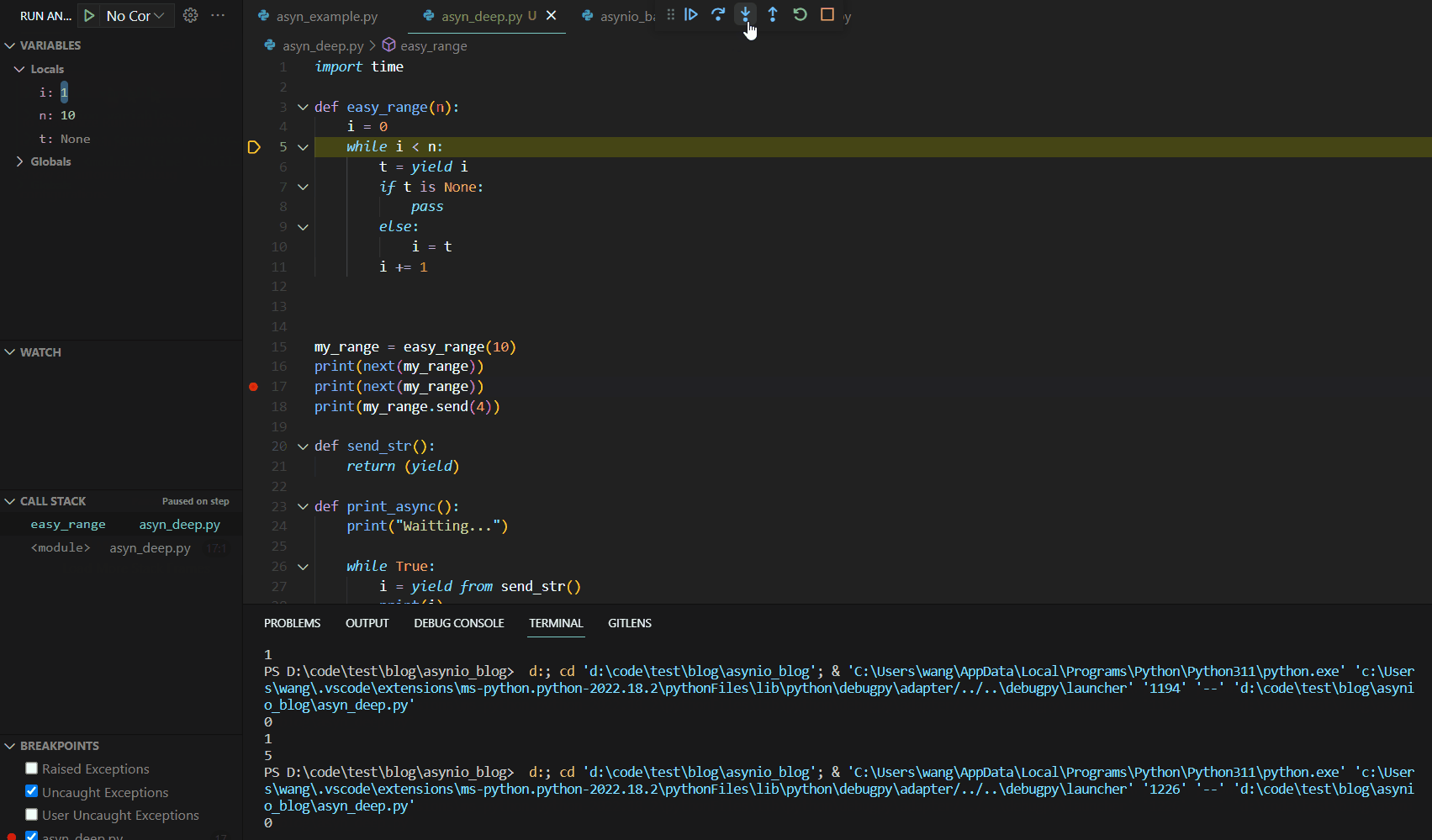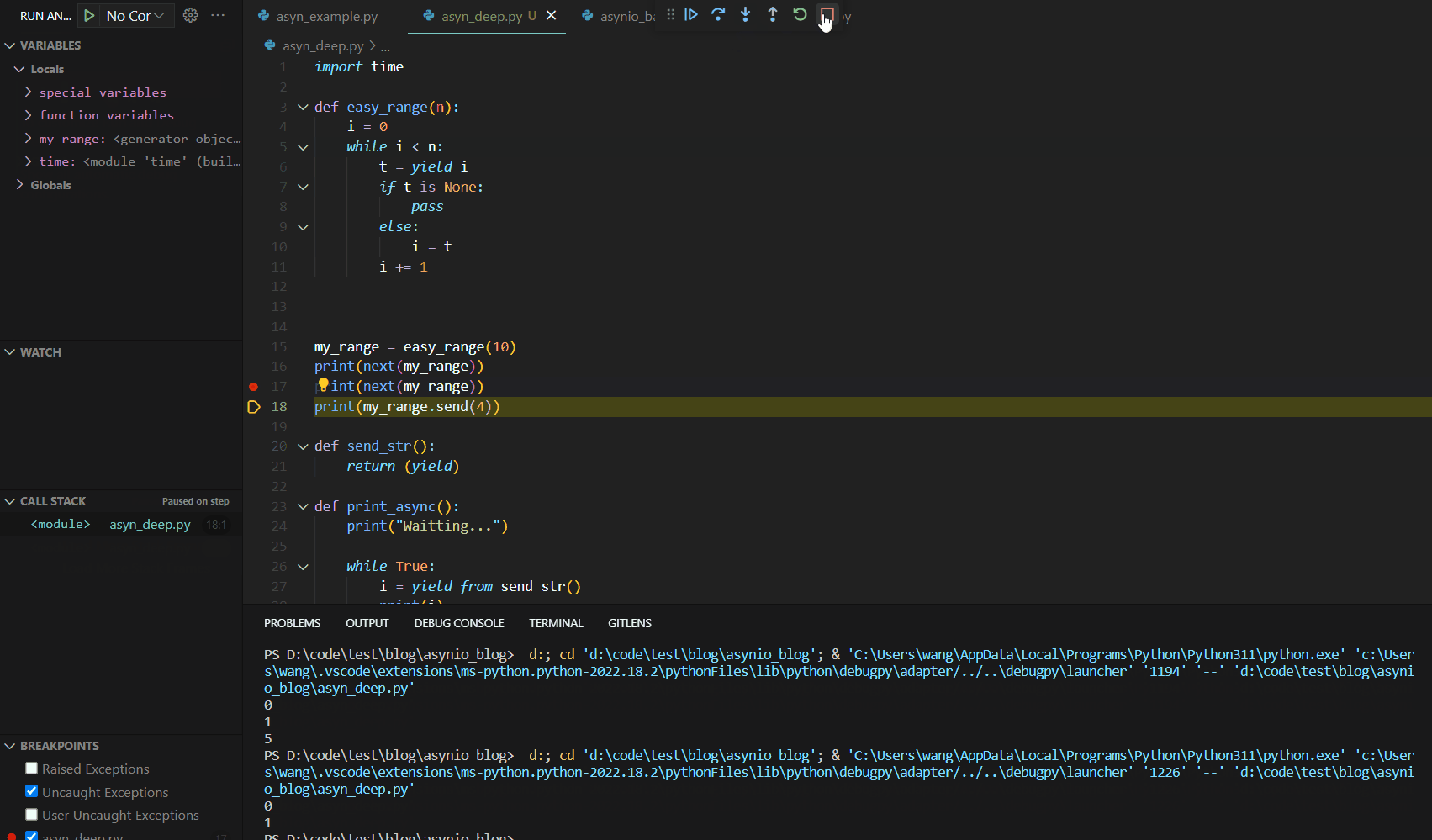
关注左侧的VARIABLES变量展示栏,我们可以看到此处的Locals函数本地变量保存了我们上次初始化后的结果,代码运行从yield的下一行开始运行到函数最后,然后跳转到代码块最开始进行条件判断,然后进入代码块运行到yield结束。
此处,我们可以总结yield的运行特性:
- 第一次调用
next方法会在生成器函数(此处为easy_range)的最开始运行直到yield结束 - 生成器函数会保存函数内变量直至下一次调用使用
- 第二次调用
next方法时会在yield下一行开始运行代码,运行至代码块最后,然后跳转到代码块开始判断条件,之后继续运行到yield语句或抛出StopIteration异常
此处,我们可以发现yield暂停代码运行的方法与await类似,但此处仍存在一个问题,await一方面会交出函数控制权,这可以通过yield暂停函数运行的功能实现,另一方面,await可以将其后跟随的函数返回值注入回原函数使原函数继续运行(如req = await s.get(url),s.get(url)运行结束后会将返回值注入给req),此功能无法仅通过yield实现。
我们首先解决注入问题,此处使用了不常见的关键词send,其运行逻辑如下:
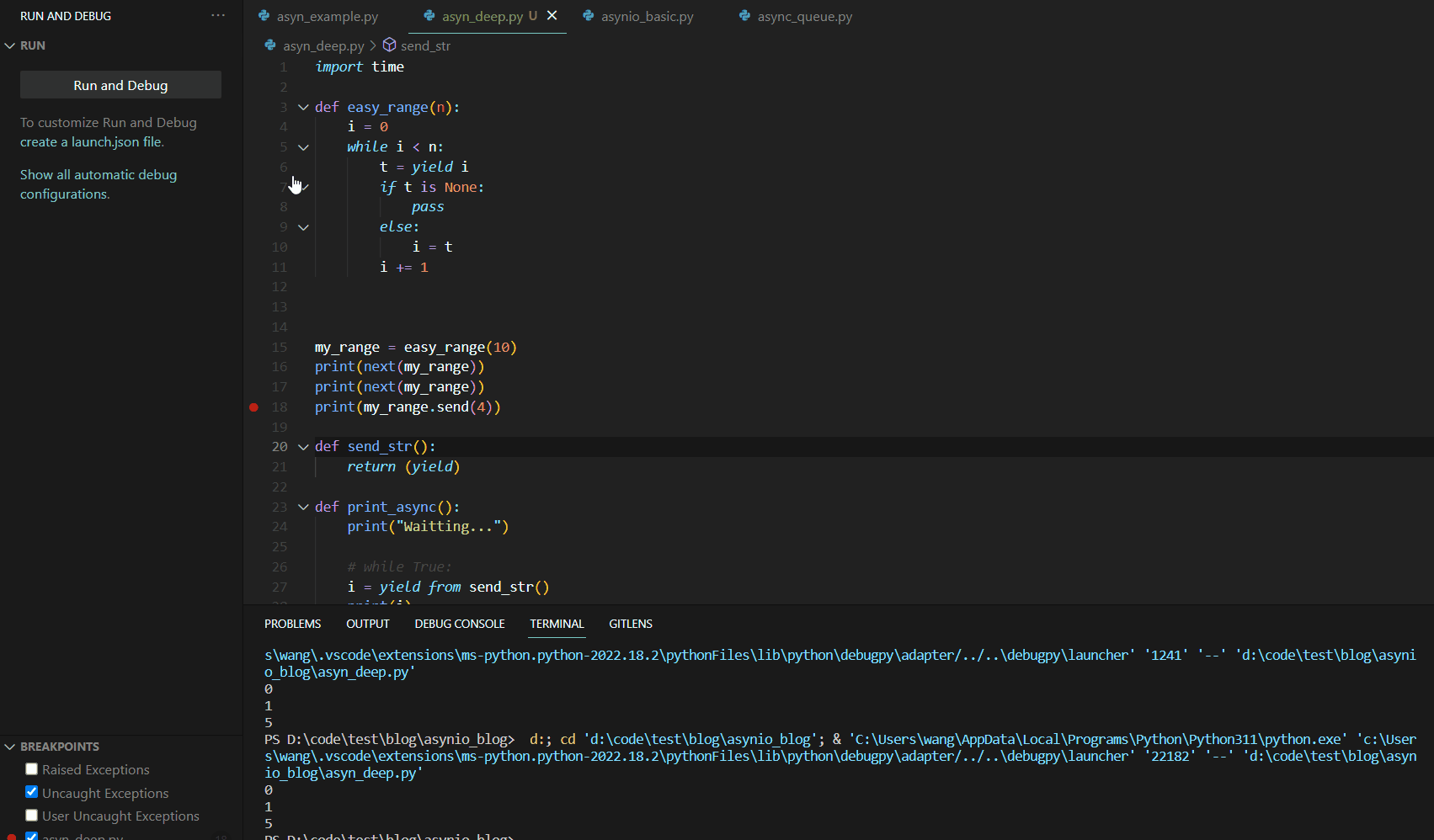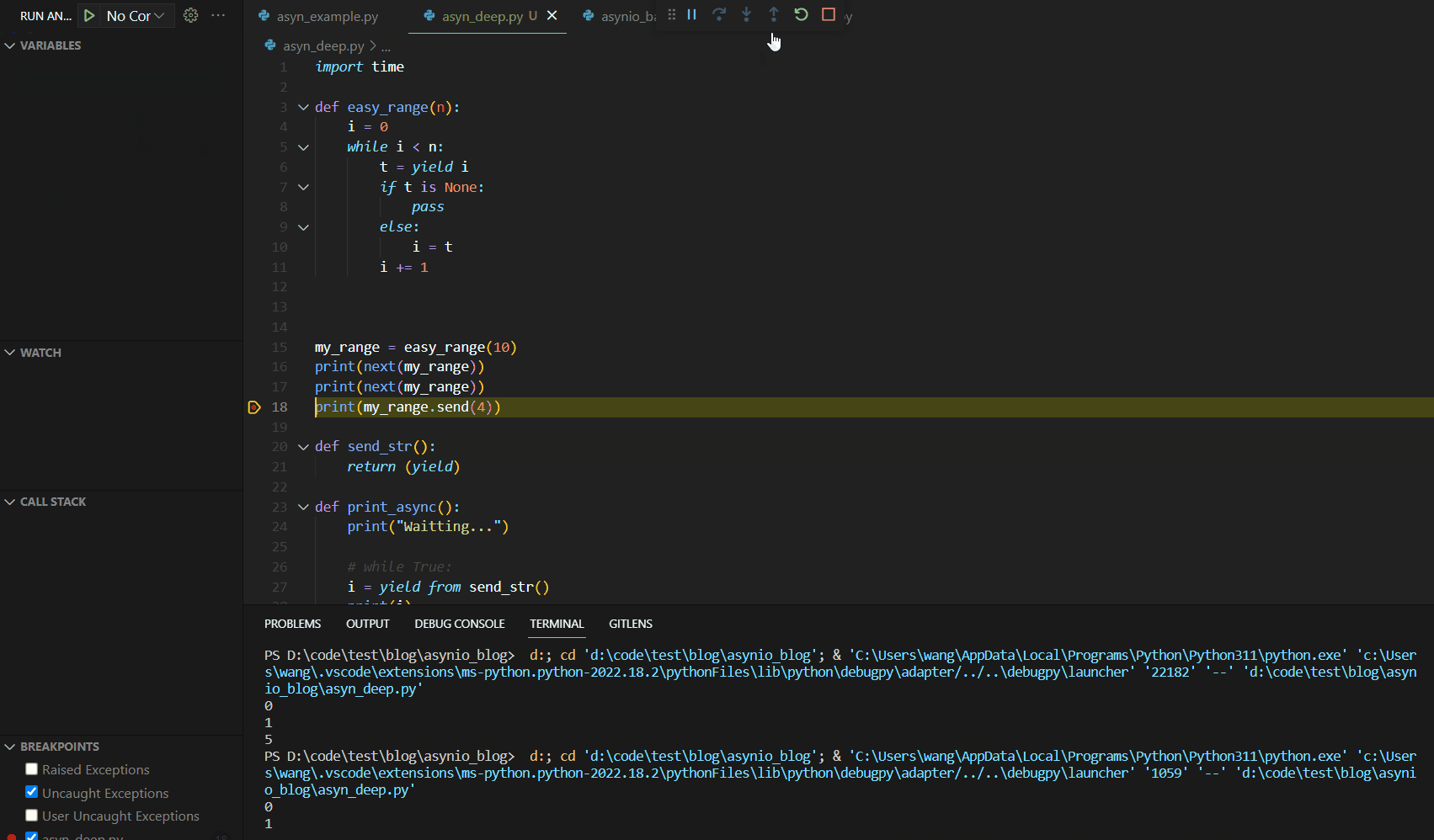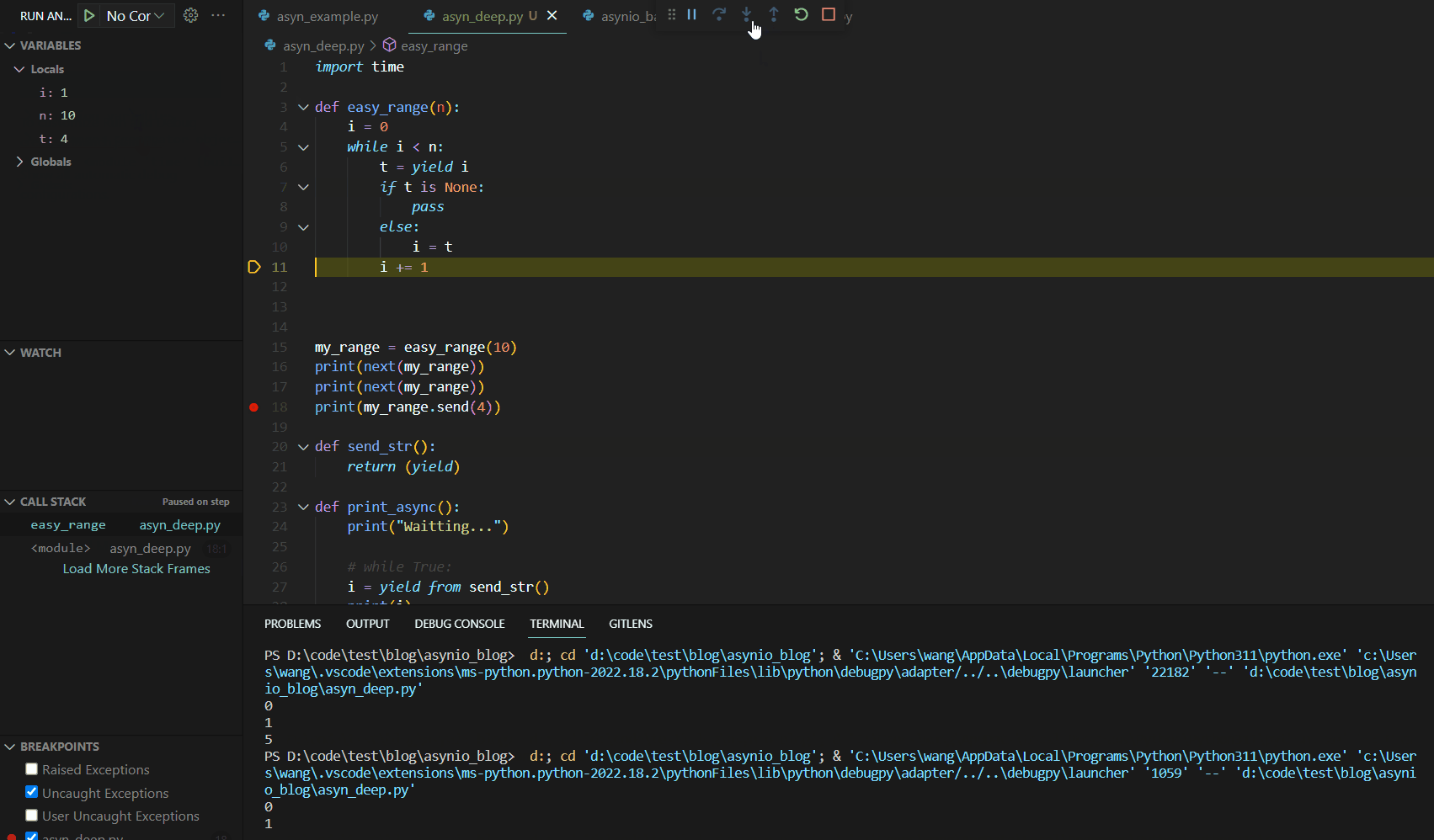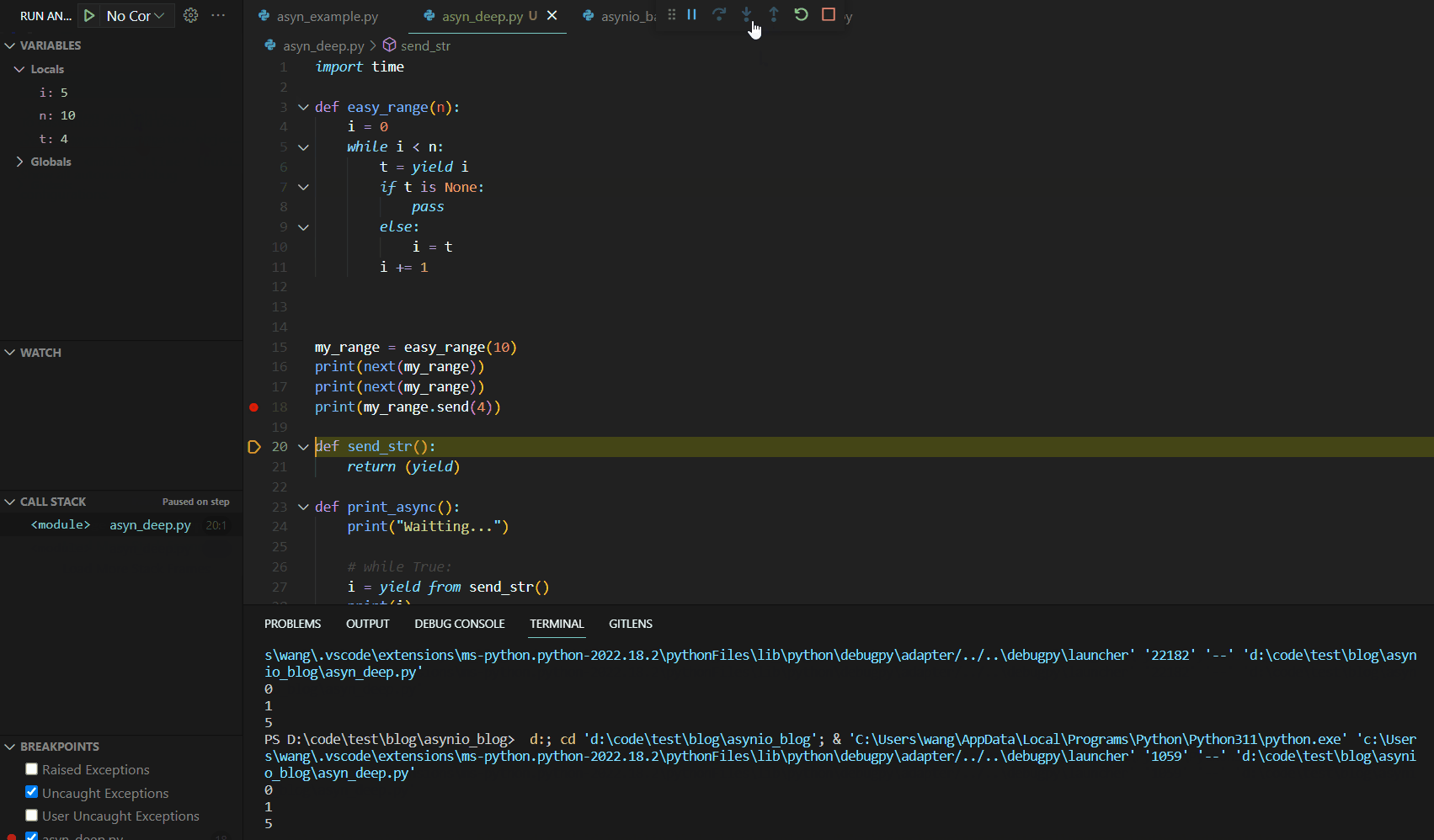
观察VARIABLES展示栏,我们发现此次将send中的数值4直接赋值给了t,然后继续运行相关代码,进行条件判断,运行至yield输出i结束。可见send可以实现简单的变量注入。
最后,我们介绍一个简单但功能强大的关键词yield from,代码例子如下:
def add_hello():
while True:
x = (yield)
return ("Hello " + x)
def writer_wrapper():
i = yield from add_hello()
i += " Hello"
return i
w = writer_wrapper()
next(w)
try:
print(w.send("World"))
except StopIteration as e:
print(e.value)
此处使用了一个神奇的关键词yield from,此关键词可以实现链式调用。我们可以将yield from将视为一个通道,可以将send的内容传递给add_hello(),然后将返回值赋值传递给writer_wrapper中的i,然后继续进行处理。
我们需要注意在send调用前next初始化。该函数的输出为:
Hello World Hello
该函数的Debug运行如下:
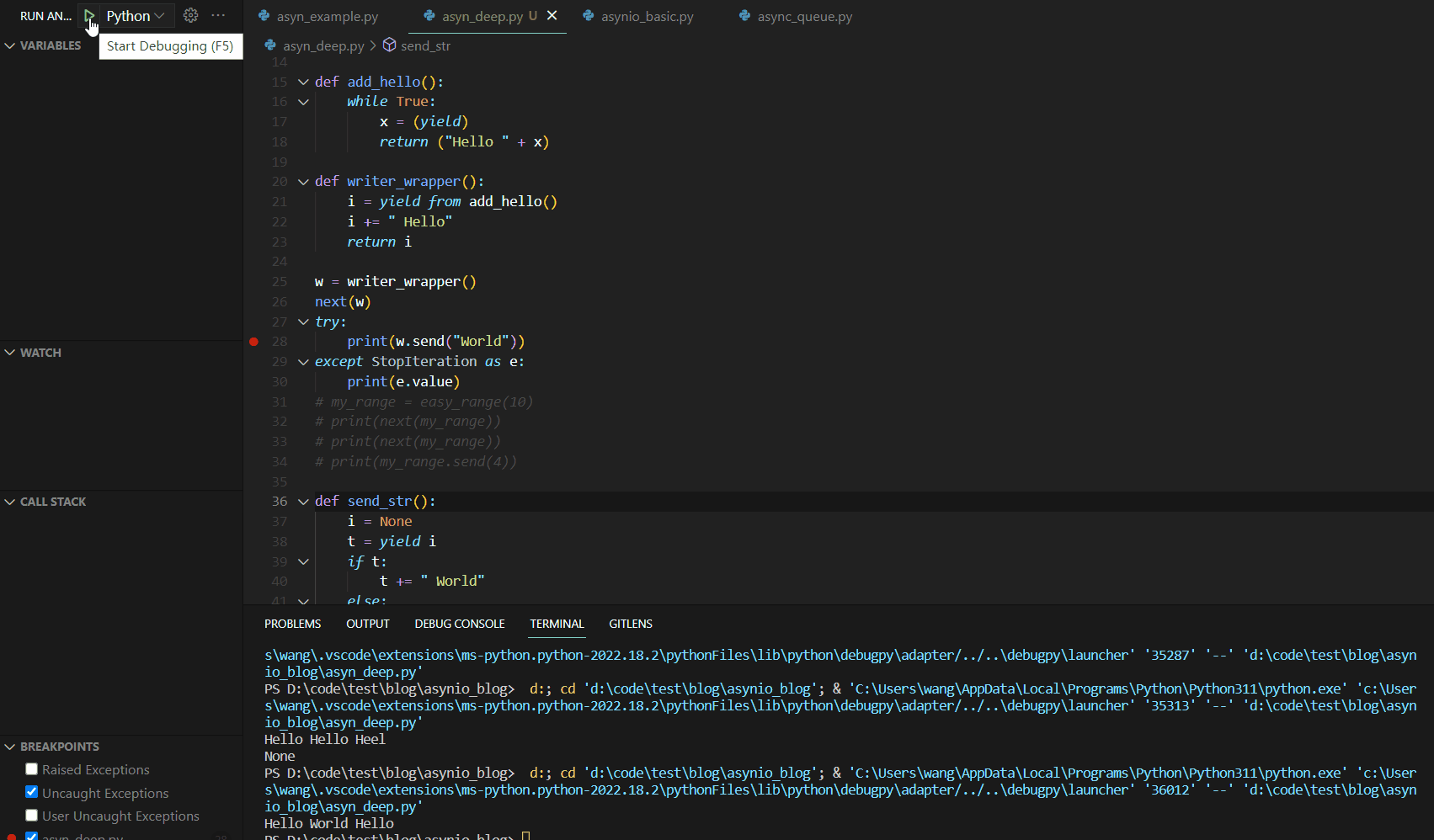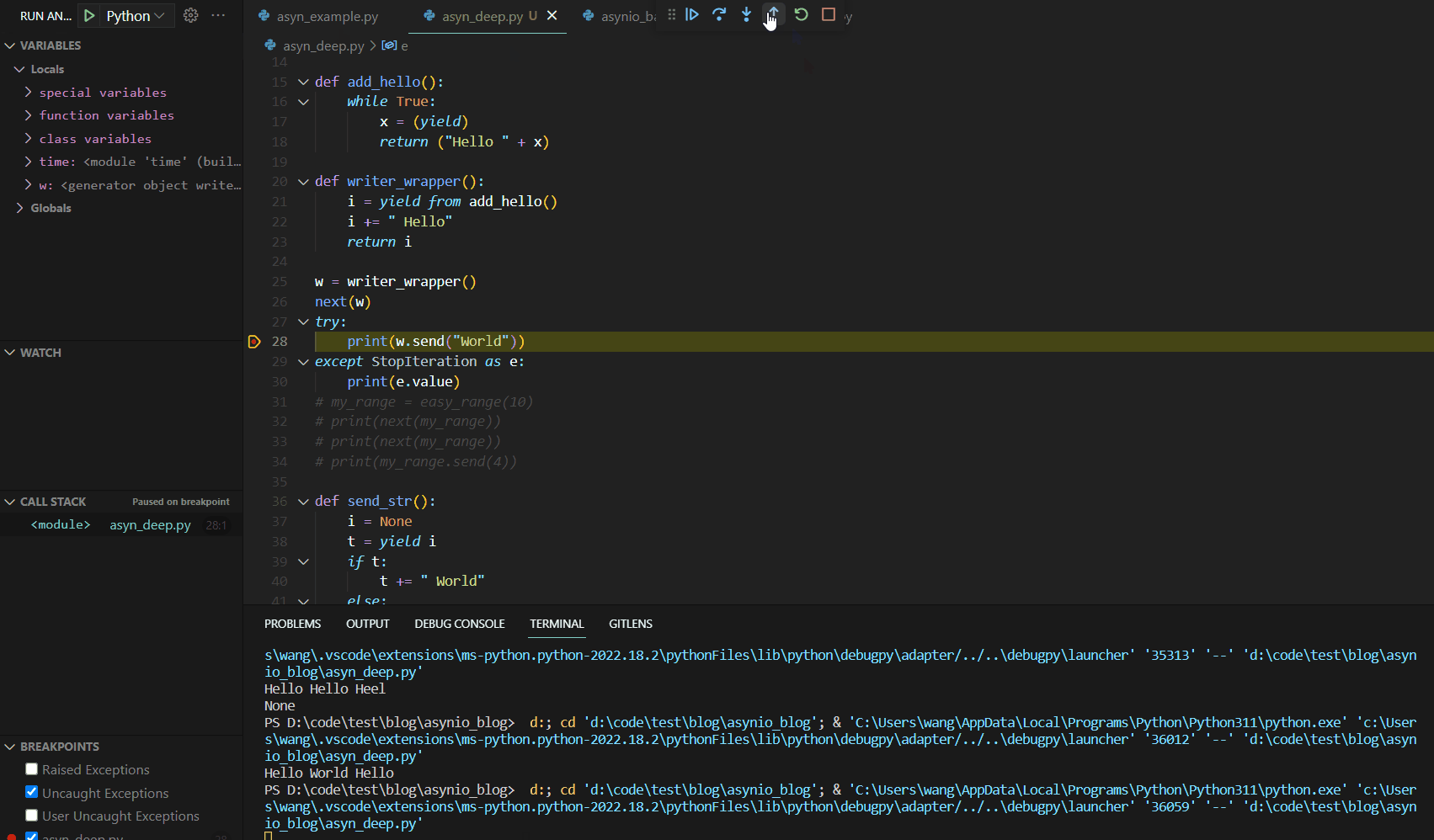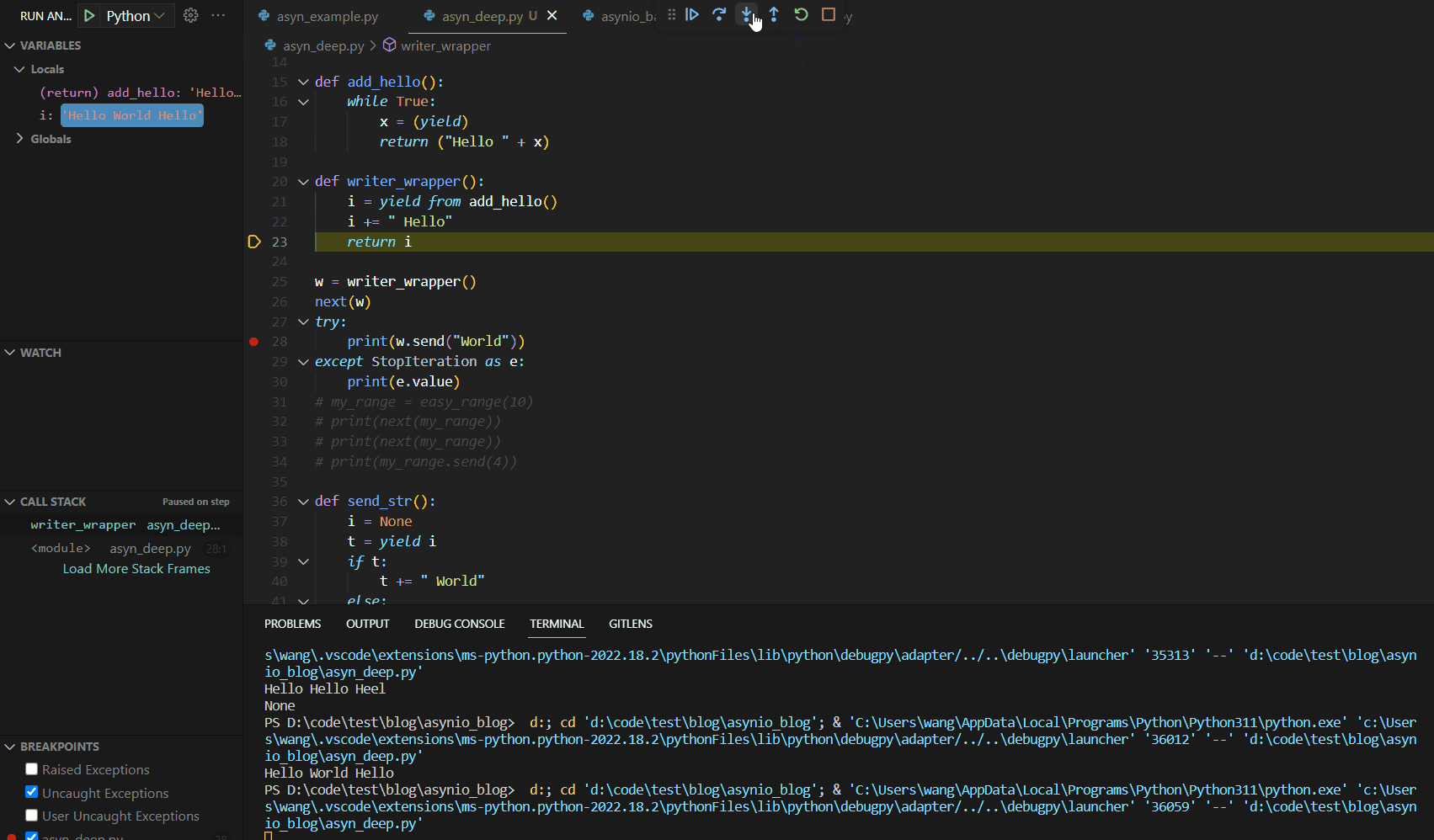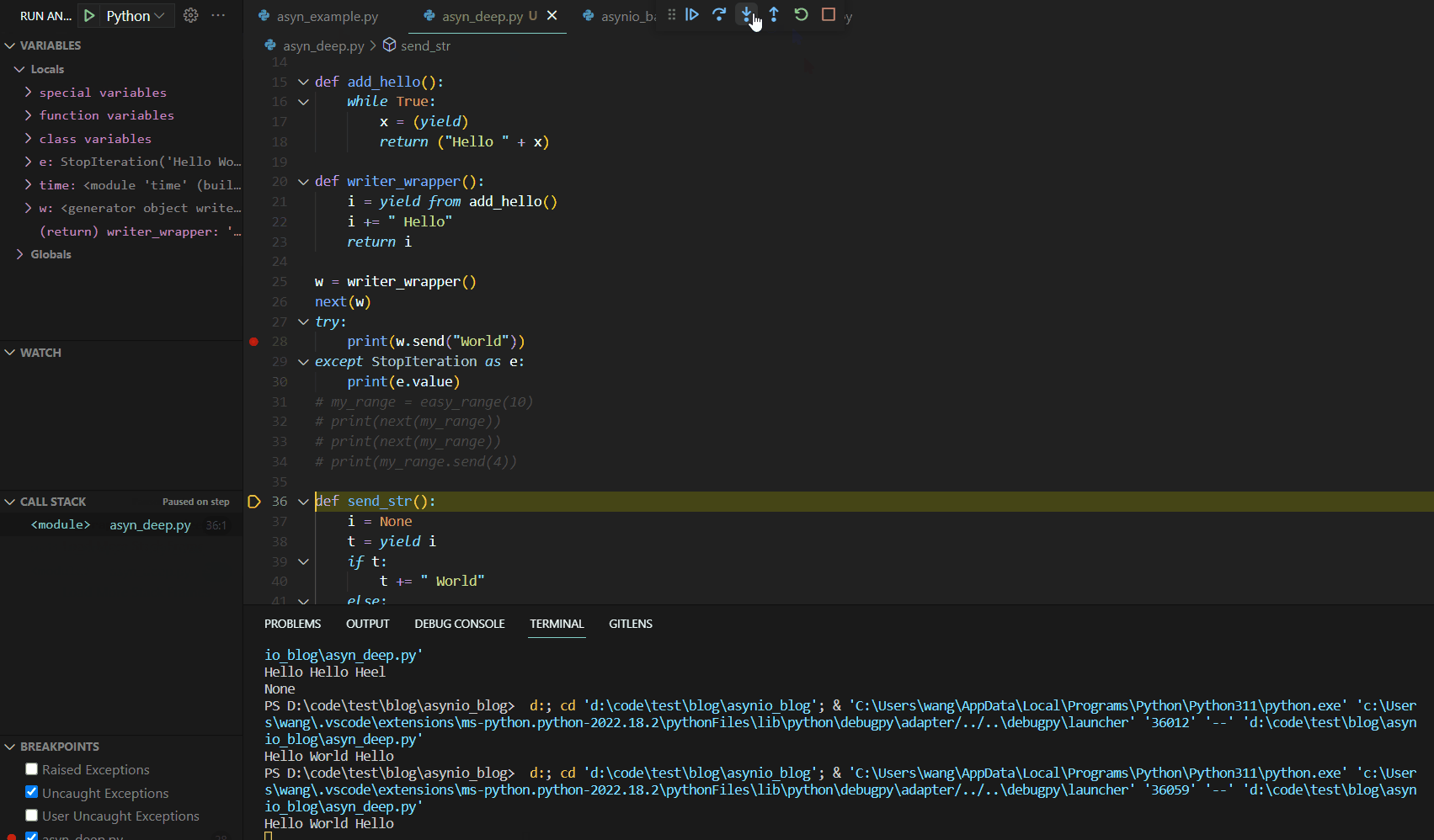
yield from关键词真正实现实现了await的功能。事实上,在早期的Python版本中,就是使用的yield from作为await使用。接下来,我们给出我们所介绍的第一个异步编程的yield版本,如下:
def async_sleep():
return (yield)
def async_print():
print("One")
while True:
yield from async_sleep()
print("Two")
task = [async_print() for _ in range(2)]
for i in task:
next(i)
time.sleep(1)
for i in task:
next(i)
我们在此处手动对async_print进行调度,第一个for循环用于初始化async_print函数,而第二个for循环用于启动剩余部分函数。而在asynio库中,其提供了一个较为特殊的部分event_loop事件循环,此循环将会跟踪目前文件内所有异步函数,并根据这些函数不同的状态进行next或send调用。我们之间使用asyncio.gather将函数注入event_loop,之后使用asyncio.run用于启动event_loop循环。
