声明,本文译自 pandas with hundreds of millions of rows。 如果您的英语水平较好,可以阅读原文。为了译文更加流畅,译者补充了部分内容。
问题
我们希望获得国内航班平均延误最长的 5 个美国机场。
此处的国内航班指的是美国国内航班

数据
我们使用了来自 Harvard Dataverse 的 Data Expo 2009: Airline on time data 数据集。该数据集包含从 1987 年 10 月到 2008 年 4 月美国境内所以商业航班降落和起飞的详细数据。 这大约有 1.2 亿条数据,分为 22 个 CSV 文件,每个 CSV 文件内包含 1 年的数据,以及 4 个我们不会使用的辅助 CSV 文件。 数据集解压后占用了大约 13 GB 硬盘空间。 原始数据集是经过压缩的,但解压缩部分不属于我们此次数据处理的任务。
原始数据集大概占用 1.3 GB 空间,使用 zip 压缩格式。
该数据集也在 《数据科学R语言实践》 此书中使用过。
环境
我使用以下硬件配置完成此项任务:
- Intel(R) Core(TM) i7-8550U CPU @ 1.80GHz
- 内存: LPDDR3 15820512 kB (16 Gb) 2133 MT/s, 无 swap
- 硬盘: KXG50ZNV512G NVMe TOSHIBA 512GB(使用 ext4 分区格式且未进行加密)
- 系统: Linux 5.19.9 (Arch 发行版, 仅运行 KDE Plasma 和单个 Konsole 会话, 占用 610 Mb 内存)
本文使用的软件配置如下:
幼稚方法
解决这一问题最简单的方法是直接使用 pandas 载入数据,代码如下:
import pandas
df = pandas.concat((pandas.read_csv(f'{year}.csv') for year in range(1987, 2009)))
不幸的是,该方案会引发 MemoryError (如果您使用 Jupyter 的话,此代码会导致内核重启)。 如果您的计算机存在大量内存,则不会出现此问题。 本文的其他部分将介绍一系列其他方式,使读者可以简单高效的完成此数据分析任务。
纯粹 Python 的方法
考虑到我们问题的特殊性,我们不需要将所有数据导入到内存中以计算每个机场的平均延迟。 我们可以读取数据行然后累加所需要的数据,即航班延迟和机场名称,然后丢弃此数据行。 当完成对所有数据行的读取后,我们获得了累加后的航班延迟,简单的与航班数量相除,我们就可以获得作为分析目标的平均值。
一个简单的实现如下:
import csv
import datetime
import heapq
import operator
USE_COLS = 'Origin', 'Year', 'Month', 'DayofMonth', 'CRSDepTime', 'DepTime'
airports = {}
for year in rage(1987, 2009):
with open(f'../data/{year}.csv', errors='ignore') as f:
reader = csv.reader(f)
header = {name: position
for position, name
in enumerate(next(reader))
if name in USE_COLS}
for row in reader:
if row[header['CRSDepTime']] == 'NA' or row[header['DepTime']] == 'NA':
continue
year, month, day = (int(row[header['Year']]),
int(row[header['Month']]),
int(row[header['DayofMonth']]))
try:
scheduled_dep = datetime.datetime(year, month, day,
int(row[header['CRSDepTime']][:-2] or '0'),
int(row[header['CRSDepTime']][-2:]))
actual_dep = datetime.datetime(year, month, day,
int(row[header['DepTime']][:-2] or '0'),
int(row[header['DepTime']][-2:]))
except ValueError:
continue
delay = (actual_dep - scheduled_dep).total_seconds() / 3600.
if delay < -2.:
delay = 24. - delay
if row[header['Origin']] not in airports:
airports[row[header['Origin']]] = [1, delay]
else:
airports[row[header['Origin']]][0] += 1
airports[row[header['Origin']]][1] += delay
print(dict(heapq.nlargest(5,
((airport, total_delay / count) for airport, (count, total_delay) in airports.items()),
operator.itemgetter(1))))
可能部分读者对此处使用的部分函数不熟悉,此处给出各函数的文档地址: csv.reader 、 enumerate 、 heapq.nlargest 、 operator.itemgetter
请注意上述方法成立的前提是我们对均值而不是中位数感兴趣,如果希望获得中位数,我们需要更加复杂的方法,而且不能丢弃行数据中的 延迟数据(此处的延迟数据指航班延迟数据)。
通过上述方法,我们解决了内存问题,因为我们仅在内存中保留非常有限的信息,运行此代码不会占用超过 1 Mb 的内存。
修改后的代码运行时长为 7 分钟。
PyPy
CPython (当我们运行 python <our-program> 时使用的 Python 解释器) 是非常高效的,但是该解释器使用了许多魔法使我们的代码更具可读性,并使程序员不关注于运行的内部细节。
PyPy 是 Python 代码的另一种解释器,它使用了即时编译技术(JIT)。这种运行方式与 CPython 不同,对于某些任务而言更加高效。
在 PyPy 中运行上述代码会消耗大约 40 Mb 内存,但运行时间缩短为 4 分 40 秒。与 CPython 相比,运行时间缩短了大约三分之一。
pandas
回到 pandas 的世界,当我们数据很大时,我们几乎没有办法有效节约内存和时间,我们需要尽可能提高性能。
在这种特殊情况下,我们可以使用以下技巧:
- 仅加载所需要的列
- 指定列的数据类型,并使用最高效的数据类型
- 确保永远不要让 Python 解释器运行循环,选择使用 pandas 的循环方法(如
DataFrame.apply) - 避免数据复制(
DataFrame.copy等) - 仅早过滤数据,并且尽快释放对未使用数据结构(如
DataFrame、Series等)的占用
一个可行的解决 MemoryError 问题的代码如下:
import pandas
LOAD_COLS = 'Origin', 'Year', 'Month', 'DayofMonth', 'CRSDepTime', 'DepTime'
df = pandas.concat((pandas.read_csv(f'../data/{fname}.csv',
usecols=LOAD_COLS,
encoding_errors='ignore',
dtype={'Origin': 'category',
'Year': 'uint16',
'Month': 'uint8',
'DayofMonth': 'uint8',
'CRSDepTime': 'uint16',
'DepTime': 'UInt16'})
for fname
in range(1987, 2009)),
ignore_index=True)
date = pandas.to_datetime(df[['Year', 'Month', 'DayofMonth']].rename(columns={'DayofMonth': 'Day'}))
df['scheduled_dep'] = date + pandas.to_timedelta((df['CRSDepTime'] // 100) * 60 + (df['CRSDepTime'] % 100),
unit='minutes')