在此处,我们可以介绍为什么需要async/await关键词?正如上文所言,异步函数事实上就是生成器函数,但在编码过程中,我们可能会编写一些正常的生成器函数,为了辨别生成器函数与异步函数的不同,所以使用async/await用来标识异步函数。
读者可能发现
loop_event调度也会影响异步函数运行的速度,在这一方面,有部分开发者开发了一些更加高效的版本,比如uvloop等。但随着Python版本的提升,调度器的速度也在上升,如果读者追求极致速度,可以考虑提升Python版本。下图展示了uvloop的性能对比
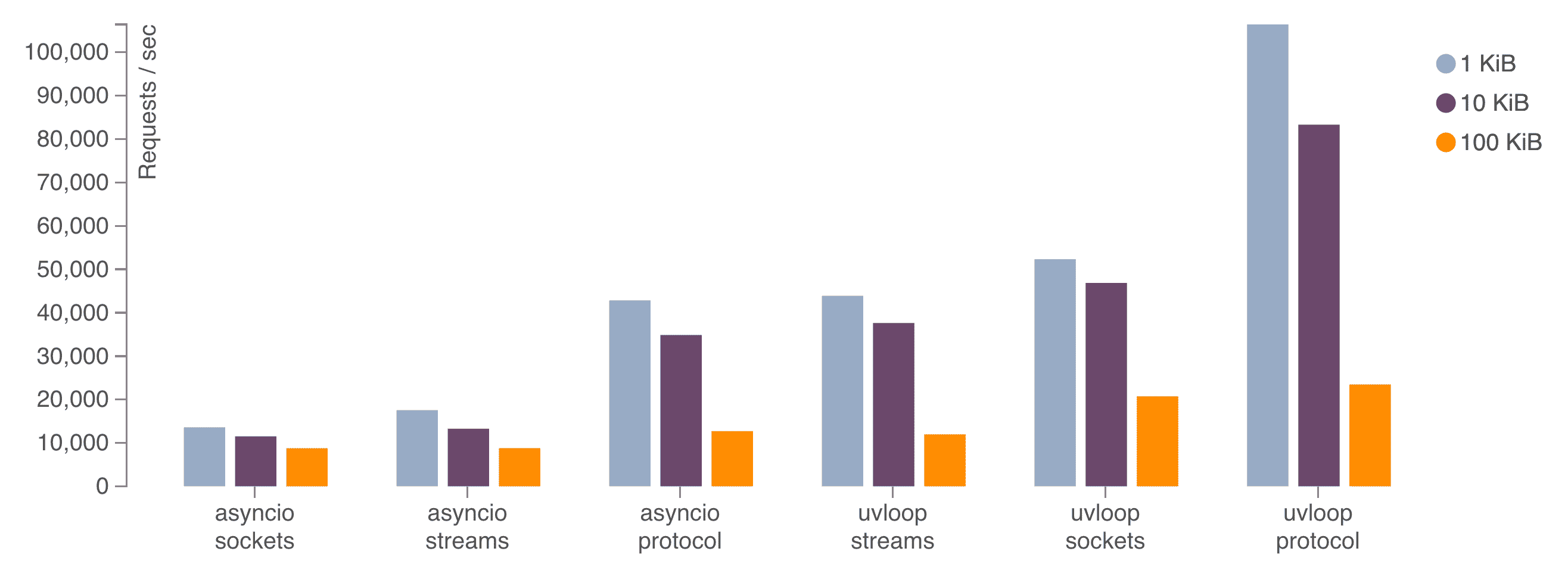
多线程与异步
对异步函数进行调度的loop_event一般会将所有异步函数运行在单个核心上,如果我们一次性启动太多异步函数可能导致出现“一核有难,八核围观”的滑稽现象。在Python中,多进程一般会将每个进程运行在单一的核心上,如果读者开启 4 进程,则意味着每个进程运行在一个核心上,即使用了 4 个核心(前提是您的CPU具有 4 个核心)。这意味着我们可以将异步嵌入在多线程中实现更高效的异步运行。值得注意的是Python的多进程不受GIL限制,这意味多进程对于计算密集型任务仍可提升效率。
由于Python多进程也是一个复杂的话题,我们仅在此处给出一个简单的示例和代码解释,如果读者对多线程这一话题感兴趣,我们可以在未来发布一篇关于此的文章。如果读者现在就想获得这方面的内容,我们建议读者阅读以下文档:
当然,Python文档给出的相关代码示例和解释并不足够初学者学习,读者可参考此网站内给出的详细内容。
笔者编写了一个适用于一般爬虫的多进程异步代码,如下:
import asyncio
import multiprocessing
import re
import time
from concurrent.futures import ProcessPoolExecutor, wait
from multiprocessing import Queue
import aiohttp
from aiohttp import ClientSession
def exact_link(html: str, pattern: re.Pattern):
return re.search(pattern, html).group(1)
def consumer(rx: Queue, pattern: re.Pattern):
while True:
html = rx.get()
if html is None:
break
title = exact_link(html, pattern)
print(title)
async def run_loop(tx: Queue, rx: Queue):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
'Accept-Language': 'en,en-US;q=0.8,zh-CN;q=0.7,zh;q=0.5,zh-TW;q=0.3,zh-HK;q=0.2',
}
async with ClientSession(headers=headers) as session:
while True:
task = tx.get_nowait()
fn, args = task
future_task = asyncio.create_task(fn(*args, session))
res = await future_task
rx.put_nowait(res)
def bootstrap(tx: Queue, rx: Queue):
asyncio.run(run_loop(tx, rx))
def consumer(rx: Queue, pattern: re.Pattern):
while True:
html = rx.get()
title = exact_link(html, pattern)
print(title)
def main():
pattern = re.compile(r"<title>(.*)</title>")
with open(r"test_data\url_list", "r", encoding="utf-8") as f:
url_list = f.readlines()
with multiprocessing.Manager() as manager:
tx, rx = manager.Queue(), manager.Queue()
for url in url_list:
task = fetch_url, (url,)
tx.put_nowait(task)