df['actual_dep'] = date + pandas.to_timedelta((df['DepTime'] // 100) * 60 + (df['DepTime'] % 100),
unit='minutes')
del date
df = df[['Origin', 'scheduled_dep', 'actual_dep']]
df['delay'] = (df['actual_dep'] - df['scheduled_dep']).dt.total_seconds() / 60 / 60
df['delay'] = df['delay'].where(df['delay'] > - 2, 24 - df['delay'])
print(df.groupby('Origin')['delay'].mean().sort_values(ascending=False).head(5))
该代码会在大约 2 分 45 秒内完成任务,这大约是 PyPy 耗时的 60% 。在此解决方案下,pandas 需要将所有数据加载到内存中,内存占用的峰值为 8.1 Gb (该峰值出现在 pandas.concat 操作中)。
在此解决方案中,我们将数据分析任务分成了两部分。 第一部分是将数据加载到内存中,第二部分是转换数据以获得我们需要的数据。 值得分析这两个部分运行的所需要的时间,因为获得执行时间后,我们可以更好地优化耗时部分。
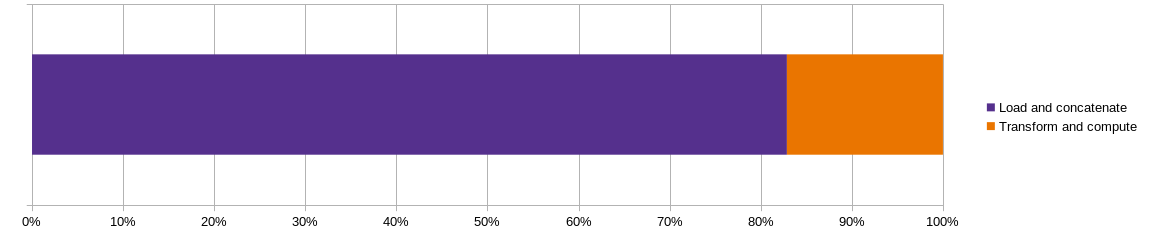
我们可以看到超过 80% 时间用于完成数据加载任务,即从 CSV 内导入数据和数据格式转换。我们会在下一节优化这一流程。
pandas 与 PyArrow
pandas 支持多个从 CSV 文件(或其他格式)导入数据的引擎。事实上, pandas.read_csv 有三种不同实现,但它们被包装在一个带有参数的函数中,我们可以通过指定参数来使用不同的数据导入引擎。 read_csv 的实现大致如下:
def read_csv(fname, engine='c'):
if engine == 'c':
return read_csv_with_pandas_implementation_in_c(fname)
elif engine == 'python':
return read_csv_with_pandas_implementation_in_python(fname)
elif engine == 'pyarrow':
return pyarrow.read_csv(fname).to_pandas()
else:
raise ValueError
read_csv 的 python 导入引擎速度最慢,我们应尽可能避免使用此引擎。而 PyArrow 实现有更好的性能表现,使用此引擎需要我们安装 PyArrow 库(使用 mamba install pyarrow),并在调用 read_csv 时使用 engine='pyarrow' 参数。
此处作者使用的
mamba是一种类似conda包管理器,具体可以参考 mamba 的 文档
使用 PyArrow 引擎导入数据,上述代码的运行时长约为 1 分 10 秒,这不到原始代码耗时的一半(约为 42%)。 内存峰值占用相同,因为内存占用的峰值发生在 pandas.concat 操作上,该操作没有使用 PyArrow 引擎。
PyArrow 实现使用了多线程,并且能够在导入数据时充分利用 CPU 核心。但此处并没有出现 8 倍加速(我的笔记本拥有 8 个核心)的效果,可能应为性能瓶颈出现在硬盘性能上。
我们使用的 NVMe 硬盘比机械硬盘读取速度快得多。我猜测在机械硬盘中使用此代码可能不会产生如此快的加速效果。如果读者使用机械硬盘储存数据,可以考虑进一步采用其他技术,比如进行数据压缩,并在读取后在内存中解压缩。此操作可以减少硬盘读取速度对数据导入的影响,但具体操作方法取决于读者使用的环境。
PyArrow
我们可以通过直接使用 PyArrow 来解决这一数据分析问题。 加载数据后执行数据分析的代码与上文相同,但数据集的加载使用以下代码:
import pyarrow
import pyarrow.csv
COLUMN_TYPES = {'Origin': pyarrow.dictionary(pyarrow.int32(),
pyarrow.string()),
'Year': pyarrow.uint16(),
'Month': pyarrow.uint8(),
'DayofMonth': pyarrow.uint8(),
'CRSDepTime': pyarrow.uint16(),
'DepTime': pyarrow.uint16()}
tables = []
for year in range(1987, 2009):
tables.append(pyarrow.csv.read_csv(
f'../data/{year}.csv',
convert_options=pyarrow.csv.ConvertOptions(
include_columns=COLUMN_TYPES,
column_types=COLUMN_TYPES)))
df = pyarrow.concat_tables(tables).to_pandas()
该解决方案大约需要 50 秒,是使用 Pandas 所需要时间的 70% ,且峰值内存占用为 7.5 Gb,约为 pandas 解决方案所需内存的 93%
无论是直接使用 PyArrow 导入数据还是使用 PyArrow 引擎的 Pandas 导入数据,读取 CSV 文件的时间大致相同。两者实现的主要区别是数据集读取后的拼接。 PyArrow 实现是连接 Arrow 表格,这是一种经过优化的数据结构。而 Pandas 的 pd.concat 函数本质上是拼接 Numpy 数组,相比高效的 Arrow 表格,效率较低。
按年分割使用 PyArrow
之前给出的方法看起来相当不错,但需要占用 7.5 Gb 内存。我们是否可以做得更好? 在最开始的纯 Python 和 PyPy 实现中,我们使用了一种不需要将全部数据集导入到内存中的方法。我们可以考虑修正之前的方案,将使用 PyArrow 导入数据,并使用 pandas 进行数据分析。
详细来说,我们按年读取数据,读取后对各个机场的航班数量和航班延误进行累加。在处理完所有年份后,我们将各年的数据再进行累加,然后使用总延误除以总航班数量获得平均延迟。
这是一个类似 MapReduce 的过程。对各年数据的计算为 map 流程,而最终计算各机场航班延误平均值属于 Reduce 过程。
此方案的具体实现如下:
import functools
import pyarrow
import pyarrow.csv
import pandas
COLUMN_TYPES = {'Origin': pyarrow.dictionary(pyarrow.int32(),
pyarrow.string()),
'Year': pyarrow.uint16(),
'Month': pyarrow.uint8(),
'DayofMonth': pyarrow.uint8(),
'CRSDepTime': pyarrow.uint16(),
'DepTime': pyarrow.uint16()}
results = []
for year in range(1987, 2009):
df = pyarrow.csv.read_csv(
f'../data/{year}.csv',
convert_options=pyarrow.csv.ConvertOptions(
include_columns=COLUMN_TYPES,
column_types=COLUMN_TYPES)).to_pandas()
date = pandas.to_datetime(df[['Year', 'Month', 'DayofMonth']].rename(columns={'DayofMonth': 'Day'}))
df['scheduled_dep'] = date + pandas.to_timedelta((df['CRSDepTime'] // 100) * 60 + (df['CRSDepTime'] % 100),
unit='minutes')