with ProcessPoolExecutor(max_workers=4) as executor:
producers = [executor.submit(bootstrap, tx, rx) for _ in range(2)]
consumers = [executor.submit(consumer, rx, pattern)]
wait(producers)
rx.put(None)
if __name__ == "__main__":
s = time.perf_counter()
main()
elapsed = time.perf_counter() - s
print(f"Code runtime: {elapsed}")
此代码属于多生产者单消费者的类型,我们启动了两个爬虫进程和一个数据提取进程。本程序设计受到了PyCon 2018上的一次报告的影响,但将大部分代码使用了较新的特性进行更正。此代码使用了tx作为任务队列,我们将需要异步执行的函数推入此队列,进入任一进程run_loop事件循环内进行异步运行调度。我们在代码最后将运行结果推送给了rx队列,此队列由consumer函数消费。
注意,在多进程代码中请尽可能不要使用
bs4库,因为bs4解析出的结构体是过于庞大的难以序列化的,容易导致出现栈溢出报错。
此代码读取了url_list中的数据作为爬虫的数据来源。读者可自行在此文件内填入一些网页的链接,此代码会在指定链接内爬取html标题内容。
此处我们需要向rx中推入消费者进程数量的None以关闭消费者进程,如此处我们仅开启了一个消费者,所以仅需要推入一个None即可。此处的None作为信号通知consumer函数中止运行。更多关于多进程的内容,读者可自行参考上文给出的链接,或等待笔者编写相关内容。
上述代码在笔者使用的 Python 3.11 内可正常运行,暂时未实验其他版本,如果读者发现问题,可通过邮件等方式与我联系
笔者简单测试了 5 个重复的 Python.org 链接,输出如下:
Welcome to Python.org
Welcome to Python.org
Welcome to Python.org
Welcome to Python.org
Welcome to Python.org
Code runtime: 1.1050703999353573
可见,通过多进程与异步的联合使用大幅提高了运行效率。
笔者不建议读者深入研究 Python 多进程机制等内容,这些内容在 Python 语言中仍属于前沿,且受制于 Python 自身性能问题,无法达到极致的速度,使用多进程API的体验并不好。读者考虑使用 go 语言来编写高性能爬虫,入门 go爬虫 可阅读笔者编写的Python2Go:将Python豆瓣爬虫使用Go重构。当然,此文章没有涉及 go 的并发部分。
总结
本文主要介绍了Python异步编程的相关内容,具体包括:
- 异步的基本使用和相关模型
- 异步的原理及实现
- 多线程与异步的结合
希望对读者编写IO密集型Python应用带来一定的启发。本文对应代码可在此Github仓库找到。