df['actual_dep'] = date + pandas.to_timedelta((df['DepTime'] // 100) * 60 + (df['DepTime'] % 100),
unit='minutes')
df = df[['Origin', 'scheduled_dep', 'actual_dep']]
df['delay'] = (df['actual_dep'] - df['scheduled_dep']).dt.total_seconds() / 60 / 60
df['delay'] = df['delay'].where(df['delay'] > - 2, 24 - df['delay'])
results.append(df.groupby('Origin')['delay'].agg(['sum', 'count']))
df = functools.reduce(lambda x, y: x.add(y, fill_value=0), results)
df['mean'] = df['sum'] / df['count']
print(df['mean'].sort_values(ascending=False).head(5))
此方案速度更快,大约需要 37 秒,大约是一次载入所有数据集的方案所耗时间的 74% 。读取文件所占的时间应该相同,但计算操作部分应该较之前的方案更快,因为同时处理所有数据会产生 协同作用 。更加重要的区别是,我们不再需要执行数据集合并工作(即 pd.concat ),数据集合并是一个需要大量内存分配和数据移动的工作,浙西都是较为缓慢的。
正如我们的预期,峰值内存消耗较低,因为我们不需要一次导入所有数据。内存占用的峰值为 900 Mb,这大约相当于一次载入所有数据方案内存占用的 12% ,显然该数据取决于您的数据集分割情况。
按年分割使用多进程 pandas
在最后一个方案中,我将再次使用 pandas 且使用默认的使用 c 引擎驱动的 read_csv 函数。我们已经看到 PyArrow 高效的原因是 PyArrow 可以充分利用 CPU 核心,而 pandas 仅会使用单个 CPU 核心。在上一个实例中,我们看到了一次仅处理一个 CSV 文件提高了内存效率且速度更快,在本方案中,我们仍使用相同的方法,但会进行并行处理。
该方案仅是为了说明多进程,我一般不推荐使用此方法解决问题。我们将使用 Python 的 multiprocessing 模块以及 Pool 。 Pool 会根据当前 CPU 的核心数来分配进程,默认情况下进程数与 CPU 核心数一致。除此外,其他代码与上文基本相同。
import functools
import multiprocessing
import pandas
LOAD_COLS = 'Origin', 'Year', 'Month', 'DayofMonth', 'CRSDepTime', 'DepTime'
def read_one_csv(year):
df = pandas.read_csv(f'../data/{year}.csv',
engine='c',
usecols=LOAD_COLS,
encoding_errors='ignore',
dtype={'Origin': 'category',
'Year': 'uint16',
'Month': 'uint8',
'DayofMonth': 'uint8',
'CRSDepTime': 'uint16',
'DepTime': 'UInt16'})
date = pandas.to_datetime(df[['Year', 'Month', 'DayofMonth']].rename(columns={'DayofMonth': 'Day'}))
df['scheduled_dep'] = date + pandas.to_timedelta((df['CRSDepTime'] // 100) * 60 + (df['CRSDepTime'] % 100),
unit='minutes')
df['actual_dep'] = date + pandas.to_timedelta((df['DepTime'] // 100) * 60 + (df['DepTime'] % 100),
unit='minutes')
df = df[['Origin', 'scheduled_dep', 'actual_dep']]
df['delay'] = (df['actual_dep'] - df['scheduled_dep']).dt.total_seconds() / 60 / 60
df['delay'] = df['delay'].where(df['delay'] > - 2, 24 - df['delay'])
return df.groupby('Origin')['delay'].agg(['sum', 'count'])
pool = multiprocessing.Pool()
df = functools.reduce(lambda x, y: x.add(y, fill_value=0),
pool.map(read_one_csv, range(1987, 2009)))
df['mean'] = df['sum'] / df['count']
print(df['mean'].sort_values(ascending=False).head(5))
这段代码大约运行了 53 秒,这相当于使用 c 引擎原始 Pandas 代码所费时间的三分之一,但是比使用 PyArrow 等效实现慢得多。如果 CPU 是瓶颈,代码运行速度应该是原有代码速度的 8 倍(假设 CSV 文件具有相同的大小,并且多进程的开销并不大)。但正如预期,硬盘可能是瓶颈,并且多于 3 个 CPU 的核心可能对性能没有提升(当有三个进程时,时间延长为 66 秒)
在这种情况下,内存使用情况的分析更加复制,每个进程都在内存堆内分配自己的空间。内存中没有一个峰值,而是每个进程都一个内存峰值,这些峰值可能发生在不同的时间,也却取决于不同的因素。每个进程在其峰值都占用大约 400 Mb 的内存。在最好的情况下,每个进程达到峰值的时间不同,该代码可能仅占用 400 Mb 内存。在最坏的情况下,所有峰值同时发生,我们将占用 3.2 Gb 内存。
总结
本文从最开始的内存不足而无法进行数据处理任务开始,到最终在合理的时间和内存占用要求下解决任务。
我们所有的代码都是使用 Python 完成,在所有解决方案中,我们的代码都是较短且不复杂的。我们也看到在某些情况下,我们可以通过修改代码中微小部分带来巨大的效率提升(比如使用 PyArrow 而不是 c 驱动的 read_csv 函数)。在其他情况下,我们可能大幅度修改了代码,但这些修改也没有触及根本逻辑,且带来了性能提升。
有很多方法可以使我们的代码运行速度更快且内存占用更少,此处展示的方案仅占其中的一小部分。我们只考虑吧了基于 Python 和 pandas 的选项,但是我们有更多其他的选择:
- 使用其他编程语言,如 R、Julia、Rust或者 C++
- 使用 pandas 的替代品,如 Vaex 或 Polars
- 使用其他数据格式,如 Parquet、HDF或 ORC
- 使用集群而不是单机进行数据分析任务,如 Dask、Modin 或 Koalas
- 使用带有其他 JIT 的 Python 实现,如 Bodo 或 Numba
也许还有其他许多合理的选项,我可能会在未来的博客中涉及其中一部分选项。
最后,我们给出总结图表:
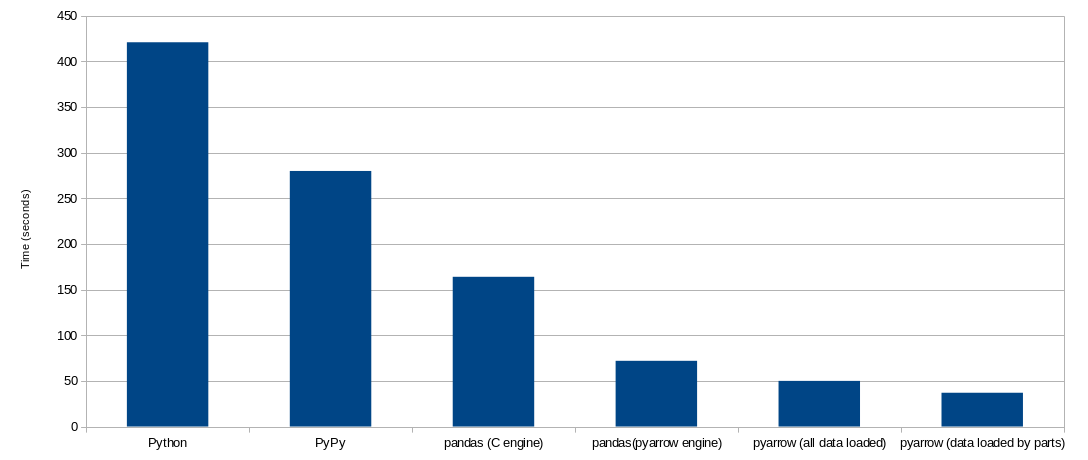
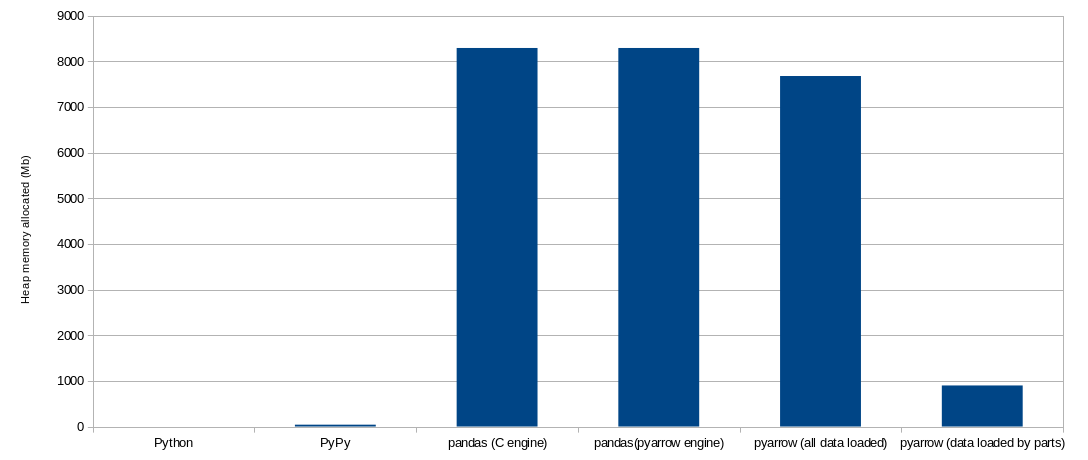
延伸阅读
如果您准备从密歇根州的马斯基根县机场(Muskegon County Airport, MKG) 起飞,我建议您带上一本好书,因为您可能要待机 6 小时。如果您喜欢这一篇博客,我推荐您阅读 High Performance Python。该书提供了许多关于提高 Python 代码性能的信息,且阅读起来也令人愉悦。
您还可能对我在 PyData London 2018 上的 Demystifying pandas internals演讲感兴趣。该演讲提供了更多关于 Python 和 pandas 的对比。